一种基于词的短文本摘要抽取方法与流程
1.本发明属于nlp领域下文本摘要抽取技术领域,具体为一种基于词的短文本摘要抽取方法。
背景技术:
2.文本摘要的目标是将长文本进行压缩、归纳和总结,从而形成具有概括性含义的短文本。根据文档个数的不同,文本摘要任务可以分为单文档摘要和多文档摘要,根据摘要方法的不同,文本摘要可分为抽取式(extractive)和生成式(abstractive)两大类,前者直接从原文中抽取文本组成摘要,后者则是一词接一词地生成摘要,相比较而言,抽取式的方法由于方法本身的固有特点,有时无法简洁连贯地概括原文的内容。
技术实现要素:
3.本发明的目的在于提供一种基于词的短文本摘要抽取方法,以解决上述背景技术中提出的问题。
4.为了实现上述目的,本发明提供如下技术方案:一种基于词的短文本摘要抽取方法,包括抽取模型和词序模型,所述词序模型步骤如下:
5.第一步:数据标注一;
6.s1.1:选择电销场景下50万对话短文本数据,人工审核纠正每句话的词语顺序;
7.s1.2:使用jieba分词,原始词语顺序的标签为1,然后对每一句话都枚举所有的词语组合,标签为0,最后人工审核纠正所有的标签数据;
8.第二步:数据预处理一;
9.第三步:模型构建一,将高位数据降维到2维;
10.第四步:模型评估一;
11.s4.1:训练过程中,每当训练集跑完100个batch,都跑一次验证集,对验证集的预测标签和真实标签计算f1-score和loss;
12.s4.2:当f1-score在10个batch之后都不提升的时候,就提前结束模型训练,这时候认为保存的最后一版模型为最优的模型,用最优的模型跑测试集数据,计算f1-score,当前的f1-score值就是对模型的评分;
13.所述抽取模型步骤如下:
14.第一步:数据标注二,选择电销场景下20万对话短文本数据,根据原文内容人工总结出简洁的摘要文本;
15.第二步:数据预处理二;
16.第三步:模型构建二,使用膨胀系数按照1、2、4、1顺序设定的膨胀卷积神经网络捕捉数据信息;
17.第四步:模型评估二;
18.s4.1:设置一个阈值来判断当前词是否为抽取的摘要内容,若评分大于阈值,则认
为该词被抽取出来,否则则抛弃;
19.s4.2:把所有大于阈值的词,穷举出所有的组合输入到词序模型中,取评分最高的词序列按顺序拼接起来作为摘要;
20.s4.3:摘要和原文做rouge评分,用所有的rouge评分的平均值评估当前模型的好坏,rouge评分越接近于1越好。
21.优选的,所述数据预处理一具体步骤如下:
22.第一步:构建词典,把所有的训练集分词去重后的词做为词典;
23.第二步:统一文本维度,使用<pad>符号把所有的文本都padding成统一的max_length维度,这里选择训练集中最多的词语个数做为max_length;
24.第三步:根据词典把训练数据表示成索引,循环遍历每句文本,从词典中查找是否存在,若存在,则获取词典中的索引,否则获取<unk>的索引,<unk>表示所有的未登录词;
25.第四步:生成数据迭代器,把数据分为多个批次送入到模型中去训练,每个批次的数据个数为64,生成迭代器的过程中,同时把数据添加到gpu中。
26.优选的,所述模型构建一网络结构如下:
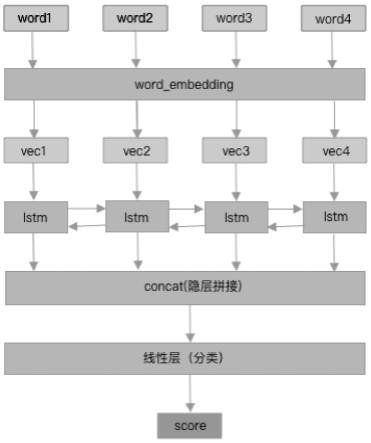
27.第一层:embedding
28.第二层:bilstm()
29.第三层:linear();
30.embedding是向量表示层,第二层是双向长短时记忆神经网络bilstm,linear()是线性层。
31.优选的,所述数据预处理二的具体步骤如下:
32.第一步:在原文中查找人工摘要词语索引,首先分别对摘要和原文进行jieba分词,然后根据滑窗式方法查到摘要所在原文中的中心位置,从中心位置向两侧匹配摘要,匹配成功后则记为1,否则记为0,最终会生成每句原文对应的摘要标签;
33.第二步:构建词典和embedding,选择腾讯词向量词典的前20万个词语和训练集与腾讯词向量词典去重后的词组成词典,对于训练集中的词,若出现在腾讯词向量词典中,则选择其中的词向量,否则,则随机初始化为200维词向量;
34.第三步:统一文本维度,分词后,使用<pad>符号把所有的文本都padding成统一的max_length维度,这里选择训练集中最多的词语个数作为max_length;
35.第四步:生成数据迭代器。对于深度学习来说,需要把数据分为多个批次送入到模型中去训练,每个批次的数据个数为32,在生成迭代器的过程中,同时把数据添加到gpu中。
36.优选的,所述模型构建二网络结构如下:
37.第一层:embedding
38.第二层:linear()
39.第三层:dropout(0.5)
40.第四层:dcnn(dilation_rate=1)
41.第五层:dropout(0.5)
42.第六层:dcnn(dilation_rate=2)
43.第七层:dropout(0.5)
44.第八层:dcnn(dilation_rate=4)
45.第九层:dropout(0.5)
46.第十层:dcnn(dilation_rate=1)
47.第十一层:dropout(0.5)
48.第十二层:linear()
49.第十三层:sigmoid();
50.embedding是向量表示层;linear()是全连接层,dropout为失活层,dropout为失活层,这里随机选择50%的网络节点失活,每一层的dcnn后都接一个失活层;dcnn为膨胀卷积神经网络,dilation_rate为膨胀率。
51.本发明的有益效果如下:
52.本发明通过抽取模型网络结构中使用膨胀卷积神经网络(dilatedconvolution neural network,dcnn),且膨胀系数按照1、2、4、1的顺序设定,使模型能够尽可能多的捕捉文本信息,并增加了一个词序模型,提高了摘要的有效性和连续性,从而完美解决了抽取式摘要的不连贯问题。
附图说明
53.图1为本发明结构词序模型网络结构示意图;
54.图2为本发明结构抽取模型网络结构示意图。
具体实施方式
55.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
56.如图1至图2所示,本发明实施例提供了一种基于词的短文本摘要抽取方法,包括抽取模型和词序模型,词序模型步骤如下:
57.第一步:数据标注一;
58.s1.1:选择电销场景下50万对话短文本数据,人工审核纠正每句话的词语顺序;
59.s1.2:使用jieba分词,原始词语顺序的标签为1,然后对每一句话都枚举所有的词语组合,标签为0,最后人工审核纠正所有的标签数据;
60.第二步:数据预处理一;
61.第三步:模型构建一,将高位数据降维到2维;
62.第四步:模型评估一;
63.s4.1:训练过程中,每当训练集跑完100个batch,都跑一次验证集,对验证集的预测标签和真实标签计算f1-score和loss;
64.s4.2:当f1-score在10个batch之后都不提升的时候,就提前结束模型训练,这时候认为保存的最后一版模型为最优的模型,用最优的模型跑测试集数据,计算f1-score,当前的f1-score值就是对模型的评分;
65.抽取模型步骤如下:
66.第一步:数据标注二,选择电销场景下20万对话短文本数据,根据原文内容人工总结出简洁的摘要文本;
67.第二步:数据预处理二;
68.第三步:模型构建二,使用膨胀系数按照1、2、4、1顺序设定的膨胀卷积神经网络捕捉数据信息;
69.第四步:模型评估二;
70.s4.1:设置一个阈值来判断当前词是否为抽取的摘要内容,若评分大于阈值,则认为该词被抽取出来,否则则抛弃;
71.s4.2:把所有大于阈值的词,穷举出所有的组合输入到词序模型中,取评分最高的词序列按顺序拼接起来作为摘要;
72.s4.3:摘要和原文做rouge评分,用所有的rouge评分的平均值评估当前模型的好坏,rouge评分越接近于1越好;
73.通过,数据标注二的标注结果为两列数据,一列文本,一列标注摘要(如下表所示);
[0074][0075]
并通过抽取模型网络结构中使用膨胀卷积神经网络(dilated convolutionneural network,dcnn),且使用不同的膨胀率,使模型能够尽可能多的捕捉文本信息,词序模型是一个双向长短时记忆神经网络(bi-directional longshort-term memory,lstm)模型,主要作用是对进入模型的序列进行打分,分数越高,词序顺序越好,句子也就越连贯,最后选择一个评分最高的词语组合做为当前文本的摘要,从而完美解决了抽取式摘要的不连贯问题。
[0076]
其中,数据预处理一具体步骤如下:
[0077]
第一步:构建词典,把所有的训练集分词去重后的词做为词典;
[0078]
第二步:统一文本维度,使用<pad>符号把所有的文本都padding成统一的max_length维度,这里选择训练集中最多的词语个数做为max_length。
[0079]
第三步:根据词典把训练数据表示成索引,循环遍历每句文本,从词典中查找是否存在,若存在,则获取词典中的索引,否则获取<unk>的索引,<unk>表示所有的未登录词;
[0080]
第四步:生成数据迭代器,把数据分为多个批次送入到模型中去训练,每个批次的数据个数为64,生成迭代器的过程中,同时把数据添加到gpu中;
[0081]
通过,把数据添加到gpu中,达到加速的效果。
[0082]
其中,模型构建一网络结构如下:
[0083]
第一层:embedding
[0084]
第二层:bilstm()
[0085]
第三层:linear();
[0086]
embedding是向量表示层,第二层是双向长短时记忆神经网络bilstm,linear()是线性层;
[0087]
通过,网络结构(见图1)中,embedding是向量表示层;第二层是双向长短时记忆神经网络bilstm,可以捕获到较长距离的词语之间的依赖关系,并通过linear()把高维数据降维到2维。
[0088]
其中,数据预处理二的具体步骤如下:
[0089]
第一步:在原文中查找人工摘要词语索引,首先分别对摘要和原文进行jieba分词,然后根据滑窗式方法查到摘要所在原文中的中心位置,从中心位置向两侧匹配摘要,匹配成功后则记为1,否则记为0,最终会生成每句原文对应的摘要标签;
[0090]
第二步:构建词典和embedding,选择腾讯词向量词典的前20万个词语和训练集与腾讯词向量词典去重后的词组成词典,对于训练集中的词,若出现在腾讯词向量词典中,则选择其中的词向量,否则,则随机初始化为200维词向量;
[0091]
第三步:统一文本维度,分词后,使用<pad>符号把所有的文本都padding成统一的max_length维度,这里选择训练集中最多的词语个数作为max_length;
[0092]
第四步:生成数据迭代器。对于深度学习来说,需要把数据分为多个批次送入到模型中去训练,每个批次的数据个数为32,在生成迭代器的过程中,同时把数据添加到gpu中;
[0093]
通过,使用中心位置匹配的目的是使匹配出的原文中的摘要索引更紧凑,增加模型识别率,并通过训练集中的词不出现再腾讯词向量词典中时,为了和腾讯词向量的维度统一,则随机初始化为200维词向量,并通过选择最多的词语个数为max_length,则可以覆盖所有的数据。
[0094]
其中,模型构建二网络结构如下:
[0095]
第一层:embedding
[0096]
第二层:linear()
[0097]
第三层:dropout(0.5)
[0098]
第四层:dcnn(dilation_rate=1)
[0099]
第五层:dropout(0.5)
[0100]
第六层:dcnn(dilation_rate=2)
[0101]
第七层:dropout(0.5)
[0102]
第八层:dcnn(dilation_rate=4)
[0103]
第九层:dropout(0.5)
[0104]
第十层:dcnn(dilation_rate=1)
[0105]
第十一层:dropout(0.5)
[0106]
第十二层:linear()
[0107]
第十三层:sigmoid();
[0108]
embedding是向量表示层;linear()是全连接层,dropout为失活层,这里随机选择50%的网络节点失活,每一层的dcnn后都接一个失活层;dcnn为膨胀卷积神经网络,dilation_rate为膨胀率;
[0109]
通过,网络结构(见图2)中,linear()是全连接层,这里的作用是降维,通过失活层随机选择50%的网络节点失活,为了防止过拟合,通过基础模型选择膨胀卷积神经网络,膨胀卷积神经网络相比于普通的卷积神经网络,视野更广,能够捕捉到更远距离的数据信息,dilation_rate设置为1、2、4,由于数据是短文本,dilation_rate设置太大并没有太大作用,通过第十二层的linear()用于最后的分类,并由于该任务属于多标签分类,所以最后使用sigmoid()函数做评分。
[0110]
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。
[0111]
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1