分类预测模型训练方法、分类预测方法、设备及存储介质
本发明属于隐私计算,尤其涉及一种基于联邦知识蒸馏算法的分类预测模型训练方法、分类预测方法、电子设备及存储介质。
背景技术:
1、由于移动设备(例如手机、手表、电脑等)的高度发展和传感技术的进步,大量的数据(为用户私有数据,例如个人图片)被边缘端的移动设备收集,如今人工智能发展迅速,这种隐私数据通常会被聚合并且存储在云端,配合机器学习或者是深度学习模型,实现各种智能应用。然而,在将敏感的原始数据通过网络上传到云端,在云端集中处理私有数据对于数据捐献者来说会出现严重的数据隐私泄露问题,基于保护数据隐私安全的推动力,联邦学习的概念应运而生。与集中式学习模式不同,联邦学习支持在使用本地数据的分布式计算节点上对全局模型进行协作学习,不将原始数据发送到云端,只将学习好的全局模型更新提交到云端进行聚合;然后,更新云端上的全局模型,并将其发送回分布式计算节点进行下一轮迭代。通过这种迭代方式,可以在不损害用户隐私的情况下学习全局模型,除了改善数据隐私问题,联邦学习还带来了许多其他好处,比如提高了安全性,自主权和效率等。
2、随着联邦学习的发展,也出现了许多新的挑战。最主要的挑战来自两个方面:
3、(1)传统的联邦学习算法在每次迭代时共享模型参数,这意味着通信开销会过大。由于现有的深度学习模型可能会有数百万个参数,例如mobilebret是一种自然语言处理任务的深度学习模型结构,有2500万个参数,对应96mb的内存大小,而边缘端的移动设备经常会受到带宽限制,每轮通信都需要交换96mb的信息,对于移动设备来说是具有挑战性的,这导致许多移动设备无法参与到需要进行大参数交互的联邦学习任务当中。
4、(2)异构性问题对于想要在现实场景中部署联邦学习系统造成了巨大挑战。一方面是模型异构问题,大部分参与联邦学习任务的移动设备之间的计算资源与带宽资源都不相同,移动设备没有足够的带宽或者计算能力来训练大型的深度学习模型,这意味着不同的参与者可能需要不同架构的模型进行训练,而基于模型参数交互的联邦学习架构满足不了参与者使用不同架构模型的需求;另一方面是数据异构问题,每个参与联邦学习任务的移动设备的本地数据分布在全局上呈现出非独立同分布的特点,单纯聚合移动设备客户端的模型参数可能会阻碍模型的收敛。
5、基于上述约束,通过联邦学习任务训练出来的全局模型在现实实践中可能不具备很高的精度。
技术实现思路
1、本发明的目的在于提供一种基于联邦知识蒸馏算法的分类预测模型训练方法、分类预测方法、设备及存储介质,以解决传统联邦学习算法通信开销过大,传统联邦学习算法无法满足参与者使用不同架构模型的需求以及数据异构导致模型精度无法提升的问题。
2、本发明是通过如下的技术方案来解决上述技术问题的:一种基于联邦知识蒸馏算法的分类预测模型训练方法,包括以下步骤:
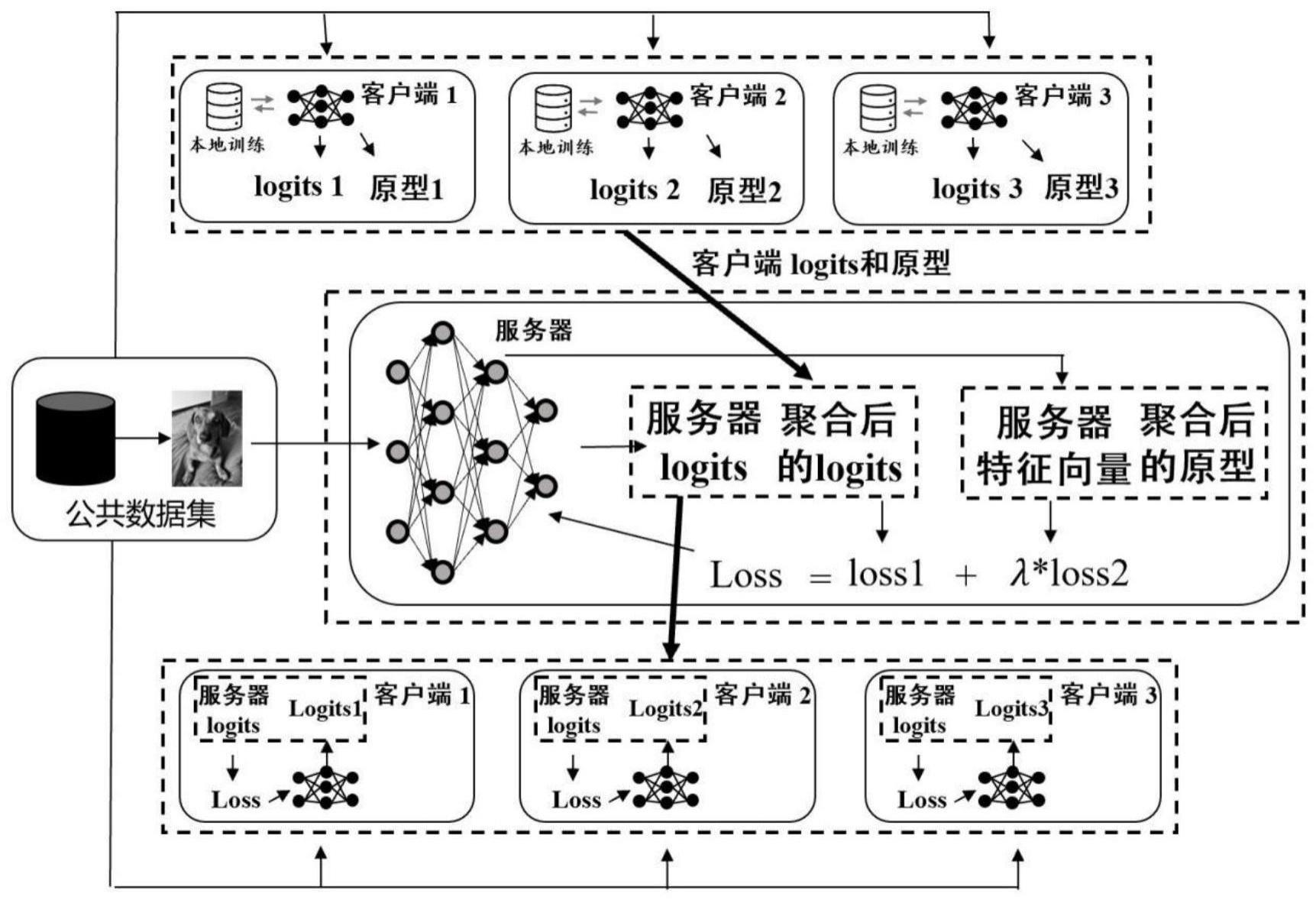
3、步骤1:构建由中央服务器端和n个客户端c={c1,c2,...,ci,...,cn}组成的联邦学习系统,其中,n≥2,ci表示第i个客户端;
4、步骤2:每个所述客户端ci均在本地构建带标注的本地训练数据集di和本地分类预测模型xi,且令循环轮次t=1;
5、步骤3:每个所述客户端ci在本地利用本地训练数据集di对本地分类预测模型xi进行迭代训练,并利用训练后的本地分类预测模型xi计算出本地训练数据集di中各类数据的原型其中,类k数据的原型是指类k数据的本地分类预测模型xi输出特征向量的平均值;
6、每个所述客户端ci在本地利用训练后的本地分类预测模型xi计算出未带批注的公共数据集dp的软决策其中,所述软决策是指本地分类预测模型xi的预测输出;
7、步骤4:所有客户端c将各自计算出的原型和软决策发送给所述中央服务器端;
8、步骤5:所述中央服务器端将接收到的每个类所有原型和所有软决策分别进行聚合,得到聚合后的各类原型和聚合后的软决策;利用聚合后的各类原型和聚合后的软决策构建优化目标函数,利用公共数据集dp和优化目标函数对构建的全局分类预测模型进行迭代训练;
9、利用训练后的所述全局分类预测模型计算出未带批注的公共数据集dp的软决策其中,所述软决策是指全局分类预测模型的预测输出;
10、步骤6:所述中央服务器端将所述软决策发送给每个所述客户端ci;
11、步骤7:每个所述客户端ci利用接收到的软决策和公共数据集dp对本地分类预测模型xi进行迭代训练;
12、步骤8:判断循环轮次t是否等于设定轮次,如果是,则得到训练好的各本地分类预测模型xi和全局分类预测模型;否则,令t=t+1,并跳转至步骤3。
13、进一步地,所述本地分类预测模型和全局分类预测模型均采用深度残差网络模型。
14、进一步地,对于所述客户端ci,类k数据的原型的具体计算公式为:
15、
16、其中,dk表示类为k的数据集,rw(·)表示本地分类预测模型xi的输入层和隐藏层网络,(xj,yj)∈dk表示数据集dk中的所有数据,xj表示第j个输入样本,yj表示与输入样本xj对应的标注。
17、进一步地,对类k的所有原型进行聚合的聚合公式为:
18、
19、其中,nk表示拥有类k的原型的客户端的数量,pk表示聚合后的类k的原型;
20、对所有软决策进行聚合的聚合公式为:
21、
22、其中,表示聚合后的软决策。
23、进一步地,利用聚合后的各类原型和聚合后的软决策构建的优化目标函数的具体表达式为:
24、
25、
26、其中,(xj,k)∈dp表示无标签的公共数据集dp,k表示样本xj的预测标签且由所有软决策聚合后的分布所决定的;l2(·)为相对熵损失函数;ci∈cn表示所有客户端;αj表示客户端ci的软决策的权重;表示全局分类预测模型的软决策;lm(·)表示均方根损失函数;nk表示拥有类k的原型的客户端的数量;λ表示超参数;表示客户端ci基于类k数据的原型;表示样本xj的全局分类预测模型的隐藏层输出;m表示分类任务中的分类数。
27、基于同一发明构思,本发明还提供一种基于分类预测模型的分类预测方法,所述分类预测模型包括全局分类预测模型和n个本地分类预测模型,所述全局分类预测模型和本地分类预测模型是由上述任一项所述的基于联邦知识蒸馏算法的分类预测模型训练方法训练得到,所述分类预测方法包括以下步骤:
28、获取待分类数据;
29、利用所述分类预测模型对所述待分类数据进行分类预测,得到所述待分类数据的类别。
30、基于同一发明构思,本发明还提供一种电子设备,所述设备包括:
31、存储器,用于存储计算机程序;
32、处理器,用于执行所述计算机程序时实现上述任一项所述的基于联邦知识蒸馏算法的分类预测模型训练方法的步骤,或实现上述基于分类预测模型的分类预测方法的步骤。
33、基于同一发明构思,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现上述任一项所述的基于联邦知识蒸馏算法的分类预测模型训练方法的步骤,或实现上述基于分类预测模型的分类预测方法的步骤。
34、有益效果
35、与现有技术相比,本发明的优点在于:
36、本发明所提供的一种分类预测模型训练方法、分类预测方法、电子设备及存储介质,客户端的私有数据和本地分类预测模型均存储在客户端本地,保证了私有数据的隐私安全;利用知识蒸馏将基于模型参数交互的传统联邦学习改进为基于模型输出软决策交互,大大地减少了服务器与客户端之间的通信开销,同时允许客户端和服务器端根据自身的带宽资源和计算资源选择合适架构的模型,实现了模型架构的个性化。
37、同时,本发明还通过原型网络缓解了由于客户端私有数据高度异构化所导致的模型精度难以提高的问题,大大提高了模型精度,使用本发明方法的联邦学习框架具有稳定性与高效性。
- 还没有人留言评论。精彩留言会获得点赞!