音频分类模型训练方法、装置、设备和存储介质与流程
本公开涉及人工智能,尤其涉及一种音频分类模型训练方法、装置、设备和存储介质。
背景技术:
1、音频模式识别是机器理解周边世界的重要方式。自动音频识别是一个比较宽的研究领域,主要可分为声音相关和语音相关的研究。语音相关主要集中在语言内容本身,比如,谁在什么时候讲的什么内容。声音相关则主要关注分类,比如,声音场景、声音情感或者声音事件等。
2、相关技术中,音频模式识别会使用具体场景领域训练的模型来处理该具体场景领域的分类任务,比如,使用语音场景相关领域训练的模型处理语音场景相关领域的任务,使用音乐场景相关领域训练的模型处理音乐场景相关领域的任务。
3、然而,在具体场景领域的模型训练之前,为了保证模型性能,需要采用人工方式对大量的音频数据进行强标注,而每个音频数据里通常会包含不同的声音,如果把每个音频数据都进行强标注,这样会使得数据标注工作费时费力,导致训练样本的人工标注成本较高,且训练样本准备时间较长,影响模型训练效率。
技术实现思路
1、本公开实施例提供一种音频分类模型训练方法、装置、设备和存储介质。
2、根据本公开实施例的第一方面,提供了一种音频分类模型训练方法,所述方法包括:
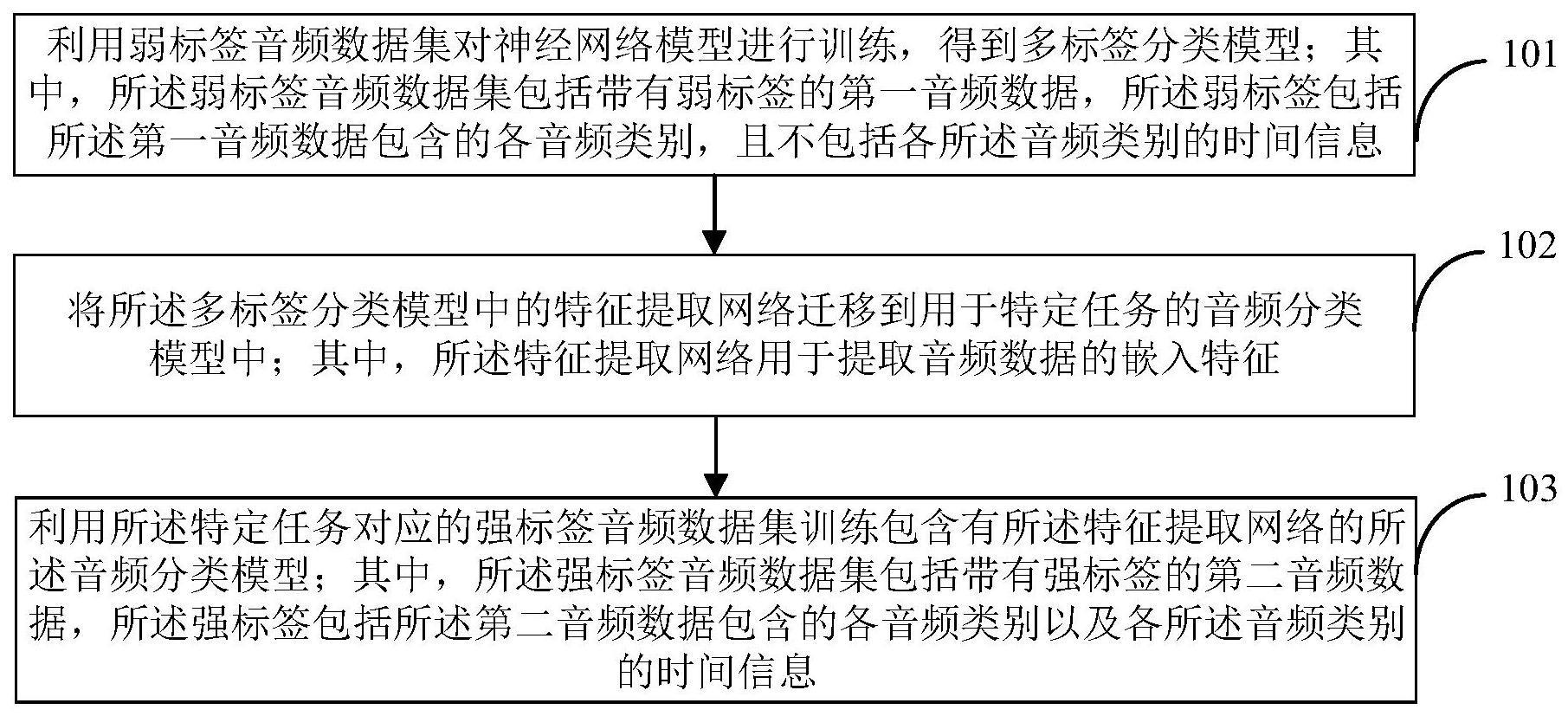
3、利用弱标签音频数据集对神经网络模型进行训练,得到多标签分类模型;其中,所述弱标签音频数据集包括带有弱标签的第一音频数据,所述弱标签包括所述第一音频数据包含的各音频类别,且不包括各所述音频类别的时间信息;
4、将所述多标签分类模型中的特征提取网络迁移到用于特定任务的音频分类模型中;其中,所述特征提取网络用于提取音频数据的嵌入特征;
5、利用所述特定任务对应的强标签音频数据集训练包含有所述特征提取网络的所述音频分类模型;其中,所述强标签音频数据集包括带有强标签的第二音频数据,所述强标签包括所述第二音频数据包含的各音频类别以及各所述音频类别的时间信息。
6、在一个实施例中,所述方法还包括:
7、根据包含多个音频类别的开源数据集,构建所述弱标签音频数据集。
8、在一个实施例中,所述利用弱标签音频数据集对神经网络模型进行训练,得到多标签分类模型,包括:
9、对所述弱标签音频数据集中带有弱标签的第一音频数据进行处理,得到所述第一音频数据的频谱特征;
10、将所述第一音频数据的频谱特征输入到所述神经网络模型中,得到所述神经模型输出的所述第一音频数据对应的类别预测结果;
11、根据所述第一音频数据对应的类别预测结果以及所述弱标签,确定所述神经网络模型的损失函数值;
12、根据所述神经网络模型的损失函数值对所述神经网络模型进行训练,得到所述多标签分类模型。
13、在一个实施例中,所述利用弱标签音频数据集对神经网络模型进行训练,得到多标签分类模型,包括:
14、利用所述弱标签音频数据集对神经网络模型进行预训练,得到预训练后的所述神经网络模型;
15、利用预训练后的所述神经网络模型对无标签的音频数据进行打标签处理,得到带有伪标签的所述音频数据;
16、根据带有伪标签的所述音频数据,获取带有弱标签的所述音频数据;
17、利用带有弱标签的所述音频数据对预训练后的所述神经网络模型进行训练,得到所述多标签分类模型。
18、在一个实施例中,所述神经网络模型为轻量级神经网络模型。
19、在一个实施例中,所述将所述多标签分类模型中的特征提取网络迁移到用于特定任务的音频分类模型中,包括:
20、从所述多标签分类模型中抽取所述特征提取网络;
21、将抽取的所述特征提取网络连接至所述音频分类模型中的输出网络;其中,所述输出网络,用于根据所述特征提取网络提取的音频数据的嵌入特征进行音频分类。
22、在一个实施例中,所述利用所述特定任务对应的强标签音频数据集训练包含有所述特征提取网络的所述音频分类模型,包括:
23、对所述强标签音频数据集中带有强标签的第二音频数据进行处理,得到所述第二音频数据的频谱特征;
24、将所述第二音频数据的频谱特征输入到所述音频分类模型中,得到所述音频分类模型输出的所述第二音频数据对应的类别预测结果;
25、根据所述第二音频数据对应的类别预测结果以及所述强标签,确定所述音频分类模型的损失函数值;
26、根据所述音频分类模型的损失函数值对所述音频分类模型进行训练。
27、在一个实施例中,所述根据所述音频分类模型的损失函数值对所述音频分类模型进行训练,包括:
28、在冻结所述音频分类模型中的所述特征提取网络的网络参数的情况下,根据所述音频分类模型的损失函数值对所述音频分类模型进行训练;
29、或者,
30、在不冻结所述音频分类模型中的所述特征提取网络的网络参数的情况下,根据所述音频分类模型的损失函数值对所述音频分类模型进行训练,以对所述特征提取网络的网络参数进行微调。
31、根据本公开实施例的第二方面,提供了一种音频分类模型训练装置,所述装置包括:
32、第一训练模块,用于利用弱标签音频数据集对神经网络模型进行训练,得到多标签分类模型;其中,所述弱标签音频数据集包括带有弱标签的第一音频数据,所述弱标签包括所述第一音频数据包含的各音频类别,且不包括各所述音频类别的时间信息;
33、迁移模块,用于将所述多标签分类模型中的特征提取网络迁移到用于特定任务的音频分类模型中;其中,所述特征提取网络用于提取音频数据的嵌入特征;
34、第二训练模块,用于利用所述特定任务对应的强标签音频数据集训练包含有所述特征提取网络的所述音频分类模型;其中,所述强标签音频数据集包括带有强标签的第二音频数据,所述强标签包括所述第二音频数据包含的各音频类别以及各所述音频类别的时间信息。
35、在一个实施例中,所述装置还包括:
36、构建模块,用于根据包含多个音频类别的开源数据集,构建所述弱标签音频数据集。
37、在一个实施例中,所述第一训练模块用于:
38、对所述弱标签音频数据集中带有弱标签的第一音频数据进行处理,得到所述第一音频数据的频谱特征;
39、将所述第一音频数据的频谱特征输入到所述神经网络模型中,得到所述神经模型输出的所述第一音频数据对应的类别预测结果;
40、根据所述第一音频数据对应的类别预测结果以及所述弱标签,确定所述神经网络模型的损失函数值;
41、根据所述神经网络模型的损失函数值对所述神经网络模型进行训练,得到所述多标签分类模型。
42、在一个实施例中,所述第一训练模块用于:
43、利用所述弱标签音频数据集对神经网络模型进行预训练,得到预训练后的所述神经网络模型;
44、利用预训练后的所述神经网络模型对无标签的音频数据进行打标签处理,得到带有伪标签的所述音频数据;
45、根据带有伪标签的所述音频数据,获取带有弱标签的所述音频数据;
46、利用带有弱标签的所述音频数据对预训练后的所述神经网络模型进行训练,得到所述多标签分类模型。
47、在一个实施例中,所述神经网络模型为轻量级神经网络模型。
48、在一个实施例中,所述迁移模块用于:
49、从所述多标签分类模型中抽取所述特征提取网络;
50、将抽取的所述特征提取网络连接至所述音频分类模型中的输出网络;其中,所述输出网络,用于根据所述特征提取网络提取的音频数据的嵌入特征进行音频分类。
51、在一个实施例中,所述第二训练模块用于:
52、对所述强标签音频数据集中带有强标签的第二音频数据进行处理,得到所述第二音频数据的频谱特征;
53、将所述第二音频数据的频谱特征输入到所述音频分类模型中,得到所述音频分类模型输出的所述第二音频数据对应的类别预测结果;
54、根据所述第二音频数据对应的类别预测结果以及所述强标签,确定所述音频分类模型的损失函数值;
55、根据所述音频分类模型的损失函数值对所述音频分类模型进行训练。
56、在一个实施例中,所述第二训练模块用于:
57、在冻结所述音频分类模型中的所述特征提取网络的网络参数的情况下,根据所述音频分类模型的损失函数值对所述音频分类模型进行训练;
58、或者,
59、在不冻结所述音频分类模型中的所述特征提取网络的网络参数的情况下,根据所述音频分类模型的损失函数值对所述音频分类模型进行训练,以对所述特征提取网络的网络参数进行微调。
60、根据本公开实施例的第三方面,提供了一种电子设备,包括存储器、处理器及存储在存储器上并在处理器上运行的计算机程序,所述处理器执行所述程序时实现第一方面所述的音频分类模型训练方法。
61、根据本公开实施例的第四方面,提供了一种非临时性计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现第一方面所述的音频分类模型训练方法。
62、本公开实施例提供一种音频分类模型训练方法、装置、设备和存储介质,通过利用弱标签音频数据集对神经网络模型进行训练,得到多标签分类模型;所述弱标签音频数据集包括带有弱标签的第一音频数据,所述弱标签包括所述第一音频数据包含的各音频类别,且不包括各所述音频类别的时间信息;将所述多标签分类模型中的特征提取网络迁移到用于特定任务的音频分类模型中;其中,所述特征提取网络用于提取音频数据的嵌入特征;利用所述特定任务对应的强标签音频数据集训练包含有所述特征提取网络的所述音频分类模型;所述强标签音频数据集包括带有强标签的第二音频数据,所述强标签包括所述第二音频数据包含的各音频类别以及各所述音频类别的时间信息。如此,通过将弱标签音频数据集训练得到的多标签分类模型中的特征提取网络迁移到具体分类任务的音频分类模型中,这样在训练用于特定任务的音频分类模型时,能够降低训练数据的人工标注成本,节省标注时间,从而提高模型训练效率;并且,该多标签分类模型中的特征提取网络具有较强的通用性,能够支持更多下游任务的分类,同时能够保证模型性能。
63、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。
- 还没有人留言评论。精彩留言会获得点赞!