一种基于稠密融合特征提取的机器人抓取主动式学习选择方法
本发明属于计算机视觉技术中的物体抓取位姿预测领域,实现结果为物体位姿预测,涉及到深度学习技术和主动式学习技术,特别涉及一种真实场景下的主动式学习框架,降低抓取模型在不同场景下迁移成本的方法,为一种基于稠密融合特征提取的机器人抓取主动式学习选择方法。
背景技术:
1、物体位姿预测是时下计算机视觉和机器人规划控制交叉学科的一个研究热点,其在工业领域的应用不仅可以大幅节约人力,且由于工业机器人的天然的精度优势,可以减少实际生产中的人为操作带来的误差;在共融服务领域,陪伴机器人和服务型机器人也有着强烈的发展动力。这两类机器人的核心都涉及物体位姿预测技术。不同于传统视觉的分类的问题,位姿预测为回归问题,由于多了深度信息的输入,原始数据的复杂度和标注难度均大幅上升,同时也对网络的实效性能提出了较高的要求,开始追求网络的轻量化,以此降低复杂使用场景下延迟,提高实时预测帧数。
2、当下最新的抓取位姿预测方法都是基于深度学习方法的,深度学习以其深层次的卷积网络可以从海量的数据中发现数据的潜在特征,从而提高最终的模型预测精度。然而深度学习的局限性在于其对数据数量的需求量极大,具体到物体位姿预测领域,数据的复杂度和标注难度增加,进一步增加了模型迁移到不同场景的成本。主动式学习能够很好的解决这一问题,主动式学习对数据能进行一定程度的甄别,每一次进行新数据的筛选时,可以挑选出最不同已有数据的新样本,从而保证所有的数据都能够对模型优化形成正向贡献。
3、抓取方式预测包括传统基于分析和经验法的抓取方式预测和基于深度学习的抓取方式预测。
4、(1)机器人抓取方式检测
5、基于分析法和经验法的抓取方式检测
6、基于分析法和经验法的抓取预测方式属于传统视觉范畴,其时间效率较高,但是面对多样化的物体形状、物体大小和物体纹理等因素,其泛化性存在较大问题,抓取精度较低。分析法对物体的形状进行建模,基于动力学对抓取方式进行预测,但是如果出现形状不规则的物体,分析法无法建模出夹爪和与物体之间复杂的碰撞模型。传统经验法核心在于建立一个经验数据库,包含物体的cad模型和可行的抓取方式,碰到新物体则首先与库中的物体进行匹配,输出物体的抓取方式,然而如果面对差异较大的物体,此方法的识别精度会陡降。
7、基于深度学习的抓取检测方式
8、基于深度学习的抓取检测方法主流一共分为两种,基于2d planer位姿检测和基于6d位姿检测。morrison等人在文章closing the loop for robotic grasping:a real-time,generative grasp synthesis approach中提出了一种基于2dplaner位姿的抓取检测方式,其中包括一个四元素组,中心点坐标、宽度、旋转角和长度,这种抓取方式对应到物体6d空间位姿上,是固定朝一个方向(自上而下)完成抓取操作,简化了输出内容,但是抓取方式受限。feifei li等人在文章densefusion:6d object pose estimation byiterative dense fusion中提出了一种基于6d位姿的抓取方式,优化了对深度信息和色彩信息进行稠密融合,保留全局信息的同时,不损失局部信息,显著提高其识别精度。基于深度学习的抓取方式在识别精度和泛化性能上大幅领先传统分析法和经验法。然而基于深度学习的抓取方法需要大量的数据喂送,对于单个数据的标注难度尚且已经比二维检测有所增加,叠加海量的数据规模,导致制作一个抓取数据集的成本十分高昂。由于目前深度学习技术的局限性,一个场景下制作的数据集所训练出来的模型换到另一个场景,识别精度一定程度上会有所下降,所以在新的场景下重新制作数据集的需求十分迫切,进一步提高数据成本。为了避免数据成本高昂成为阻碍基于深度学习抓取检测方法的发展,有人提出了用主动式学习方法来降低数据成本。主动式学习方法通过对数据的甄别实现对高信息量数据的筛选。为降低模型迁移成本提供了新的思路。
9、(2)主动式学习策略
10、由于数据采集和数据标注的不确定性,在数据集中一般存在不同程度的数据冗余,相似的数据多次出现,实际上对模型优化没有帮助,如果人工标注出现偏差,错误的数据甚至对模型呈现负优化的趋势。主动式学习的目的在于筛选出最具有信息量的数据,使得被选数据都能对模型呈现正向优化,从而只用少量的数据就可以媲美训练整个数据集的效果。
11、主动式学习的核心部分为数据选择策略。按照是否加入标签数据划分,主动式学习分为基于未使用标签和已使用标签两种。值得注意的是测试一种主动式数据选择策略只能在已有的数据集上测试,理论上数据已经打上了标签,但是基于未使用标签的策略不会以标签进行额外筛选。对于未使用标签的策略还可以细分为基于模型和基于数据两种方向。
12、基于无标签的主动式学习策略
13、基于无标签的主动式学习策略包括模型与数据分布两种方法。通过模型的主动式学习策略重点关注数据的不确定性。比较具有代表性的有gorriz等人在文章cost-effective active learning for melanoma segmentation中提出的不确定性策略,利用分类卷积网络输出数据的不确定性,不确定性越高则数据的信息量越高。但是这种网络专门为分类网络而设计,由于拥挤和噪声密集导致对于抓取这一回归问题难以适配。基于不确定理论yoo等人在文章learning loss for active learning中提出使用模型的损失来作为判定不确定性的指标,不确定性越高说明当前模型对于此数据的拟合效果越差,此数据就越应该被标注之后被送进网络进行学习。此方法由于在主动式判别网络上重新计算了一遍损失值大幅提升了算法的时间复杂度,在抓取这一实时性要求较高的任务当中显然不可行。基于数据的主动式学习策略核心在于绘制当前已标注池的数据分布图,对于需判别数据,通过其与已标注池中数据的距离判定信息量的高低,分布差异越大说明数据信息量越高。具有代表性的core-set数据选择策略,此策略将选择样本的过程视为寻找一个当前最佳集合问题,新加入的点需要满足于已标注池集合的距离最大。由于使用中途的特征作为绘制数据分布依据,其有效性在抓取这种深层网络当中还有待商榷。
14、以上两种基于无标签的主动式学习策略由于没有加入真值实例数据辅助数据选择,对于抓取数据筛选判别实际上存在一定偏差。由于抓取数据集中的背景各不相同,无标签的主动式学习策略都将此无用信息加入到了数据的判别当中,降低了对于数据判别的准确性。
15、基于标签的主动式学习策略
16、考虑到基于无标签的理论的局限性,yuan等人在文章multiple instance activelearning for object detection中提出了将标签实例加入到数据鉴别的指标当中,增加主动式学习对于目标检测场景的适配度。由于目标检测是传统二维视觉中的分类和回归问题的组合任务,对于基于三维视觉的抓取方式检测这种纯回归任务,不管是在任务的源头还是在数据输入层面都存在很大差异,难以直接将yuan等人的思路直接运用到本文的抓取任务当中。
17、本发明中涉及的抓取方式检测方法是一个纯粹的回归问题,并且对实时性要求较高。以上提到的主动式学习策略均存在局限性,要么无法直接适用于回归问题,要么计算量过大,不能满足抓取任务的实时性要求,或者引入了背景噪音等无用指标,同时还涉及到数据的差异性问题。基于以上种种难点,本发明提出了相应的解决方案。
技术实现思路
1、本发明致力于解决机器人抓取问题训练时间长,数据集冗余问题。设计出了一种面向机器人抓取的数据选择方法,挑选出数据集中信息量最高的数据,从而只训练部分数据达到训练整个数据集的效果,降低抓取模型在不同场景下的迁移成本。主动式学习模块和抓取预测模块是并行结构,可一起进行训练。模型训练完成之后,抓取检测模型为闭环端到端结构,截取当前的色彩和深度数据作为输入,可以输出物体的抓取位姿,并且进行可视化。为了降低使用者使用门槛,本发明还内嵌一个抓取方式标注接口,可视化的手段标注抓取方式,并反向解算出真值四元数组。
2、本发明的技术方案:
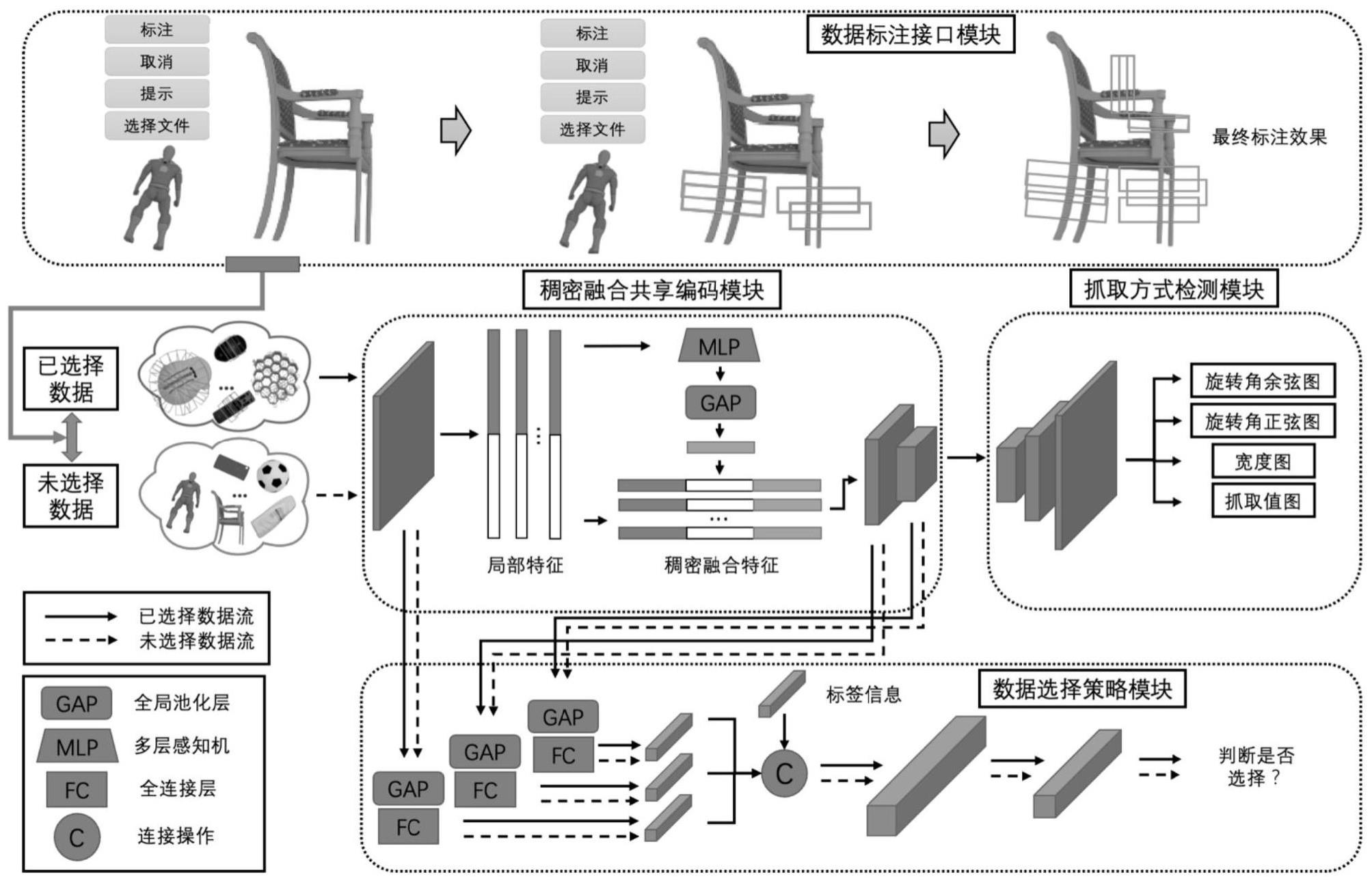
3、一种面向机器人抓取的数据主动式选择方法,主要分为两个分支,物体抓取方式检测分支以及数据选择策略分支,整体结构可以表示为图1所示。其中具体包括以下四个模块:
4、(1)稠密融合共享编码模块
5、本模块为稠密融合共享特征提取模块,稠密提取数据中的局部信息和全局信息,由于后续抓取方式检测模块和数据选择策略模块都需要此特征,所以本模块为二者所共享,大幅度减少了模型参数,使得原本结合主动式学习框架可能带来的高参数量问题得以解决。
6、(1.1)模块输入:
7、本模块的输入指定为rgb和深度图像信息,rgb图像为3通道,深度图像1通道。对图像的大小没有特别要求,本模块中的稠密融合部分会将图像大小调整为300x300的尺寸。
8、(1.2)模块结构:
9、稠密融合部分首先将图像裁剪为300见方大小;第二步对深度信息和色彩信息进行卷积,输出特征图大小为300x300;第三步将色彩信息和深度信息直接拼接作为局部特征;第四步将局部信息输入至多层感知机中,对不同纬度的信息进行收集,然后经过平均池化得到全局信息,大小为300x300,最后与局部信息进行拼接,通道数变为5。
10、取得了稠密融合的特征信息之后,为了网络的轻量性以及检测算法的实时性,本模块采用了morrison等人使用的三层卷积神经网络结构。具体地,卷积核的大小分别为9×9,5×5和3×3。输出通道数分别为40,20和10。特征提取模块每一层都由卷积层,激活函数(relu)组成,整个过程表述如下公式:
11、out1=f(fus) (1)
12、out2=f(out1) (2)
13、out3=f(out2) (3)
14、其中fus表示稠密融合部分得到的5通道输入数据,f代表卷积层与激活函数(relu)的组合,out1、out2与out3分别代表了三层输出的特征图。在输入图像的长宽均为300像素的情况下,out1的大小为100像素×100像素,out2的大小为50像素×50像素,out3的大小为25像素×25像素。
15、(2)抓取方式检测模块
16、本模块利用稠密融合共享特征提取模块得到的最终特征图进行反卷积操作,将特征图还原到原输入大小,即300像素×300像素,得到最终的结果,即抓取值图、宽度图以及旋转角的正弦图与余弦图。根据这四张图像,可以得到物体抓取表示方法的中心点、宽度以及旋转角。
17、(2.1)模块输入:
18、本模块的输入是公式(3)中得到的特征图out3。
19、(2.2)模块结构:
20、包含三个反卷积层,以及四个单独的卷积层。三个反卷积层的卷积核大小分别设置为3×3、5×5和9×9,经过反卷积层之后得到原始大小的特征图;四个单独的卷积层卷积核大小为2×2,分别对应抓取值图、宽度图、正弦图和余弦图。此外,在进行反卷积操作之后,每一层还包括relu激活函数,以实现更有效的表示,而四个单独的卷积层将直接输出结果。这个过程可以简单地表述为:
21、x=df(out3) (4)
22、p=p(x) (5)
23、w=w(x) (6)
24、s=s(x) (7)
25、c=c(x) (8)
26、其中out3为特征提取层的最终输出,df为三层反卷积层以及对应的激活函数relu的组合,p、w、s和c分别代表四个单独的反卷积层,对应的p、w、s和c分别代表最终输出的抓取值图、宽度图以及旋转角的正弦图与余弦图。最终抓取方式的表示可以由下述公式得到:
27、(i,j)=argmax(p) (9)
28、width=w(i,j) (10)
29、sinθ=s(i,j) (11)
30、cosθ=c(i,j) (12)
31、
32、其中,argmax表示获得图中最大值点的横纵坐标(i,j),宽度width、旋转角正弦值sinθ和旋转角余弦值cosθ分别由对应的输出图像及上述坐标得到,最终旋转角θ可由反正切函数arctan得到。
33、(3)数据选择策略模块
34、为了大幅减少网络参数量,降低算法的时间复杂度,基于标签的数据选择模块共享稠密融合编码模块得到的各个维度的特征图,并利用这些特征图经过一系列处理得到最终的概率输出。该输出在0到1之间,代表了输入数据为已选中数据的概率。越接近0的值代表该数据已经被选中的概率越小,信息量越高,这些数据最不可能是已选中的数据,应当被策略所选择。
35、(3.1)模块输入:
36、本模块为多层感知机结构,输入是公式(1)、(2)和(3)得到的out1、out2和out3的组合。在经过三个维度的卷积层之后,还需要输出图像对应的五个标签进行拼接。
37、(3.2)模块结构:
38、如上所述,特征提取模块得到的特征图大小不一,因此,本模块首先使用了平均池化层对特征图进行降维操作,按照三个特征图的通道数分别降为长度为40、20和10的特征向量。之后,每个特征向量单独经过一个全连接层,输出一个长度为20的向量。三个长度为20的向量相连接。此时还需要与未选中数据对应的5个标签进行拼接,为了得到抓取位置最佳的五个标签实例,采用聚类算法得到标签的4元组数据分布,筛选出分布集中的五个标签,之后融合得到一个长度为80的向量。为了更好的提取特征,长度为80的向量被输入到一个卷积层及一个激活函数relu中,输出通道数为40。该长度为40的向量,最终通过一个全连接层,降维成一维,即为最终的结果值。该输出在0到1之间,代表未选中数据与已选中数据的相同的概率。该过程可以简单表示为以下公式:
39、f1=fc(gap(out1)) (14)
40、f2=fc(gap(out2)) (15)
41、f3=fc(gap(out3)) (16)
42、k=f(f1+f2+f3+gt) (17)
43、其中,gap代表全局平均池化层,fc代表全连接层,+代表连接操作,f代表卷积层、激活函数relu和全连接层的组合,k是最终的输出值。
44、(4)数据标注接口模块
45、数据标注接口配合数据选择策略模块与抓取方式检测模块使用,完成对数据的标注工作;该接口使用pyqt5实现。
46、(4.1)模块输入:
47、模块输入原始拍摄的rgbd图片。
48、(4.2)模块结构:
49、该模块首先将原始rgbd图片进行基础裁剪至300x300,然后开始以拖动矩形框的方式进行标注,通过计算可得抓取所需的四元数组,保存到txt文件中,以供训练时使用;该标注模块一共包含四个按钮,分别为标注、取消、提示、选择文件,同时还包含一个操作窗口与预览窗口。由该模块标注好的数据,输入到数据选择策略模块和抓取方式检测模块并行训练。
50、本发明的有益效果:
51、(1)稠密融合共享编码模块
52、该模块对rgbd图像做基础信特征提取,对于rgb信息和深度信息的融合不再是简单的拼接,这样只能保留图像的局部信息,对于全局信息有所忽略。在全局信息提取器中可以感受各个维度的信息,再和局部信息进行拼接,达到稠密融合的目的,为后续抓取方式检测模块准备了丰富的特征信息。同时此模块同时为后续数据选择模块和抓取方式检测模块所共享,大幅减少了网络参数量,提高抓取模型的实时性。
53、(2)内嵌的数据选择策略模块
54、本发明的核心内容为数据选择策略模块,该模块共享主干网络的特征提取层,并融合了三个不同大小感受野的特征,同时提取到局部编码信息和全局编码信息,减少了特征的损失。由于并行结构中特征提取部分的共享特性,大大减少了额外的参数量。在主干的抓取方式检测网络模型训练过程中,数据选择策略模块可以进行同步的训练,从而形成端到端的模型,降低用户的使用门槛。
55、(3)主动式学习对于抓取检测的充分适配
56、相较于其他主动式学习策略,本发明解决了主动式学习在抓取方式检测的适配难题。通过一些列的网络处理完成了分类问题到回归问题的适配转化,加上实例标签引入,使得主动式判别式模型能够聚焦于被抓取物体的区域,相应的背景噪声等与抓取物体及方式无关内容影响程度变小,数据的区分和信息量的判断能够真正向应该关注的要素倾斜,提高了数据甄别的效率和准确率,减少了抓取检测模型在不同场景下迁移的成本。
57、(4)充分利用所有数据
58、由于本文的主动式选择策略能够选择出信息量最高的数据,这意味着可以排除掉不良数据对模型带来的负优化影响。达到只选用部分数据训练媲美整个数据集训练的效果。大幅减少了模型在训练阶段带来的时间成本,甚至在已选中池中的数据量接近的数据总量时会超过整个数据集的训练效果。
59、(5)集成抓取方式标注接口
60、抓取方式标注接口简化了抓取标注的繁杂流程,以可视化的方式对抓取进行标注,反向解算出真值四元数组,避免了用户进行复杂的位置角和坐标计算,封装为一个整体,降低标注门槛,同时也加快抓取模型在不同场景的迁移速度。
- 还没有人留言评论。精彩留言会获得点赞!