一种基于相关熵的宽度稀疏学习算法
本发明涉及数据分析,尤其涉及一种基于相关熵的宽度稀疏学习算法。
背景技术:
1、在数据分析处理任务中,深度学习(deep learning,dl)因其具有强大的非线性映射能力和特征表示能力而受到广泛应用。然而,为了保证模型的性能,往往需要设计多个卷积层、池化层、全连接层等隐含层,导致模型的时间复杂度较高且超参数的数量较多。此外,如果所设计的深层结构不足以很好地对数据建模,则需要重新完整地训练新的模型。在如今这个大数据时代,数据信息量庞大、维度较多且更新较快,用深度神经网络处理高维数据的速度很慢,导致系统无法实现实时响应。因此,亟需设计一个快速高效的且可以快速重训练模型的网络架构来应对各种数据分析处理任务。
2、近年来,宽度学习系统(broad learning system,bls)在数据回归和分类任务中获得广泛关注。与深度神经网络从深度这个维度堆叠隐含层的方式不同,bls网络是从宽度这个维度构建的一个“平层”网络(flatted network)。在该网络模型中,原始输入数据被激活函数转换为映射特征并被置为特征节点,然后再通过一个非线性映射函数进一步增强得到若干个增强节点。通过一系列的特征节点、稀疏自编码器(sparse autoencoder)和增强节点,生成了在增强节点层中进行宽度扩展的网络体系结构。此外,bls模型的输出权重的优化可以简化为最小二乘问题,利用moore-penrose逆可以高效地对其求解。相对于深度神经网络而言,bls网络同样具有很强的逼近能力,但模型仅包含特征节点层(feature nodeslayer)和增强节点层(enhancement nodes layer)两层,因此收敛速度更快、参数量更少。此外,当要增加新的训练样本或者节点时,深度神经网络需要重新训练模型,而bls模型可以通过设计增强学习(incremental learning)算法动态地更新模型的连接权重,无需再训练整个网络。
3、现有的bls模型大多是在训练数据是无噪声干扰的这一假设下设计的,因此都是采用最小均方误差(minimum mean square error,mmse)作为模型的损失函数进行训练的。虽然标准的bls在一般的数据回归和分类任务中表现出了良好的准确性和执行效率,但由于数据在采集、传输、存储等过程中非常容易受到噪声干扰,而mse测量的是预测值和真实值之间的误差的平方和,当数据中存在噪声时,模型估计误差较大,噪声数据会被分配更高的权重。因此,基于mmse损失函数的bls模型在处理受噪声污染的数据时性能表现较为一般。此外,当噪声数据不满足高斯分布或者拉普拉斯分布这一假设时,模型的性能会随着噪声比例的增加而急剧下降。总之,现有bls模型的鲁棒性有待进一步提高。
4、为了降低噪声对模型性能的影响,研究者们在损失函数的基础上增加了一个加权惩罚因子(weighted penalty factor)来约束每个样本数据对建模的贡献。具体地,对无失真的样本分配较高的权重来增加其贡献,对异常样本分配较低的权重来减少其贡献。在现有的较为鲁棒的bls模型中,加权惩罚因子的设计存在一些问题:1)人为设计的加权惩罚因子需要依赖研究者的经验设置参数;2)某些加权惩罚因子是根据特定的数据集设计的,因此模型的泛化能力不够好;3)加权惩罚因子只是对噪声数据分配低权重,也就是说,噪声数据仍然参与数据建模,因此模型性能依然会在某种程度上受噪声影响。
技术实现思路
1、本发明公开一种基于相关熵的宽度稀疏学习算法,旨在解决背景技术中提出的由于在训练网络输出权重时,将最小均方误差准则作为损失函数来优化,其学习过程容易受到噪声的影响,缺乏鲁棒性的技术问题。
2、为了实现上述目的,本发明采用了如下技术方案:
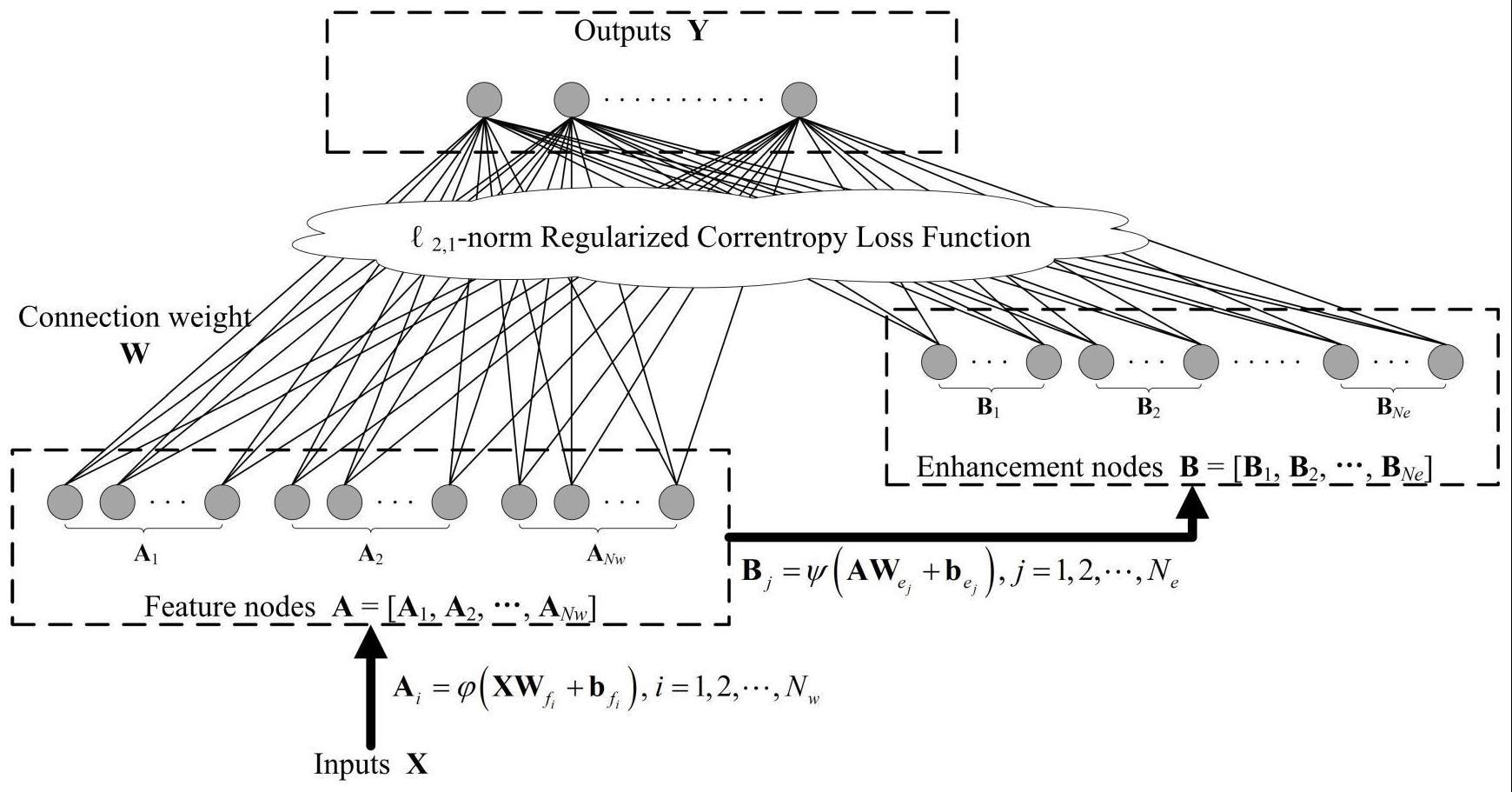
3、一种基于相关熵的宽度稀疏学习算法,包括rcbls网络,所述rcbls(regularizedcorrentropy broad leaning system)网络包括输入层、隐含层和输出层,所述rcbls网络的隐含层由nw组特征节点和ne组增强节点组成,每组所述特征节点和增强节点分别包含nf和nh个节点。输入数据首先通过一个非线性映射函数提取出特征信息作为特征节点,映射特征再在通过一个非线性激活函数增强后置为增强节点,将所有所述特征节点和增强节点与输出层相连接后即可得到一个完整的bls网络,给定一个包含n个样本的训练集其中,表示训练样本的特征(属性),表示样本的输出(标签),m和l分别表示样本特征和输出的维度,训练数据x首先通过一个非线性映射函数投影到特征节点层,得到对应的输出
4、
5、其中,和分别为随机生成的输入层和特征节点层之间的权重和偏置。
6、在一个优选的方案中,将所述特征节点层的输出a通过非线性映射函数φ(·)输入到增强节点层,得到
7、
8、其中,和分别为随机生成的特征节点层和增强节点层之间的权重和偏置。一般地,非线性激活函数可设置为tanh函数或者sigmoid函数将所述特征节点和增强节点连接起来,得到矩阵z=[a|b],最终的bls模型定义为
9、y=zw (3)
10、其中,w是bls模型的连接权重,基于最小二乘线性方程的岭回归算法,可通过求解以下凸优化模型快速计算隐藏层和输出层之间的连接权重
11、
12、其中,||·||2表示l2范数,λ表示正则化参数,公式(4)是标准bls模型的目标函数,目标函数的数据保真项用于控制模型预测值与真实值保持一致,而正则化项则用于平滑权重w的分布以及避免过拟合问题。
13、在一个优选的方案中,通过对所述公式(4)求偏导,可得模型的最终解为
14、w=(ztz+λi)-1zty (5)
15、由公式(4)可以看出,原始的bls模型是基于l2范数实现的,而l2范数假设模型参数服从高斯分布。当样本的特征或标签中存在噪声和离群值时,bls模型的性能表现较差。为了进一步增强bls模型的鲁棒性,使用correntropy作为损失函数来去除数据中的噪声和离群值,用l2,1范数作为正则化项来选择有用的特征信息,目标函数定义为
16、
17、其中,σ表示用于控制correntropy所有属性的核函数的大小,由于公式(6)是非凸的,因此采用半二次理论对其进行优化求解,根据hq准则,存在一个共轭函数ζ(u)使得
18、
19、其下确界为
20、
21、在本发明中,κ(v)=exp(-v/σ2),为了简便起见,记ri=||ziw-yi||2,且将公式(6)中的前一项记为
22、
23、根据公式(7),可将公式(9)重新表示为
24、
25、其中,辅助变量pi定义为
26、
27、因此,算法的目标函数可表达为
28、
29、其中,
30、在一个优选的方案中,根据hq准则,可以通过迭代更新变量p和w求解目标函数的解,即首先初始化一个权重矩阵w,然后根据公式(12)计算对角矩阵p,当p固定之后,公式(11)可简化为
31、
32、由于l2,1正则项的存在,公式(13)仍然是非光滑的凸函数,很难直接求解其封闭解。l2,1范数的定义为
33、
34、其中,wi表示矩阵w的第i行。为了求解公式(13),首先构建一个辅助变量
35、
36、其中,ε为一个极小的正数,作用在于防止分母为0。当wi≠0时,存在因此,公式(13)中的可以重新表述为
37、
38、当w的值固定之后,可以根据公式(15)求解得到矩阵q,当q固定之后,基于公式(16)对w求偏导可得
39、
40、令公式(17)等于0,可以得到关于w的封闭解为
41、w=(ztpz+λq)-1ztpy (18)
42、由上可知,所述rcbls(regularized correntropy broad leaning system)网络包括输入层、隐含层和输出层,所述rcbls网络的隐含层由nw组特征节点和ne组增强节点组成,每组所述特征节点和增强节点分别包含nf和nh个节点。输入数据首先通过一个非线性映射函数提取出特征信息作为特征节点,映射特征再在通过一个非线性激活函数增强后置为增强节点,将所有所述特征节点和增强节点与输出层相连接后即可得到一个完整的bls网络,给定一个包含n个样本的训练集其中,表示训练样本的特征(属性),表示样本的输出(标签),m和l分别表示样本特征和输出的维度。本发明提供的基于相关熵的宽度稀疏学习算法基于correntropy损失和l2,1正则化提出了一种新的bls模型,称为rcbls(regularized correntropy-based bls)。现有的bls模型通过设计不同的加权机制来调整噪声数据和无污染数据的权重,而本发明所提出的算法能够在提取特征信息的同时迭代地去除数据中的噪声和离群值。显然,丢弃噪声数据而只使用无污染数据进行建模的方式比对噪声数据分配低权重来建模的方式更能有效地消除噪声对数据建模的影响。
- 还没有人留言评论。精彩留言会获得点赞!