一种openGauss访问ORC数据的方法与流程
本发明涉及数据库存储,尤其涉及一种opengauss访问orc数据的方法。
背景技术:
1、hadoop是一种适用于大数据处理的分布式系统基础架构。用户不需要了解hadoop具体的底层实现细节,就可以在该框架上开发分布式程序,从而充分利用集群的优势来进行高速运算和存储。虽然hadoop具有高可靠性、高扩展性、高效性、高容错性等优点,但是也存在一些已知缺点,如数据处理时延较高、不适合大量小文件高效存储、不适合多用户写入文件。而传统的关系数据库处理数据时延低、可以存储大量小文件、适合多用户操作,恰好可以弥补hadoop的上述缺点。因此可以利用hadoop大数据平台进行数据的存储和计算,而使用关系数据库进行数据管理以及用户交互。
2、组合使用关系数据库与hadoop平台进行大数据处理虽然解决了大数据处理的难题,但是如何实现关系数据库和hadoop的交互也是一个存在已久的问题。目前一般的交互方法就是数据迁移,关系数据库与hadoop平台各保存一份数据,但是为了保证数据的一致性,就必须进行频繁的数据同步操作。传统的关系数据库与hadoop平台交互方法对数据的处理时延较高,大量跨集群数据搬移的效率低,数据的重复存储导致磁盘消耗大。
3、因此,如何提供为传统的关系数据库与hadoop平台提供一种更加高效和准确的交互方法,成为亟待解决的技术问题。
技术实现思路
1、有鉴于此,为了克服现有技术的不足,本发明旨在提供一种opengauss访问orc数据的方法。可以减少数据存储、迁移(导入导出)所带来的资源和时间开销,保障数据一致性、实时性和正确性。
2、本发明提供一种opengauss访问orc数据的方法,其特征在于,所述方法包括:
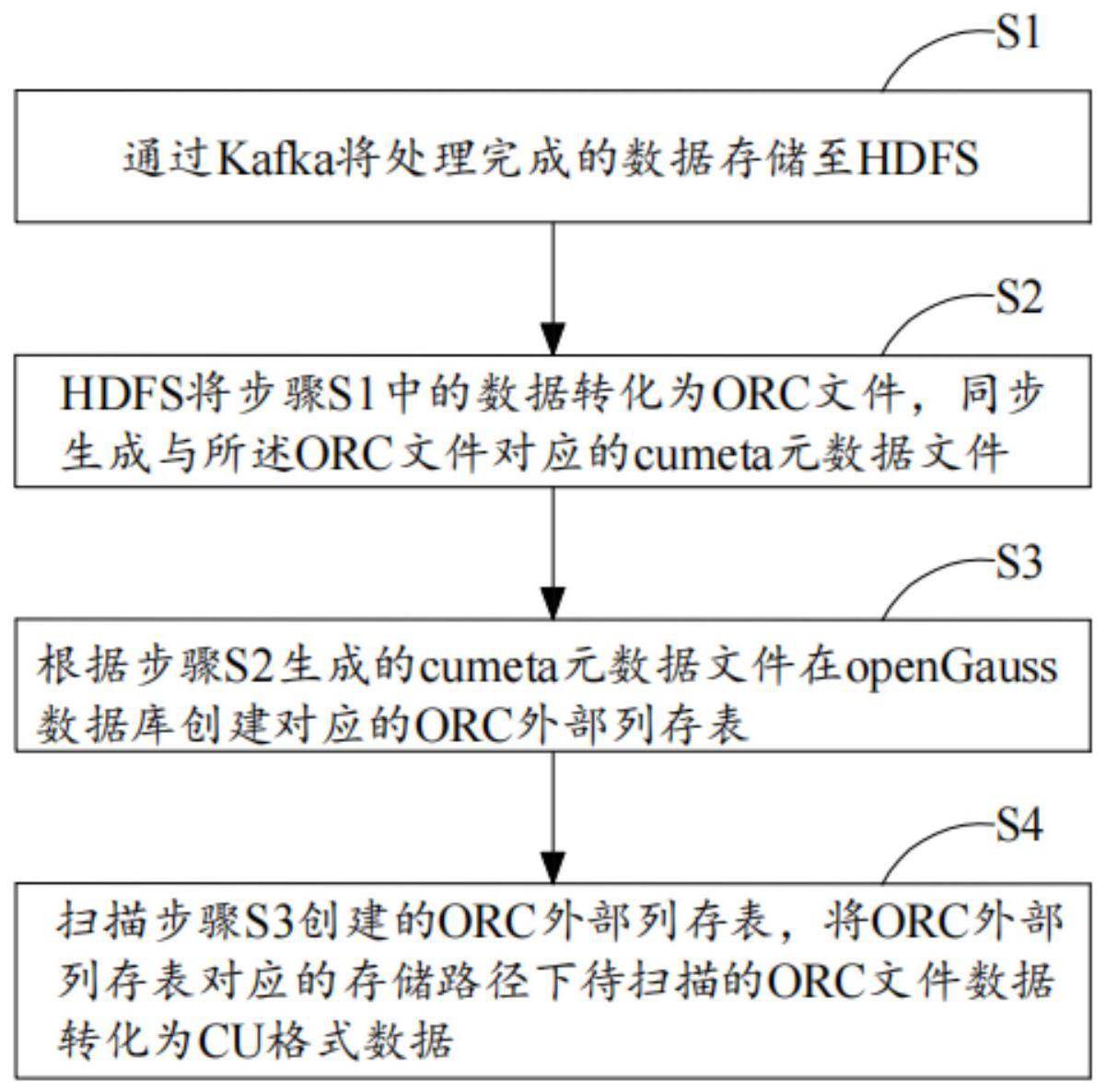
3、步骤s1:通过kafka将处理完成的数据存储至hdfs;
4、步骤s2:hdfs将步骤s1中的数据转化为orc文件,同步生成与所述orc文件对应的cumeta元数据文件;
5、步骤s3:根据步骤s2生成的cumeta元数据文件在opengauss数据库创建对应的orc外部列存表;
6、步骤s4:扫描步骤s3创建的orc外部列存表,将orc外部列存表对应的存储路径下待扫描的orc文件数据转化为cu格式数据。
7、进一步地,本发明opengauss访问orc数据的方法的步骤s2中,同步生成与所述orc文件对应的cumeta元数据文件,包括:
8、步骤s21:在writerimpl类中调用init函数打开hdfs中已有对应的cumeta元数据文件,当hdfs中不存在对应的cumeta元数据文件时,创建并打开所述对应的cumeta元数据文件;
9、步骤s22:获取orc文件的strip元数据信息,将获取的strip元数据信息写入cumeta元数据文件;
10、步骤s23:在完成所述orc文件中所有strip元数据信息的写入时,调用writerfooter函数关闭orc文件和cumeta元数据文件。
11、进一步地,本发明opengauss访问orc数据的方法的步骤s3包括:在opengauss数据库内部扩展现有创建内部表的语法,采用扩展的创建内部表的语法对orc外部列存表进行创建,获得orc外部列存表。
12、进一步地,本发明opengauss访问orc数据的方法的步骤s3中,在opengauss数据库内部扩展现有创建内部表的语法,包括:
13、将表的标识项orientation的值设置为orc;
14、新增用于定位orc文件位置的location选项,将location选项的值设置为orc外部表存储路径。
15、进一步地,本发明opengauss访问orc数据的方法的步骤s3中,采用扩展的创建内部表的语法对orc外部列存表进行创建,包括:
16、判断标识项orientation的值是否为orc,当标识项orientation的值为orc时,根据location选项的值访问cumeta元数据文件,读取cumeta元数据的每一行,对读取的每一行cumeta元数据进行合法性校验,将通过合法性校验的每一行cumeta元数据转化为cudesc元数据信息后插入cudesc表中,所述cudesc元数据信息包括orc文件的全路径、数据块所在strip的strip id以及数据块id。
17、进一步地,本发明opengauss访问orc数据的方法的步骤s4包括:
18、步骤s41:opengauss数据库在加载列存表时根据调用方访问需求加载cudesc表;
19、步骤s42:根据cudesc元数据信息中数据块所在strip的strip id判断加载的列存表是否为orc外部列存表;
20、步骤s43:根据cudesc表中cudesc元数据信息从orc外部列存表对应的存储路径下获取待扫描的orc文件的及待扫描数据块在orc文件中的具体位置信息;
21、步骤s44:根据待扫描的orc文件以及待扫描数据块在orc文件中的具体位置信息,获取待扫描的orc文件中的数据块;
22、步骤s45:将获取的数据块转化为cu格式的数据块后返回至调用方。
23、进一步地,本发明opengauss访问orc数据的方法的步骤s42包括:
24、当数据块所在strip的strip id等于0时,判定表为非orc外部列存表;
25、当数据块所在strip的strip id大于0时,判定表为orc外部列存表。
26、进一步地,本发明opengauss访问orc数据的方法的步骤s43包括:
27、根据cudesc表中cudesc元数据信息的orc文件的全路径获取待扫描的orc文件的具体位置信息;
28、根据cudesc表中cudesc元数据信息的数据块所在strip的strip id以及数据块id获取待扫描数据块在orc文件中的具体位置信息。
29、进一步地,本发明opengauss访问orc数据的方法的步骤s44包括:通过orclib动态库根据cudesc元数据信息从hdfs的orc文件中读取一个strip并对所述strip中的所有数据块进行转换。
30、进一步地,本发明opengauss访问orc数据的方法的步骤s45包括:将与调用方需求对应的转化后的cu格式的数据块返回至调用方,将所述strip中其余数据块缓存至本地临时文件。
31、本发明opengauss访问orc数据的方法,具有以下有益效果:
32、1.通过opengauss数据库直接访问外部orc数据,避免了在关系数据库和大数据平台各保存一份数据带来的存储开销。
33、2.只需要一份数据,避免了频繁的数据同步操作,减少了大量的物理io,同时保证了数据的一致性。
34、3.使用数据库直接查询数据的方式,适合更多样的查询场景,有效提高查询效率。
- 还没有人留言评论。精彩留言会获得点赞!