一种支持语义感知密文检索加速的筛选因子确定方法
1.本发明属于信息检索技术领域,具体是涉及一种支持语义感知密文检索加速的筛选因子确定方法。
背景技术:
2.随着互联网技术的不断发展和各种软件用户的数量不断增加,数据的规模日益庞大,本地化的数据存储已经不能满足日益增长的业务需求。为了解决这个困境,人们转而将数据外包给云服务器。用户可以根据个人所需按量使用计算资源。简而言之,云计算使用互联网的传输能力将数据信息从本地服务器传输到互联网并在互联网上进行数据处理。虽然云计算有很多优点,但也存在一些问题,比如数据隐私问题。为了保护外包数据的隐私,最常见也最直接的方法是在外包到云服务器之前对数据进行加密,再将加密后的数据外包给云服务器。但是,加密后的数据可用性降低,对完成数据检索等基本操作变得复杂困难。同时,加密后的数据语义性降低,难以寻找数据和检索之间的语义关系。因此,许多既能够保证外包数据的隐私性,同时能高效且准确的在云服务器上进行数据检索的可搜索加密方法被提出。
3.近年来,研究者提出的可搜索加密方法在索引结构上主要采用树形结构索引来对加密文档进行排序检索,该类方法通过构建结构简单且自身安全的树形结构索引,通过深度优先搜索检索出最相关的top-k个加密文档。例如,论文“xia z,wang x,sun x,et al.a secure and dynamic multi-keyword ranked search scheme over encrypted cloud data.ieee transactions on parallel and distributed systems,2015”使用了二叉平衡树索引、论文“dai h,dai x,yi x,et al.semantic-aware multi-keyword ranked search scheme over encrypted cloud data.journal of network and computer applications,2019”使用了蕴含语义特征信息的完全二叉树索引、论文“hu z,dai h,yang g,yi x,sheng w.semantic-based multi-keyword ranked search schemes over encrypted cloud data.security and communication networks,2022.”使用了蕴含语义特征信息的聚类二叉树索引等,该类方法均使用检索筛选因子提高检索效率。
4.此类可搜索加密的一般方法是首先将文档和关键词转化为向量表示,接着将文档使用树形索引保存并将文档和索引都进行加密后发送给云服务器。用户将搜索提交给云服务器后,云服务器在加密的树形索引上进行检索并返回用户所需的密文,由用户进行解密。由于现有的基于树形索引的检索方法中,通常使用深度优先搜索,并在搜索过程中,根据被遍历的叶节点从0开始更新检索筛选因子,利用筛选因子剪枝掉不满足要求的子树,从而加速检索过程;然而,现有的基于树形索引的检索方法如前文中的三篇论文中的方法,其中的初始检索筛选因子均设置为0,如果能够在搜索开始前,预先确定一个适宜的筛选因子,就能在检索初期过滤掉更多不满足要求的子树,加速深度优先搜索的过程。
技术实现要素:
5.为解决上述技术问题,本发明提供了一种支持语义感知密文检索加速的筛选因子确定方法,能在不影响检索结果精度的情况下,提升检索效率。
6.本发明所述的一种支持语义感知密文检索加速的筛选因子确定方法,所述方法步骤为:
7.步骤1、为每一个关键词构建该关键词与各文档的语义相关度划分序列;
8.步骤2、根据检索关键词,利用语义相关度划分序列,计算筛选因子。
9.进一步的,步骤1具体为:
10.步骤1a、利用语义感知模型,计算文档集合d中每一个文档dj的语义向量,d={d1,d2,
…
,dj,
…
,dn},j取值范围1-n;从每一个文档dj中提取关键词,生成关键词集合w,w={w1,w2,
…
,wi,
…
,wm},i取值范围1-m,并计算每一个关键词wi的语义向量;
11.步骤1b、对于w中每一个关键词wi∈w,计算其与文档集合d中每一个文档dj∈d的语义相关度relevance(wi,dj),建立wi与d中各文档的语义相关度序列li,然后按照降序对该序列进行排序处理;
12.步骤1c、根据wi的语义相关度序列li和给定的分割参数τ,对序列进行等数量划分,生成wi与各文档的语义相关度划分序列每一个分区表示为一个二元组其中和代表这个分区的上下边界。
13.进一步的,步骤1c具体为:
14.步骤1c1、对每个wi与d中文档的相关度得分进行降序排列,生成语义相关度序列li;对w中的每一个关键词wi,根据分割参数τ,对li进行等量划分,构建wi对应的包含个分区的语义相关度;
15.步骤1c2、划分序列其中前个分区均包含τ个相关度得分,最后一个分区包含的文档数量小于等于τ,并且对于任意相邻的两个分区和而言,中的任一相关度得分均大于中的任一相关度得分;
16.步骤1c3、针对spti中的每一个分区构造二元组计算每个分区的和
17.进一步的,步骤1c3具体为:
18.对于wi对应的spti中的每一个分区,其划分二元组和的计算方法如下,其中,rand(x,y)表示x和y之间的随机值,min(x)表示集合x中元素的最小值,max(x)表示集合x中元素的最大值:
[0019][0020][0021][0022]
进一步的,步骤2具体为:
[0023]
步骤2a、若q为用户交付的检索关键词集合,k为用户需要检索的文档数量;对于q中每个检索关键词wn,n的取值范围1-|q|,计算其前x个语义相关度分区中的文档标记集合的并集u
x
,若u
x
满足下列公式条件,则即为wn对应的局部检索筛选因子;
[0024][0025]
步骤2b、对于集合q中的所有检索关键词wn,按照如下公式计算出最终的筛选因子t;
[0026][0027]
进一步的,步骤2a具体为:
[0028]
对于每个关键词wn,所述u
x
的计算方法如下:
[0029][0030]
本发明所述的有益效果为:1、利用本发明的检索筛选因子确定方法,能够筛选掉更多不符合要求的子树,显著地加速加密搜索过程;
[0031]
2、本发明利用语义相关度划分序列确定检索筛选因子,此检索筛选因子不会暴露每一个文档和关键词之间的相关度得分,且检索筛选因子小于候选结果集中最后一个文档的相关度得分,不会漏检;因此本发明能在保证检索结果不变的前提下,加速检索过程;
[0032]
3、本发明支持基于语义感知的树形结构索引的密文检索应用场景,不依赖于特定的关键词和文档之间的相关度量化方法,所有基于语义感知的相关度度量方法(ldamodel,bert model)等均可使用,具有较强的通用性。
附图说明
[0033]
图1是本发明检索筛选因子确定方法的流程图;
[0034]
图2是本发明所生成语义相关度划分序列的示意图;
[0035]
图3是本发明检索筛选因子为0的检索过程示例图;
[0036]
图4是本发明检索筛选因子为0.51的检索过程示例图。
具体实施方式
[0037]
为了使本发明的内容更容易被清楚地理解,下面根据具体实施例并结合附图,对本发明作进一步详细的说明。
[0038]
为了方便描述,现对相关符号作如下定义:
[0039]
文档集合d={d1,d2,
…
,dn},d中各文档包含的词构成关键词集合w={w1,w2,
…
,wm},q为用户提交的检索关键词集合,k为检索需返回的文档数量;relevance(wi,dj)表示关键词wi和文档dj之间的单关键词-单文档语义相关度得分;spti为wi与各文档的语义相关度划分序列;和代表wi的第x个分区的上下边界。
[0040]
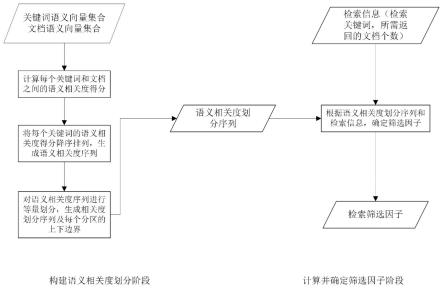
图1是本发明的流程图,描述了支持语义感知密文检索加速的筛选因子计算方法。利用语义感知模型计算每一个文档的语义向量;从文档中提取关键词,并计算每一个关键词的语义向量;为每一个关键词,计算其与每一个文档的语义相关度,形成语义相关度序列,并按照降序对该序列进行排序处理;执行划分,为每一个关键词生成该关键词与各文档的语义相关度划分序列;根据检索关键词,利用主题语义相关度划分序列,计算并确定筛选因子。
[0041]
本发明所述的一种支持语义感知密文检索加速的筛选因子确定方法,包括两个阶段:(1)构建语义相关度划分序列阶段;(2)计算并确定筛选因子阶段;
[0042]
第一阶段:为每一个关键词构建该关键词与各文档的语义相关度划分序列。
[0043]
具体步骤如下:
[0044]
步骤1a、利用语义感知模型,计算每一个文档dj的语义向量;从文档中提取关键词,生成关键词集合w,并计算每一个关键词wi的语义向量;
[0045]
步骤1b、对于w中每一个关键词wi∈w,计算其与d中每一个文档dj∈d的语义相关度relevance(wi,dj),建立wi与d中各文档的语义相关度序列li,然后按照降序对该序列进行排序处理;
[0046]
步骤1c、根据wi的语义相关度序列li和给定的分割参数τ,对序列进行等数量划分,生成wi与各文档的语义相关度划分序列每一个分区表示为一个二元组其中和代表这个分区的上下边界;生成的语义相关度划分序列spti如图2所示,具体生成步骤如下:
[0047]
步骤1c1、对每个wi与d中文档的相关度得分进行降序排列,生成语义相关度序列li;对w中的每一个关键词wi,根据分割参数τ,对li进行等量划分,构建wi对应的包含个分区的语义相关度;
[0048]
步骤1c2、划分序列其中前个分区均包含τ个相关度得分,最后一个分区包含的文档数量小于等于τ,并且对于任意相邻的两个分区和而言,中的任一相关度得分均大于中的任一相关度得分;
[0049]
步骤1c3、针对spti中的每一个分区构造二元组计算每个分区的和计算方法如下。其中,rand(x,y)表示x和y之间的随机值,min(x)表示集合x中元素的最小值,max(x)表示集合x中元素的最大值;
[0050][0051][0052][0053]
第二阶段:根据检索关键词,利用主题语义相关度划分序列,计算筛选因子:
[0054]
步骤2a、若q为用户交付的检索关键词集合,k为用户需要检索的文档数量;对于q中每个检索关键词wn,n的取值范围1-|q|,计算其前x个语义相关度分区中的文档标记集合的并集u
x
,对于每个关键词wn,所述u
x
的计算方法如下:
[0055][0056]
若u
x
满足下列公式条件,则即为wn对应的局部检索筛选因子;
[0057][0058]
步骤2b、对于集合q中的所有检索关键词wn,按照如下公式计算出最终的筛选因子t。
[0059][0060]
以论文“hu z,dai h,yang g,yi x,sheng w.semantic-based multi-keyword ranked search schemes over encrypted cloud data.security and communication networks,2022.”中所述的方法为例,说明本发明的加速检索过程效果。
[0061]
假设文档集合d=《d1,d3,d4,d2,d6,d5》并根据此构建树形索引,假设检索q的主题向量vq=(0,0.8,0,0.5),检索要求返回最相关的两个文档k=2。
[0062]
图3是筛选因子为0时的检索过程,检索从根节点开始,通过r,r2,r3到达第一个叶节点d1,d1和vq的语义相关性得分为relevance(vq,d1)=0.56并且d1被添加到r中;接着,检索通过r3到达叶节点d3,语义相关性得分为relevance(vq,d3)=0.48并且d3被添加到结果集合r中;此时,筛选因子被更新为t=0.48;然后,r4上的节点d4及d2被剪枝,因为relevance(vq,d4)=0.4《t,relevance(vq,d2)=0.1《t;然后,检索通过r,r5到达d6,因为relevance(vq,d6)=0.53》t,所以将d6添加到r中并降序排列r。此时,筛选因子被更新t=0.53。由于relevance(vq,d5)=0.4《t,所以节点d5被剪枝。最后,检索结果为r=《d1,d6》。
[0063]
图4是当筛选因子为0.51时的筛选过程。和上面过程不同的是,当检索通过d3时,relevance(vq,d3)=0.48《t节点d3被剪枝。当检索到r4时,由于relevance(vq,r4)=0.5《t,
该节点和其子树d4及d2均被剪枝。根据该检索示例的对比可知,筛选因子能够提前筛去更多的子树,加速检索过程,同时保持检索结果不变。
[0064]
以上所述仅为本发明的优选方案,并非作为对本发明的进一步限定,凡是利用本发明说明书及附图内容所作的各种等效变化均在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1