一种超级计算机获取作业应用的方法、终端及存储介质
本发明涉及超级计算机,尤其涉及的是一种超级计算机获取作业应用的方法、终端及存储介质。
背景技术:
1、超级计算机是现代科技创新必不可少的重要基础设施,是支撑综合国力提升的国之重器。从实验科学、理论科学到计算科学再到数据科学,超级计算已经成为我们探索世界改造世界不可或缺的重要方式。超级计算在揭示生命与思维的奥秘、探索药物作用机理、发现和设计新材料、模拟新能源装置、灾害预测、流体仿真、探索物质与宇宙的未知领域、大规模数据挖掘、处理大规模复杂社交网络等领域发挥重大的作用,因此在超级计算机上的应用众多。据不完全统计,在高性能计算领域的应用类型数量就达到几百个,如果再加上ai应用,大数据应用,超级计算的应用类型数量可达上千种。
2、作为超级计算机的管理者(例如:国家级超级计算中心,大学或者研究机构的计算中心部门),掌握对超级计算机上的应用情况意义重大,它可作为计算中心研究支撑工作的重点,超级计算行业发展动向,也能作为下一代超级计算机研究的重要依据,例如:过去的一个季度,材料计算vasp应用使用的核时最多,那么对vasp应用投入增大(例如:增加人力,物力,财力);同时wrf应用的规模1000核占的比重最大,那么wrf相关的技术人员相应把研究重点发在wrf相关的天气预算尺度上面。
3、但是超级计算机的应用使用方式没有固定格式,例如:vasp应用,有的人使用vasp,有的人使用vasp_std,还有人使用vasp等等,有些应用根本是自行命名,例如:lbm应用,用户编译后,有人命名main,有人命名a,还有人命名allrun,因此统计应用情况之前,精准获取到每个作业的应用名称,是关键所在。超级计算的使用模式一般用户利用超级计算机账号登录超级计算机系统后,利用作业调度系统申请使用超级计算机的计算,存储和网络资源。用户利用作业调度系统是以作业队列的方式,进行使用超级计算机。即用户预先安装配置好应用软件以及运行的环境,设置好运算的模型,然后编写好作业提交脚本,然后提交作业,作业调度系统根据用户提交作业的资源申请,进行调度,然后投递作业到相关的计算节点上,作业在计算节点上启动运算,如果没有相关的计算资源,作业会进行等待。
4、目前对应商业软件,例如:abaqus应用,系统管理员会利用license限制条件,设置abaqus队列的方式,来识别作业的应用。即使用abaqus应用,只能选abaqus队列。但对于大部分的非商业的开源软件,或用户自行开发的软件,并没有相关对每个作业进行识别应用的方法。
5、因此,现有技术还有待改进。
技术实现思路
1、本发明要解决的技术问题在于,针对现有技术缺陷,本发明提供一种超级计算机获取作业应用的方法、终端及存储介质,以解决大部分非商业软件,或者用户自己开发的软件,由于应用名称不规范,版本多,或者应用类型多等多种原因,超级计算机上并没有相关对每个运行作业进行识别应用的方法,导致无法直接准确识别每一个作业应用的问题。
2、本发明解决技术问题所采用的技术方案如下:
3、第一方面,本发明提供一种超级计算机获取作业应用的方法,包括:
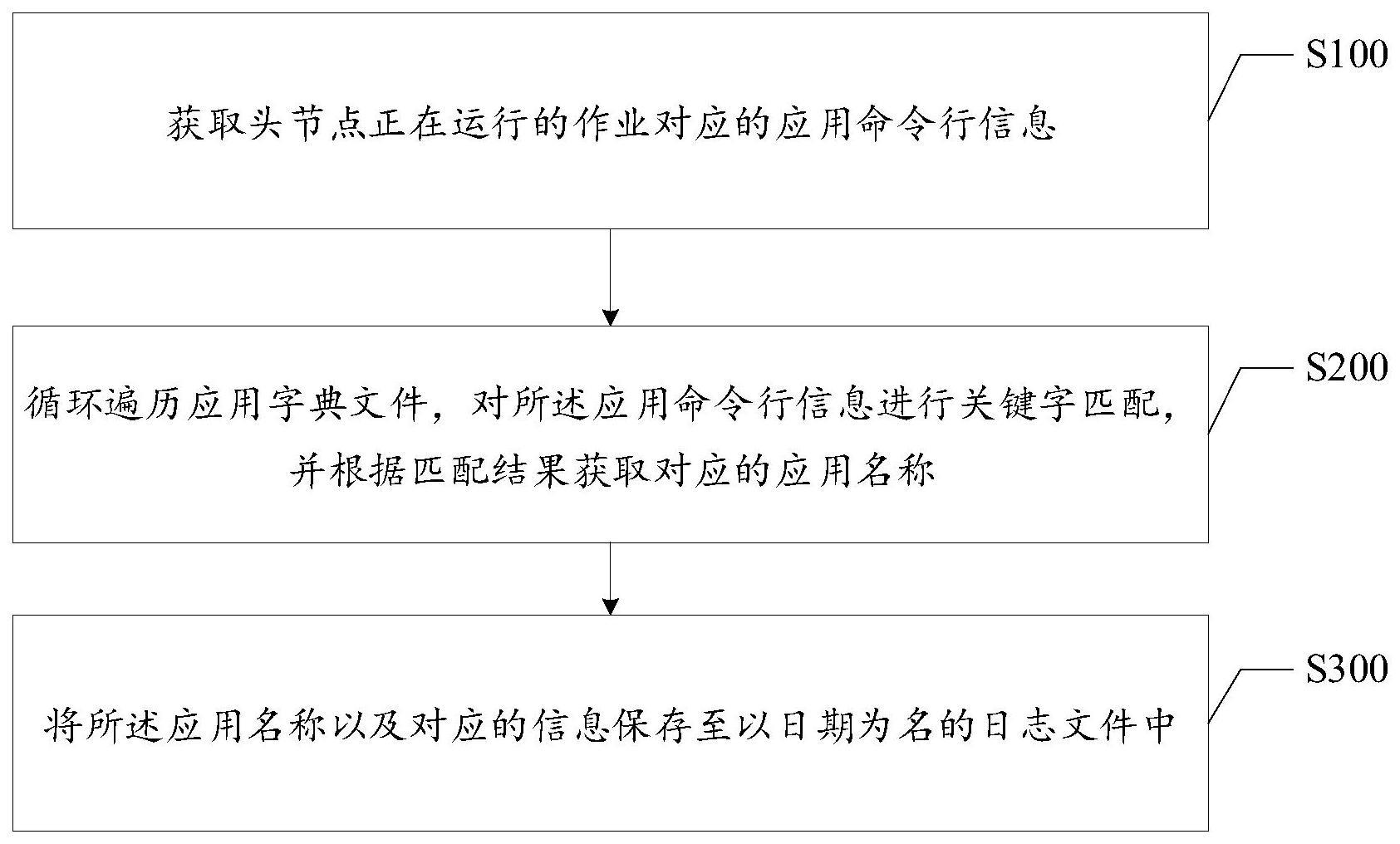
4、获取头节点正在运行的作业对应的应用命令行信息;
5、循环遍历应用字典文件,对所述应用命令行信息进行关键字匹配,并根据匹配结果获取对应的应用名称;
6、将所述应用名称以及对应的信息保存至以日期为名的日志文件中。
7、在一种实现方式中,所述获取头节点正在运行的作业对应的应用命令行信息,之前包括:
8、根据超级计算机上的预设应用,设置应用字典文件;其中所述应用字典文件包括:应用关键字和应用名称。
9、在一种实现方式中,所述获取头节点正在运行的作业对应的应用命令行信息,包括:
10、通过管理节点设置定时任务;
11、根据所述定时任务获取预设时间段内正在运行的作业号以及作业运行的头节点信息;
12、通过进程树命令在所述头节点信息对应的头节点上打印进程树信息;
13、根据所述进程树信息获取所述正在运行的作业对应的应用命令行信息。
14、在一种实现方式中,所述根据所述进程树信息获取所述正在运行的作业对应的应用命令行信息,包括:
15、判断所述进程树信息中是否存在以所述作业号加shell为关键字的命令行;
16、若存在以所述作业号加shell为关键字的命令行,则将以所述作业号加shell为关键字的命令行的下一行命令行信息作为所述正在运行的作业的应用命令行信息。
17、在一种实现方式中,所述判断所述进程树信息中是否存在以所述作业号加shell为关键字的命令行,之后还包括:
18、若不存在以所述作业号加shell为关键字的命令行,则将以所述作业号为关键字的命令行的下一行命令行信息作为所述正在运行的作业的应用命令行信息。
19、在一种实现方式中,所述循环遍历应用字典文件,对所述应用命令行信息进行关键字匹配,并根据匹配结果获取对应的应用名称,包括:
20、循环遍历所述应用字典文件,判断所述应用命令行信息是否存在与所述应用字典文件中应用关键字匹配的关键字符;
21、若不存在匹配的关键字符,则将所述应用命令行信息中的最后两列信息作为对应的应用名称。
22、在一种实现方式中,所述判断所述应用命令行信息是否存在与所述应用字典文件中应用关键字匹配的关键字符,之后还包括:
23、若存在匹配的关键字符,判断所述关键字符所对应的应用名称的数量是否为多个;
24、若为多个,则去除所述应用命令行信息中的python信息和anaconda信息,并将去除后的应用命令行信息的最后一列作为应用名称;
25、若为一个,则输出所述应用字典文件中对应的应用名称。
26、在一种实现方式中,所述将所述应用名称以及对应的作业信息保存至以日期为名的日志文件中,包括:
27、获取所述应用名称对应的执行任务时间;
28、获取所述应用名称对应的作业号、用户名以及头节点信息,并将所述执行任务时间、所述作业号、所述用户名以及所述头节点信息保存至所述以日期为名的日志文件中。
29、第二方面,本发明还提供一种终端,包括:处理器以及存储器,所述存储器存储有超级计算机获取作业应用的程序,所述超级计算机获取作业应用的程序被所述处理器执行时用于实现如第一方面所述的超级计算机获取作业应用的方法的操作。
30、第三方面,本发明还提供一种存储介质,所述存储介质为计算机可读存储介质,所述存储介质存储有超级计算机获取作业应用的程序,所述超级计算机获取作业应用的程序被处理器执行时用于实现如第一方面所述的超级计算机获取作业应用的方法的操作。
31、本发明采用上述技术方案具有以下效果:
32、本发明通过获取头节点正在运行的作业对应的应用命令行信息。在命令行信息里面通过应用字典文件匹配关键字,从而找到应用名称,解决了大部分非商业软件,或者用户自己开发的软件,由于应用名称不规范,版本多,或者应用类型多等多种原因,超级计算机上并没有相关对每个运行作业进行识别应用的方法,导致无法直接准确识别每一个作业应用的问题。
- 还没有人留言评论。精彩留言会获得点赞!