基于时空局部调和神经网络的视觉语言识别方法及应用
本发明涉及计算机视觉领域,具体来说是一种基于时空局部调和神经网络的视觉语言识别方法。
背景技术:
1、随着深度学习的发展,视觉语言识别也越来越受到人们的关注。视觉语言识别具体是指在没有说话者的音频信息下,只通过说话者的视觉图像“读出”或者“部分读出”其所说的文本内容。在实际生活中,人们在许多方面也对视觉语言任务提出需求,如辅助音频进行识别,公共安全上关键词识别,辅助听障人士的语言识别等等。随着机器学习发展,目前视觉语言识别已经超过了人类。
2、对于视觉语言识别来说,能提取出来更加具有辨识度的时空特征是很重要的,而现有的视觉语言识别网络对这一方面仍然存在一些缺陷,目前大部分视觉语言识别大多通过序列卷积结构的来进行特征提取,这种序列结构缺乏在时间和空间两个维度上合理地关联嘴唇的全局和局部信息,提取出来的特征在时空上不能平衡整体与局部的关系,影响时空特征的辨识度。
技术实现思路
1、本发明为了解决上述现有技术存在的不足之处,提出一种基于时空局部调和神经网络的视觉语言识别方法及应用,以期能解决现有的视觉语言识别方法对时间特征,空间特征提取能力不足,方法单一,不注重不同信息的差异性等问题,从而能在说话者姿态,语速变化频繁的场景中准确识别单词内容,进而为视觉语言识别提供了一种新的解决方法。
2、本发明为达到上述发明目的,采用如下技术方案:
3、本发明一种基于时空局部调和神经网络的视觉语言识别方法的特点包括如下步骤:
4、步骤1:数据预处理:
5、步骤1.1:获取带有单词标签的视觉语言数据集,并对其中的视频图像数据进行灰度化处理后,再对人脸关键点进行标定和对齐,使得人脸处于图像的中间位置处,从而得到人脸图像序列,记为p={p1,p2,...pi,...pn},pi表示第i帧人脸图像;n表示人脸图像的总数;
6、步骤1.2:对所述人脸图像序列p中每帧人脸图像的嘴唇区域进行大小为h×h的裁剪,并对裁剪后的嘴唇区域进行随机裁剪,从而得到大小为w×w的唇读序列,记为ps1={ps1,ps2,...psi,...psn};其中,psi表示第i帧人脸图像的唇读区域,w<h;
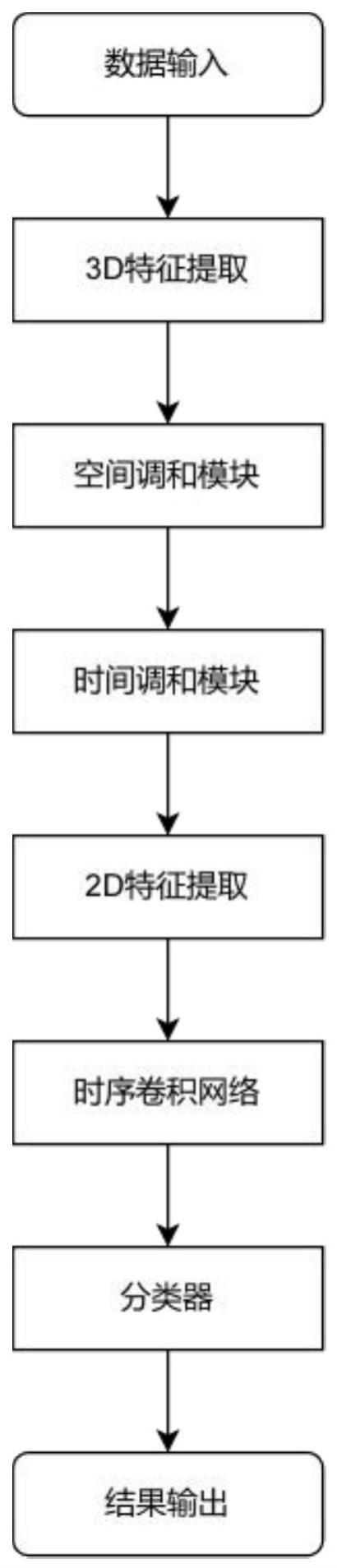
7、步骤2:构建基于时空局部调和神经网络的视觉语言识别模型,包括:3d时空特征提取模块、空间调和模块、时间调和模块、2d空间特征提取模块、时序卷积模块以及一个分类器;
8、步骤2.1:所述3d时空特征提取模块由nk个3d块依次串联组成,且每3d块由一个卷积层、一个bn层与relu激活函数依次串联而成;
9、所述唇读序列ps1输入所述3d时空特征提取模块中,并依次通过nk个块的处理后,得到时空特征fd={fd1,fd2,...fdi,...fdn},fdi为第i个人脸图像的唇读区域的3d时空特征;
10、步骤2.2:所述空间调和模块由nl个2d空间块以及可变形卷积组成,其中,任意第l个2d空间块由一个卷积核为xl×xl的卷积层、一个bn层与relu激活函数依次串联而成;nl为大于等于3的奇数;
11、步骤2.2.1:所述3d时空特征fd输入所述空间调和模块中,分别输入前2个2d空间块中进行处理后,相应得到时空特征f1c={f1c1,f1c2,...f1ci,...f1cn}与f2c={f2c1,f2c2,...f2ci,...f2cn},其中,f1ci,f2ci分别代表第i个3d时空特征通过第1个、第2个2d空间块后的2d时空特征;
12、将f1c,f2c在时间维度上进行连接后得到拼接时空特征fc={fc1,fc2,...fci,...fcn},fci为第i个拼接时空特征;
13、步骤2.2.2:若j=l,则所述拼接时空特征fc输入第nl个2d空间块中进行处理得到空间调和的偏移量,记为of={of1,of2,...ofi,...ofn},其中,ofi代表第i个空间调和的偏移量;否则,所述拼接时空特征fc继续步骤2.2.1的过程输入后续的2d空间块中进行处理;
14、再将时空特征fd与偏移量of一同输入到可变形卷积dcn中进行处理,并得到空间调和的时空特征fo={fo1,fo2,...foi,...fon},其中,foi为第i个空间调和后的时空特征;
15、步骤2.3:所述时间调和模块由nz个2d时间块以及可变形卷积组成,其中,任意第z个2d时间块由一个卷积核为xz×xz的卷积层、一个bn层与relu激活函数依次串联而成;
16、步骤2.3.1:空间调和的时空特征时空特征fo输入所述时间调和模块中,并利用式(1)得到第i个上下文时空特征fai,从而得到上下文时空特征fa={fa1,fa2,...fai,...fan}:
17、
18、式(1)中,fo,i-1为第i-1个调和后的时空特征;fo,i+1为第i+1个调和后的时空特征;
19、步骤2.3.2:将连接后得到的上下文时空特征fa依次前nz-1个2d时间块的处理后,得到级联时间调和,再经过第nz个2d时间块的处理后,得到时间调和的偏移量,记为sf={sf1,sf2,...sfi,...sfn},其中,sfi代表第i个时间调和的偏移量;
20、再将时空特征fo与偏移量sf一同输入到可变形卷积dcn中进行处理,并得到时间调和的时空特征fs={fs1,fs2,...fsi,...fsn},其中,fsi为第i个时间调和后的时空特征;
21、步骤2.4:所述2d空间特征提取由resnet-18的前四层残差块组成,且每个残差块依次包括两个卷积层、一个bn层和一个relu激活函数;
22、所述时间调和的时空特征fs输入所述2d空间特征模块中,并依次通过四层的残差网络块的处理后,得到残差时空特征fm={fm1,fm2,...fmi,...fmn},fmi为第i个残差时空特征。
23、步骤2.5:所述时序卷积模块由nv个残差块组成,其中,任意第v个残差块包含两层的时序卷积层和非线性映射层,每一层的时序卷积层连接一个bn层与relu激活函数;其中,任意第v个残差块中的时序卷积层的卷积核大小为xv×xv;
24、所述时空特征fm输入所述时序卷积模块中,并依次通过nv个残差块的处理后,得到时序卷积时空特征ft={ft1,ft2,...fxi,…ftn},fti为第i个时序卷积时序卷积特征;
25、步骤2.6:所述分类器由一个线性层与softmax函数组成;
26、所述时序特征ft输入所述分类器,并经过所述线性层后得到分布特征fq,再通过softmax函数得到概率分布pre;
27、步骤3:网络模型的训练:
28、根据概率分布pre与真实的单词标签计算kl散度并作为损失函数,通过梯度下降方法对所述视觉语言识别模型进行训练,并计算损失函数以更新模型参数,直至模型逐渐收敛为止,从而得到训练好的视觉语言识别模型,用于对任意输入的人脸图像识别其唇语单词。
29、本发明一种电子设备,包括存储器以及处理器,其特点在于,所述存储器用于存储支持处理器执行所述视觉语言识别方法的程序,所述处理器被配置为用于执行所述存储器中存储的程序。
30、本发明一种计算机可读存储介质,计算机可读存储介质上存储有计算机程序,其特点在于,所述计算机程序被处理器运行时执行所述视觉语言识别方法的步骤。
31、与现有技术相比,本发明的有益效果在于:
32、1.本发明通过在混合卷积特征提取阶段,通过构建空间调和模块与时间调和模块,从时间和空间两个维度上合理地关联嘴唇的全局和局部信息,提取出来在时空上能平衡整体与局部关系的时空特征,增强了特征的辨识度,有利于提高视听网络模型的准确性与鲁棒性。
33、2.本发明在空间调和模块,有效利用了可变形卷积的优点,通过传统卷积的方式,得到空间上整体与局部的相关性,并将其转化为offset偏移量的方式,引导卷积核的形变,提取出空间上整体信息与局部信息相平衡的空间特征,有效的提高了前端特征提取中关于空间信息提取的能力,有利于在说话者姿态变化频繁的场景中,提高了视听网模型的准确性。
34、3.本发明在时间调和模块,有效利用了时序信息上的短时相关性,通过传统卷积的方式,得到时间上当前时刻与其上下时刻的相关性,并将其转化为offset偏移量的方式,引导卷积核的形变,提取出短时上整体信息与局部信息相平衡的时间特征,有效的提高了前端特征提取中关于时间信息提取的能力,有利于视听网络模型适应说话者的语速,增加了识别的准确性。
- 还没有人留言评论。精彩留言会获得点赞!