一种自动识别关系型数据库表不同表数据间相似性的方法与流程
1.本发明属于数据治理技术领域,涉及一种自动识别关系型数据库表不同表数据间相似性的方法。
背景技术:
2.数据治理中数仓建设、主数据、元数据、参考数据及商务智能的过程中,往往需要对数据间相似性进行分析,如通过数据相似密度判定主数据、数据相似及基数判定表间关系、通过数据相似数据参考关系,摒弃传统依靠人工的方式便捷的进行相关数据治理工作。传统技术方案中,主要依靠字段命名规范、底层表主/外键关系、人工识别等方式来判别数据间相似度。在缺乏相应规范、底层表未标识主/外键、人员对于数据结构不清楚情况下,难以自动建立数据间关系、发现主数据和参考数据,从而使得数据治理工作量大,治理效果差,难以持续开展治理工作。
3.在数据治理中,往往需要实现建立表数据间关系,识别参考数据或主数据,传统方式一般采用人工识别,效率低下,且准确性低下,迫切需要一种手段来实现自动识别,实现以上目的。
技术实现要素:
4.本发明的目的是提供一种自动识别关系型数据库表不同表数据间相似性的方法,解决了现有技术缺乏相应规范、底层表未标识主/外键、人员对于数据结构不清楚情况下,难以自动识别关系型数据库表不同表数据间相似性问题。
5.本发明所采用的技术方案是,一种自动识别关系型数据库表不同表数据间相似性的方法,包括以下步骤:
6.步骤1、从关系数据库中提取表的表信息、列信息、列值信息并存储表信息字典t、列信息字典c及唯一值集合v;
7.步骤2、根据列值计数确定建立布隆过滤器列和过滤列,先从表信息字典中选择表的一列唯一值集合,再从其他表的列的唯一值集合,确定计数小的为过滤器列n,计数大的为过滤列m;
8.步骤3、采用布隆过滤算法,基于n的唯一值集合建立过滤器;
9.步骤4、将步骤3建立的布隆过滤器,传入m的唯一值集合,过滤值并记录返回集合r={r1,r2,r3,
…
rn:rε(true,false)};
10.步骤5、统计概率w=∑r{true}/(r{true|false}),当w》
ɑ
,
ɑ
为给定阈值,则判定m与n相似,否则不相似;
11.本发明的特点还在于:
12.步骤1包括以下步骤:
13.步骤1.1、从关系数据库中读取全部表信息,形成表信息字典并存储表信息字典t;
14.步骤1.2、对表的列信息列信息进行提取,并删除掉数值类型且非整数类型列,形
成表所属列信息字典并存储列信息字典c;
15.步骤1.3、对列值信息进行去重,形成唯一值集合v并统计计数再存储。
16.步骤2包括以下步骤:
17.步骤2.1、对于建立的表信息字典t,取任意表t1,再取t1的一列c1,记为n;
18.步骤2.2、对于建立的表信息字典t,取不重复第一步的任意表t2,再取t2的一列c2,记为m;
19.步骤2.3、根据n的唯一值计数与m的唯一值计数大小进行判定,计数小的用于建立布隆过滤器,计数大的用于使用过滤器。
20.步骤3包括以下步骤:
21.步骤3.1、创建一个m位bitset,先将所有位初始化为0;
22.步骤3.2、确定哈希函数个数,选择k个不同的哈希函数;
23.步骤3.3、选择哈希函数,第i个哈希函数对列值集合中的每一个值进行哈希,结果记为h(i,value),且h(i,value)的范围是0到m-1。
24.步骤4包括以下步骤:
25.步骤4.1、传入待过滤的唯一值集合,使用建立的布隆过滤器过滤值
26.步骤4.2、统计传入值得k各哈希函数返回值,所有返回值为1,则记录为true,否则为false;
27.步骤4.3、将所有结果记录为集合{r,rε(true,false)}。
28.还包括有步骤6、重复步骤2到5,完成所有表的所有列相似性判定,最终生成全部表间列相似计算。
29.本发明的有益效果是:
30.1、本发明无需依赖任何人为规则、人工判断、预定义说明,实现智能化表数据相似性分析。
31.2、本发明可以通过判别表关联的相似性数量,实现主数据智能识别。
32.3、本发明可以通过判别表关联的相似性数据结合数据唯一值特性方向,实现表间关系识别。
33.4、本发明可以通过判别表关联的相似性数据结合数据唯一值特性多少,实现表列参考数据识别。
附图说明
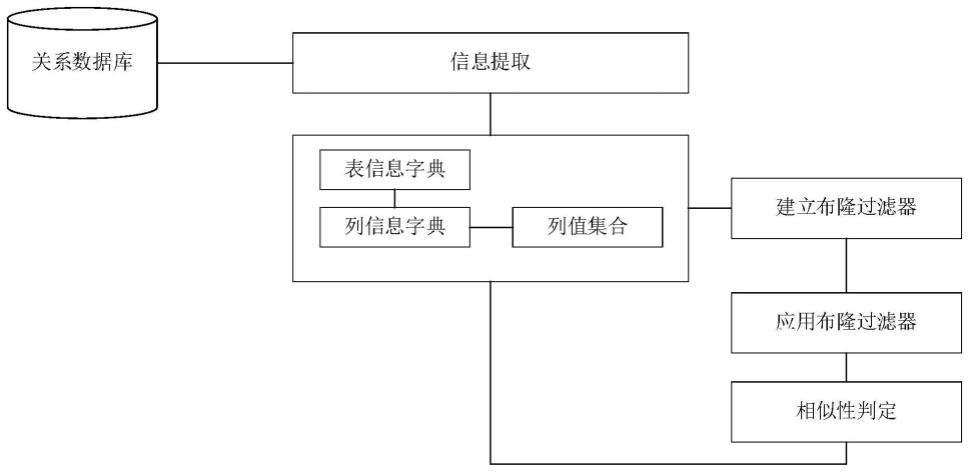
34.图1是本发明一种自动识别关系型数据库表不同表数据间相似性的方法的流程图。
具体实施方式
35.下面结合附图和具体实施方式对本发明进行详细说明。
36.在数据治理中,往往需要实现建立表数据间关系,识别参考数据或主数据,传统方式一般采用人工识别,效率低下,且准确性低下,迫切需要一种手段来实现自动识别,为了实现以上目的,本发明提出了一种自动识别数据相似性的方法,通过识别数据相似性,可满足业务需求。
37.本发明一种自动识别关系型数据库表不同表数据间相似性的方法的流程图,如图1所示。
38.步骤1、需要从关系数据库中通过采集方式定期提取表信息、列信息、列值信息并进行去重和取除非整数数值列处理,在对处理后的唯一值进行数,对以上处理后的数据进行存储,形成表信息字典t,列信息字典c,唯一值集合v数据和统计计数v。
39.其中表信息字典t(表id,表名称,表说明),c(列id,表id,列名称,列类型,列说明),唯一值集合v(列id,值),上述信息字典的项目根据实际增加或者替换为其他项目。
40.以上字典及集合建立后存储到存储介质中。在完成以上操作基础上,建立确定插入列和过滤列,即进行步骤2,按照以下步骤实施:
41.步骤2.1、从表信息字典t中取任意表t1,在从表对应的列信息字典c中取任意列c1及列对应的唯一值集合v1;
42.步骤2.2、从表信息字典t中取排除已取表的任意表t2,在从表对应的列信息字典c2中取任意列及列对应的唯一值集合v2;
43.步骤2.3、统计步骤2.1和步骤2.2中索引列值集合大小,计数小的确定为插入列,计数大的用于过滤列。
44.在完成以上判断的基础上,定义插入列计数值为插入的元素个数n;设定误判率p的值为0.01,进行步骤3、开始建立布隆过滤器,包括以下步骤:
45.步骤3.1、计算过滤器长度m,p为误判率;
46.步骤3.2、计算哈希函数个数k,
47.步骤3.3、创建一个m位bitset,先将所有位初始化为0;
48.步骤3.4、确定哈希函数个数,这里选择k个不同的哈希函数;
49.步骤3.5、选择哈希函数,第i个哈希函数对插入元素中的每一个值进行哈希,结果记为h(i,value),且h(i,value)的范围是0到m-1;
50.完成以上操作布隆过滤器构建完成,下来可以使用已经完成的布隆过滤器来过滤数据得到判定集合,步骤4按照以下步骤实施:
51.步骤4.1、传入待过滤的唯一值集合,使用建立的布隆过滤器过滤值
52.步骤4.2、统计传入值得k各哈希函数返回值,所有返回值为1则记录为true,否则为false;
53.步骤4.3、将所有结果记录为集合{r,rε(true,false)}。
54.步骤5、现在得到数据相似性判定集合r,在得到集合r后,需要计算判定概率并根据计算概率判定相似性,其中统计概率w=∑r{true}/(r{true|false}),当w》
ɑ
(
ɑ
为给定阈值,
ɑ
=1-p,p为误判率)则判定插入数据和过滤数据相似,否则不相似。
55.步骤6、最后,重复确定插入列和过滤列到相似性概率统计过程,完成所有表的所有列相似性判定,最终生成全部表数据间列关相似计算。
56.实施例1
57.第一步,连接数据库,并分析库元数据,并从中提起表信息,形成表信息字典。
58.表id表名称表描述101order订单表
102customer客户表103product产品表
59.在提取表信息后,基于表信息从数据库元信息中提起表的列元数据信息,形成列信息字典。
60.1、订单字典
61.表id列id列名称列类型类描述1011idint订单id1012namevarchar2订单名称1013qtydouble订单数量1014pricedouble订单价格1015cid客户id客户id
62.2、客户字典
63.表id列id列名称列类型类描述1021idint客户id1022namevarchar2客户名称1023addressdouble客户地址1024typedouble客户类别
64.在提取列信息后,基于列信息从数据库元信息中提起表的列数据唯一值,并形成列值字典。
65.1、订单表客户id列值字典
66.列id值51525354
67.2、客户表客户id列值字典
68.列id值11121314
69.第二步,在完成以上数据字典建立后,选择订单字典表的订单客户id列与客户字典表的id列。
70.首先对列值统计计数大小进行分析,计数小的值所对应列值用于建立过滤器,计数大的使用过滤器;
71.其次,设定误判率p的值为0.01,表示允许1%的误判;计算过滤器长度m,其中计算哈希函数个数k,其中创建一个m位bitset,先将所有位初始化
为0;确定哈希函数个数,这里选择k个不同的哈希函数;
72.最后,根据以上定义建立过滤器,其中选择哈希函数,第i个哈希函数对插入元素中的每一个值进行哈希,结果记为h(i,value),且h(i,value)的范围是0到m-1,通过以上选择建立布隆过滤器。
73.此案例中选择客户字典表的id列值来建立过滤器,使用订单字典表的订单客户id列值来使用过滤器。
74.第三步,将订单字典表的订单客户id列值,传入建立的布隆过滤器进行过滤,统计传入值得k各哈希函数返回值,所有返回值为1则记录为true,否则为false,将所有结果记录进行判定,在给定阈值范围内判定插入数据和过滤数据相似,否则不相似。此例中判定客户字典表的id列值和订单字典表的订单客户id列值相似。
75.第四步,重复过程二到三,取不同的表和列,使用值结合完成所有表的所有列相似性判定,最终生成全部表数据间列关相似计算。
76.本发明一种自动识别关系型数据库表不同表数据间相似性的方法的流程图,其优点在于:
77.本发明通过自动提起关系数据库中提取表信息、列信息、列值集合和列值计数,再通过基于列值建立的布隆过滤器,对其他列值数据进行过滤,通过统计返回值得概率,实现数据间相似性判定,此发明无需依赖任何人为规则、人工判断、预定义说明,实现对于大规模数据表数据间的智能化相似性分析,可以用于参考数据分析、主数据发现、数据表间关系发现。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1