一种使用句法信息的受控文本生成方法
1.本发明涉及受控场景的文本生成领域,具体涉及一种使用句法信息的受控文本生成方法。
背景技术:
2.受控文本生成指的是生成满足某种条件(例如长度、句式、固定格式等)的文本。在特定情况下,某些文本生成场景会要求输出的文本与输入的文本之间存在一定的形式上的对应关系,例如对联中下联的生成。现有的方法往往采用标准的序列到序列的文本生成方法,缺乏对这种受控条件(例如形式上的对应关系)的有效建模,使得模型生成的文本无法满足预设的受控条件。
3.本发明提出一种利用句法信息的受控文本生成方法,使用注意力模块对输入文本中的句法信息建模,使用句法信息帮助指导受控条件下的文本生成。
技术实现要素:
4.为解决上述技术问题,本发明提供一种使用句法信息的受控文本生成方法。
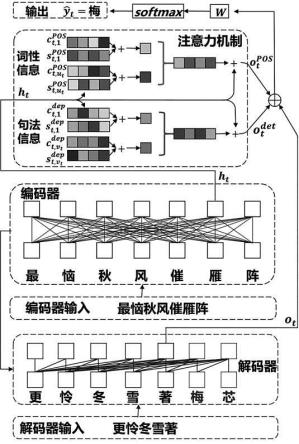
5.为解决上述技术问题,本发明采用如下技术方案:一种使用句法信息的受控文本生成方法,用于通过给定的输入文本,以及时刻t已输出文本,预测受控条件下当前时刻t的下一个输出字;其中文本即字序列;时刻t前已输出文本中,字在时刻1时输出,字在时刻2时输出,字在时刻t-1时输出,故本发明中,t既能表示时刻,也能作为字序列标识;具体包括以下步骤:步骤一:使用transformer编码器对输入文本编码,得到输入文本中每个字的隐向量,其中,transformer编码器含有多层结构,输入文本第个字在第层的隐向量记为;步骤二:把作为transformer编码器第层的输入,输出为,重复地将上一层的输出作为下一层的输入,直至得到transformer编码器所有层输出的隐向量,,其中是transformer编码器总的层数,输入文本中第t个字在transformer编码器最后一层中对应输出的隐向量记为,;
步骤三:将隐向量,以及抽取得到的与输入文本第t个字相关的词性知识和句法知识,送入注意力模块进行注意力机制计算,分别得到包含词性知识的词性向量以及包含句法知识的句法向量;其中,与字相关的词性知识和句法知识均为一个列表,该列表中的每个元素均由一对上下文特征和句法知识实例组成:,其中是元素的总数;为第j个元素的上下文特征,为第j个元素的句法知识实例;,其中是元素的总数,为第j个元素的上下文特征,为第j个元素的句法知识实例;步骤四:将transformer编码器所有层输出的隐向量,以及时刻t已输出文本,输入transformer解码器,得到解码器输出的向量;步骤五,将词性向量、句法向量、解码器输出的向量串联后,依次经过一个全连接层以及softmax分类器,得到当前时刻t的下一个输出字。
6.具体地,步骤三中抽取与输入文本第t个字相关的词性知识时,包括以下步骤:步骤三a1:使用自然语言处理工具,获取输入文本的词性标注;步骤三a2:选取字周围半径为r个字的范围内的所有词;步骤三a3:将词作为第j个元素的上下文特征,将词对应的词性标签作为第j个元素的句法知识实例,从而构建;步骤三a4:收集每个词对应的,形成。
7.具体地,步骤三中抽取与输入文本第t个字相关的句法知识时,包括以下步骤:步骤三b1:使用自然语言处理工具获取输入文本的依存句法树;
步骤三b2:选取所有与字存在直接句法关系的词;步骤三b3:将词作为第j个元素的上下文特征,词与字之间的依存句法关系类型作为第j个元素的句法知识实例,从而构建;步骤三b4:收集每个词对应的,形成。
8.具体地,所述注意力模块包括词性信息建模模块;步骤三中进行注意力机制计算得到词性向量时,包括以下步骤:步骤三c1:在词性信息建模模块,使用上下文特征向量矩阵把上下文特征映射为向量;使用词性特征向量把映射为向量;将向量和向量相加,得到向量;步骤三c2:使用隐向量和向量,计算权重:;其中,
“”
计算向量内积;步骤三c3:基于权重计算向量的加权平均向量:;其中,
“”
计算权重与向量的乘积;步骤三c4:把加权平均向量与隐向量做向量加法,得到词性信息建模模块输出的词性向量。
9.具体地,所述注意力模块包括句法信息建模模块;步骤三中进行注意力机制计算得到句法向量时,包括以下步骤:步骤三d1:在句法信息建模模块,使用上下文特征向量矩阵把上下文特征映射为向量;使用词性特征向量把映射为向量;将向量和向量相
加,得到向量;步骤三d2:使用隐向量和向量,计算权重:;其中,
“”
计算向量内积;步骤三d3:基于权重计算向量的加权平均向量:;其中,
“”
计算权重与向量的乘积;步骤三d4:把加权平均向量与隐向量做向量加法,得到句法信息建模模块输出的句法向量。
10.与现有技术相比,本发明的有益技术效果是:本发明对输入中的每个字,通过注意力模块,利用与其关联的句法知识的表征,从而增强模型对文本生成过程中的受控特征的理解,从而提升生成的受控文本的质量。
11.另外,本发明通过公式(1)对不同的句法知识特征加权,实现了对不同句法知识特征的重要性的识别和利用,有效避免了句法知识特征中潜在的噪音对模型性能的影响。
附图说明
12.图1为本发明的模型结构图;图2为本发明实施例中词性标注的示意图;图3为本发明实施例中依存句法树的示意图。
具体实施方式
13.下面结合附图对本发明的一种优选实施方式作详细的说明。
14.本发明的模型结构如图1所示。给定输入文本(字序列),以及t时刻已经输出的文本(字序列),预测受控条件下当前时刻t的下一个输出字。
15.时刻t前已输出文本中,字在时刻1时输出,字在时刻2时输出,字
在时刻t-1时输出,故本发明中,t既能表示时刻,也能作为字序列标识。
16.本发明采用了标准的基于transformer的编码-解码架构。本发明的创新点在于,使用注意力模块(图1的右上角)对编码器输入中对应位置字的句法信息建模,从而利用这些句法信息指导模型预测。
17.在时刻t,模型预测字的流程如下:步骤一:使用transformer编码器对输入文本编码,得到输入文本中每个字的隐向量,其中,transformer编码器含有多层结构,输入文本第个字在第层的隐向量记为。
18.步骤二:把作为transformer编码器第层的输入,经过该层编码后得到,不断重复这一过程,直至得到transformer编码器所有层输出的隐向量,,其中是transformer编码器总的层数。为表述方便,输入文本中第t个字在transformer编码器最后一层中对应输出的隐向量记为,。
19.步骤三:将步骤二中得到的隐向量,以及抽取得到的与字相关的词性知识和句法知识,送入注意力模块进行注意力机制计算,分别得到包含词性知识的词性向量以及包含句法知识的句法向量;其中,与字相关的词性知识和句法知识均为一个列表,该列表中的每个元素均由一对上下文特征和句法知识实例组成:,其中是元素的总数;为第j个元素的上下文特征,为第j个元素的句法知识实例;,其中是元素的总数,为第j个元素的上下文特征,为第j个元素的句法知识实例。
20.步骤四:将步骤二中得到的所有层输出的隐向量,以及时刻t已输出文本,输入transformer解码器,得到解码器输出的向量。
21.步骤五,将步骤三得到的词性向量、句法向量,和步骤四得到的解码器输出的向量串联后,依次经过一个全连接层以及softmax分类器,得到模型的输出,即当前时刻t的下一个输出字。
22.具体地,抽取的过程如下:步骤三a1:如图2所示,使用现有的自然语言处理工具,获取输入文本的词性标注;图2中,ad表示副词,vv表示动词,nn表示名词。图2中每个词的词性标注结果展示在词的下方。
23.步骤三a2:选取字周围半径为r个字的范围内的所有词。例如,当t=2,r=2时,为“恼”,半径内所有词为“最”、“恼”、“秋风”。
24.步骤三a3:将词作为第j个元素的上下文特征,将词对应的词性标签作为第j个元素的句法知识实例,从而构建。
25.步骤三a4:收集每个词对应的,形成;例如,包含(最,ad),(恼,vv),(秋风,nn)。
26.具体地,抽取的过程如下:步骤三b1:如图3所示,使用自然语言处理工具获取输入文本的依存句法树;图3中,advmod表示状语修饰语,root表示根节点,dep表示无法确定两个词之间的更精确的依赖关系,nsubj表示名词主语,dobj表示直接宾语。
27.步骤三b2:选取所有与字存在直接句法关系的词。例如,当t=2时,存在直接句法关系的词为“最”、“催”。
28.步骤三b3:将词作为第j个元素的上下文特征,词与字之间的依存句法关系类型作为第j个元素的句法知识实例,从而构建。
29.步骤三b4:收集每个词对应的,形成;例如,包含(最,advmod),(催,dep)。
30.下面是注意力机制的计算过程,注意力模块包括词性信息建模模块和句法信息建模模块两部分:步骤三c1:在词性信息建模模块,使用上下文特征向量矩阵把上下文特征映
射为向量;使用词性特征向量把映射为向量;将向量和向量相加,得到向量。
31.步骤三c2:使用隐向量和向量,计算权重:;(1)其中,
“”
计算向量内积。
32.步骤三c3:基于权重计算向量的加权平均向量:;其中,
“”
计算权重与向量的乘积。
33.步骤三c4:把加权平均向量与隐向量做向量加法,得到词性信息建模模块输出的词性向量。
34.在句法信息建模模块,使用和,重复步骤三c1至步骤三c4的过程,得到句法信息建模模块输出的句法向量,具体如下:步骤三d1:在句法信息建模模块,使用上下文特征向量矩阵把上下文特征映射为向量;使用词性特征向量把映射为向量;将向量和向量相加,得到向量。
35.步骤三d2:使用隐向量和向量,计算权重:;其中,
“”
计算向量内积。
36.步骤三d3:基于权重计算向量的加权平均向量:
;其中,
“”
计算权重与向量的乘积。
37.步骤三d4:把加权平均向量与隐向量做向量加法,得到句法信息建模模块输出的句法向量。
38.对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内,不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
39.此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立技术方案,说明书的这种叙述方式仅仅是为了清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1