目标检测方法和装置与流程
本技术实施例涉及全屋智能领域,尤其涉及一种目标检测方法和装置。
背景技术:
1、在家庭场景下实现全屋智能的关键是智能跟人走,其核心问题是如何能在确保数据隐私安全的前提下,实现家庭成员的存在性检测以及身份、动作的识别。相关做法是通过毫米波雷达实现动态目标的检测,但识别精度差,无法区分目标身份和动作,并且对家庭场景的静态目标无法感知。
2、基于此,业界发展趋势是引入深度传感器,例如,深度相机,可以获取家庭场景点云数据,相较于毫米波雷达,其精度更高,能获取视野感知范围内的所有目标表面点云数据。结合rgb数据或者深度图数据,从点云数据中提取人体目标对象,来维护人体目标状态,确保目标在视野内被连续感知的状态一致性。
3、但是,rgb数据或者深度图数据都不能满足全屋智能的隐私安全要求。
技术实现思路
1、本技术提供一种目标检测方法和装置,可以满足全屋智能的隐私安全,并实现智能跟人走。
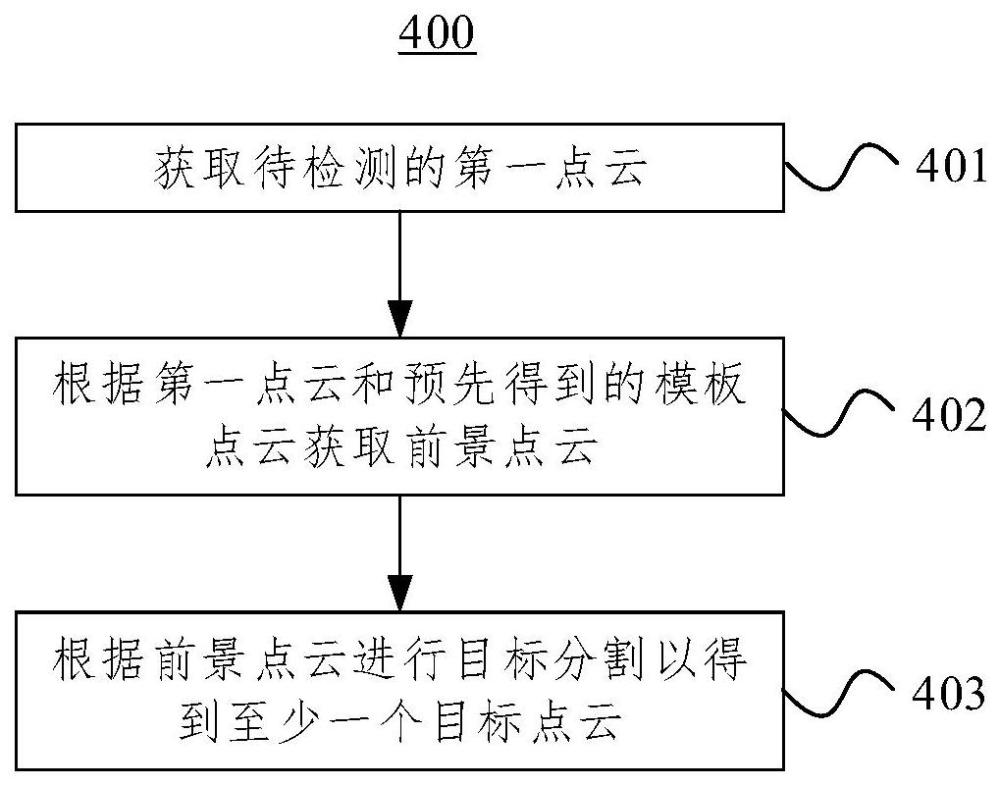
2、第一方面,本技术实施例提供一种目标检测方法,包括:通过深度传感器采集的场景图像获取待检测的第一点云;根据所述第一点云和预先得到的模板点云获取前景点云,所述前景点云反映了所述第一点云与所述模板点云之间的差异;根据所述前景点云进行目标分割以得到至少一个目标点云,一个所述目标点云对应一个目标对象。
3、本技术实施例,通过深度传感器采集室内的场景图像,并基于该场景图像获取点云,这样可以满足全屋智能的隐私安全;将待检测的点云与预先得到的模板点云进行比对,得到至少一个目标点云,其中一个目标点云可以对应一个目标对象,基于此可以根据数据库中的人物信息对目标对象执行相应的全屋智能操作,实现智能跟人走。
4、点云(point cloud),是某个坐标系下的点的数据集。其包含了丰富的信息,例如,点的三维坐标(x,y,z)、颜色、分类值、强度值等信息。使用密集的点云可以还原三维的现实世界。点(point),是组成点云的任意一个点。一个点云是由多个点组成,用于表示三维目标的数据结构。
5、点云可以基于图像得到,例如,点云可以基于深度传感器(例如深度相机)生成的深度图获取,或者,点云也可以通过双目相机或者3d激光雷达传感器等获取。本技术实施例对点云的获取方式不做具体限定。
6、上述第一点云是基于深度传感器当前采集到的场景图像得到的。在全屋智能应用场景下,传感器可以基于预先设定,周期性地或者触发性地对场景内拍照,采集场景内的场景图像。例如,周期性拍照时,可以预先设定周期(例如每个1小时)和/或起止时间(例如晚7点至9点);触发性拍照时,可以结合毫米波雷达,在监测到场景内有动态物体时才拍照。
7、本技术实施例可以采用深度传感器采集场景图像,由于深度传感器采集的图像非rgb图像,而是深度图,每个像素存储的值是距离,恢复成点云后,可以直接进行加密变化,在硬件端即可处理完,不涉及数据外泄,相较于rgb图像不包含隐私信息,更符合安全需求。
8、模板点云可以作为参考背景使用,其中不包含动态物体,例如,人、动物等,因此在设置采集模板点云对应的场景图像的时刻时,可以考虑大概率场景内没有动态物体的时刻,这样模板点云可以只包含场景内的静态物体,例如,家具、家电等。基于此,可以采用以下两种方法获取模板点云:
9、第一种:在预设时间段内采集场景图像;根据场景图像获取模板点云。
10、预设时间段可以是通常认为的场景内没有动态物体的时间段。例如,半夜、凌晨等时段,这时候通常人或动物都在睡觉,客厅、厨房等场景很可能只有静态物体;又例如,白天等时段,这时候通常人或动物在客厅、书房活动,卧室等场景内可能只有床、衣柜、书桌等静态物体。
11、需要说明的是,本技术实施例希望在预设时间段尽可能采集到不包含动态物体的场景图像,进而得到不包含动态物体的模板点云,因此才会如上述示例设置预设时间段,但这并非是构成限定,也可以根据场景内的具体情况,设置预设时间段,对此不做具体限定。
12、此外,不排除在预设时间段内,在场景内出现动态物体的情况,因此可以采用周期性采集的方式,即在预设时间段内,每间隔一段时间采集一次场景内的图像,进而获取对应的点云,将相邻采集时刻的两个点云进行比较,如果二者差异不大(例如,两个点云中大量点的欧氏距离较小,这些都可以通过阈值将其量化,对此不再赘述),则认为这两个点云所对应的场景内变化不大,那么将最新的一个点云当做模板点云;而如果二者差异较大,可以再比较之后的点云,剔除掉差异较大的点云(通常可以认为该点云包含动态物体),将最新的一个点云当做模板点云。
13、第二种:当毫米波雷达在预设时长内没有检测到动态目标时,采集场景图像;根据场景图像获取模板点云。
14、该方法结合了毫米波雷达的监测动态物体的特性,即当毫米波雷达在预设时长内没有检测到动态目标时,可以认为场景内没有动态物体,此时采集场景图像可以认为该场景图像中不包含动态物体,进而基于该场景图像得到的点云也不包含动态物体,可以将该点云当做模板点云。
15、在一种可能的实现方式中,为了提高模板点云的准确率,尽可能的在模板点云中只包含场景内的静态物体而不包含动态物体,可以对场景图像进行识别,即:
16、当场景图像相较于历史场景图像的变化程度小于或等于第三阈值时,根据场景图像获取模板点云;或者,当场景图像相较于历史场景图像的变化程度大于第三阈值时,丢弃场景图像。
17、历史场景图像可以是上一次预设时间段,例如,前一天的半夜,通过传感器采集得到的场景内的图像;或者,历史场景图像也可以是上文提到的在预设时间段内周期性采集的场景图像,其早于当前时刻。本技术实施例中,历史场景图像可以是上一个模板点云的获取图像,即,在当前获取模板点云之前,存储的最后一个模板点云所对应的场景图像。
18、场景图像相较于历史场景图像的变化程度可以是指二者之间的相似性,也可以是指二者直方图的变化度,其目的是衡量场景图像和历史场景图像之间的差异大小,如果二者变化较大,则表示场景内的物体变化较大,不适宜用作模板点云的获取,直接丢弃该场景图像;如果二者变化较小,则表示场景内的物体变化较小,可以用作模板点云的获取,根据该场景图像获取最新的模板点云。
19、上述前景点云反映了第一点云与模板点云之间的差异。其获取方法可以包括:获取第一点云和模板点云之间的至少一组对应点对,该对应点对包括第一点和第二点,其中,第一点为来自第一点云的一个点,第二点为来自模板点云的一个点,第一点和第二点满足预设相似条件;再从第一点云中将上述至少一组对应点对中的第一点删除以得到前景点云。
20、上述预设相似条件可以包括以下条件中的至少一个:
21、(1)第一点和第二点的欧式距离小于第一阈值;以及,
22、(2)第一点对应的曲率和第二点对应的曲率之差小于第二阈值。
23、即,对第一点云建立搜索树,例如kd tree,对模板点云也预先建立kd tree,以便于快速检索目标点。遍历第一点云的kd tree中的点,每个点在模板点云中确定出最接近的点。以第一点云中第i个点为例,该第i个点的最接近的点的度量方法可以采用欧式距离或者曲率,其中,
24、计算第i个点与模板点云中的各个点的欧式距离,将欧式距离小于第一阈值(例如0.1)对应的点确定为第i个点的最接近的点,这两个点构成一对对应点对。或者,
25、计算第i个点周围半径r内的点云集合ps_i的曲率ρi,曲率ρi可以是一种对第i个点及其周围的点的一种描述。可以计算ps_i点云集合的协方差矩阵tcov,维度为3*3,对tcov进行奇异值分解(singular value decomposition,svd)分解,生成lammda1、lammda2、lammda3三个特征值,分别对应点云的xyz三个方向,获取最大特征值对应的特征向量的方向nm,同时计算nm和重力方向ng的角θi,通过计算(lamda3-lamda2)/lamda3得到曲率ρi。将曲率ρi小于第二阈值(例如0.9)对应的两个点确定为对应点对。
26、通过上述方法可以得到至少一组对应点对,每组对应点对包括两个点(第一点和第二点),其中,第一点为来自第一点云的一个点,第二点为来自模板点云的一个点,亦即,对应点对代表了第一点云和模板点云中具有相似性的两个点。如上所述,模板点云作为参考背景使用,其包含了场景内的静态物体,基于此,同一场景内,第一点云中与模板点云相似的点可以认为也是代表静态物体的,第一点云中与模板点云不相似的点可以认为代表的不是静态物体,即为动态物体。因此从第一点云中将上述至少一组对应点对中的第一点(第一点云中可以在模板点云中找到相似的第二点的点)删除,第一点云剩余的点是在模板点云中没有相似的点的点,这些剩余的点构成前景点云。如前所述,前景点云可以认为代表了场景内的动态物体。
27、需要说明的是,从第一点云中将上述至少一组对应点对中的第一点(第一点云中可以在模板点云中找到相似的第二点的点)删除后,可能会出现一种情况,即第一点云剩余的点较少,例如点数小于设定阈值,此时认为剩余的点不足以构成代表目标对象的点云,则不再执行后续步骤,可以再次回到步骤401重新获取待检测的点云。
28、场景内的动态物体可以包括一个单独的个体,也可以包括多个单独的个体,还可以包括多个靠近的个体,那么为了实现“智能跟人走”,需要先把单独的个体识别出来。亦即,对前景点云进行目标分割以得到至少一个目标点云,其中,一个目标点云对应一个目标对象(例如,人)。需要说明的是,前述一个目标对象是机器所识别出来的一个目标对象,而非人的主观意识所认为的一个目标对象,亦即,如果机器识别后将两个紧靠的个体当做一个目标对象,那么即使人的主观上知道这是两个目标对象,也被覆盖于前述一个目标对象的范围内。
29、本技术实施例可以根据前景点云确定主方向;再根据前景点云和主方向确定目标点云的数量;然后根据目标点云的数量对前景点云进行分割以得到至少一个目标点云。
30、示例性的,根据前景点云得到协方差矩阵并进行svd分解,得到xyz三个方向的特征值(lammda1、lammda2、lammda3)和特征向量,选最大特征值对应的特征向量作为主方向(nm)。原则上,主方向在单人或多人站/坐情况下,与重力方向(ng)的夹角非常小,例如10°以内。
31、当主方向与重力方向接近平行时,可以认为目标对象是站或坐;当主方向与重力方向接近垂直时,可以认为目标对象是躺。不满足前述情况时,可以认为前景点云是多人组合的点集做进一步处理。选择与重力方向垂直的特征向量作为参考方向,先计算参考方向上,某一设定高度所对应的横截面距离分布,通过对比与单人的分布(离线训练如iforest/svm分类器,或者基于点云的深度学习进行特征编码)确定目标人数,对于低于阈值的点集不进行处理。确定目标人数后,将点集沿着参考方向均分对应人数部分,然后选择重力方向最远距离的点作为初始种子点进行生长,保留该距离半径内的点作为同类别。通过方向一致性判断关键种子点,关键种子点之后的点只沿着重力方向进行生长。计算种子点邻域l内的曲率ρ=(lamda3-lamda2)/lamda3。直到点数小于阈值则停止生长。这样可以实现对前景点云的分割,从而得到与目标人数对应个数的目标点云。
32、在得到至少一个目标点云之后,可以将至少一个目标点云与数据库中的点云进行比对,数据库中的点云为预先已配置人物信息的点云;当任意一个目标点云与数据库中的点云匹配上时,根据数据库中的点云的人物信息执行相应的全屋智能操作。
33、用户可以在全屋智能的初始化阶段,输入常用用户的信息,包括姓名、性别、年龄、身高、体重、生活习惯等,而生活习惯又可以包括对室内温度/湿度的偏好、喜欢的音乐/电视/电影、灯光明亮度的偏好等等。这些信息后可以这些信息存入数据库后,可以以“人”为单位建立人物信息,进而可以操控全屋智能实现智能跟人走。数据库中的点云可以是根据用户的性别、年龄、身高、体重等外貌特征生成的,例如数据库中的初始点云;或者,数据库中的点云可以是基于传感器之前采集的场景图像,使用上述过程400的步骤得到的目标点云。需要说明的是,数据库中的点云也可以采用其他方法得到,本技术实施例对此不做具体限定。
34、在一种可能的实现方式中,可以获取待检测的第二点云;根据第二点云和第一点云获取与第一目标点云关联的第二目标点云,第一目标点云是至少一个目标点云中的任意一个,第二目标点云来自于第二点云。
35、第二点云可以是基于传感器采集到的场景图像得到的,第二点云对应的场景图像是在上述第一点云对应的场景图像之后采集的。
36、通过计算与第一点云的至少一个目标点云中的任意一个目标点云的相似性以得到第二目标点云。即,使用上述过程400的步骤,也可以从第二点云中得到至少一个目标点云,采用遍历的方式,将第二点云的至少一个目标点云与第一点云的至少一个目标点云两两比对,确定出相似的两个目标点云,相似性可以参照上述步骤402的描述,此处不再赘述。这样,第二目标点云与第一目标点云关联起来,实现目标对象的一致性跟踪。当获取到多个相似的目标点云时,可以通过相同的标识将该多个目标点云关联起来,进而得到该目标点云所对应的目标对象的行为和轨迹。
37、此时,在得到第二目标点云之后,可以将第二目标点云与数据库中的点云进行比对;当第二目标点云与数据库中的点云匹配上时,根据数据库中的点云的人物信息执行相应的全屋智能操作。
38、同理,当第二目标点云与数据库中的点云匹配上时,可以基于上文描述,操控全屋智能实现智能跟人走。
39、第二方面,本技术实施例提供一种目标检测装置,包括:获取模块,用于获取待检测的第一点云;提取模块,用于根据所述第一点云和预先得到的模板点云获取前景点云,所述前景点云反映了所述第一点云与所述模板点云之间的差异;分割模块,用于根据所述前景点云进行目标分割以得到至少一个目标点云,一个所述目标点云对应一个目标对象。
40、在一种可能的实现方式中,所述提取模块,具体用于获取所述第一点云和所述模板点云之间的至少一组对应点对,所述对应点对包括第一点和第二点,所述第一点为来自所述第一点云的一个点,所述第二点为来自所述模板点云的一个点,所述第一点和所述第二点满足预设相似条件;从所述第一点云中将所述至少一组对应点对中的所述第一点删除以得到所述前景点云。
41、在一种可能的实现方式中,所述预设相似条件包括以下条件中的至少一个:所述第一点和所述第二点的欧式距离小于第一阈值;以及,所述第一点对应的曲率和所述第二点对应的曲率之差小于第二阈值。
42、在一种可能的实现方式中,所述获取模块,还用于获取所述模板点云。
43、在一种可能的实现方式中,所述获取模块,具体用于在预设时间段内采集场景图像;根据所述场景图像获取所述模板点云。
44、在一种可能的实现方式中,所述获取模块,具体用于当毫米波雷达在预设时长内没有检测到动态目标时,采集场景图像;根据所述场景图像获取所述模板点云。
45、在一种可能的实现方式中,所述获取模块,具体用于当所述场景图像相较于历史场景图像的变化程度小于或等于第三阈值时,根据所述场景图像获取所述模板点云;或者,当所述场景图像相较于历史场景图像的变化程度大于所述第三阈值时,丢弃所述场景图像。
46、在一种可能的实现方式中,所述获取模块,还用于获取待检测的第二点云;根据所述第二点云和所述第一点云获取与第一目标点云关联的第二目标点云,所述第一目标点云是所述至少一个目标点云中的任意一个,所述第二目标点云来自于所述第二点云。
47、在一种可能的实现方式中,所述获取模块,具体用于通过计算与所述第一目标点云的相似性以得到所述第二目标点云。
48、在一种可能的实现方式中,还包括:应用模块,用于将待对比点云与数据库中的点云进行比对,所述待对比点云为所述第一目标点云或者所述第二目标点云,所述数据库中的点云为预先已配置人物信息的点云;当所述待对比点云与所述数据库中的点云匹配上时,根据所述数据库中的点云的所述人物信息执行相应的全屋智能操作。
49、在一种可能的实现方式中,所述分割模块,具体用于根据所述前景点云确定主方向;根据所述前景点云和所述主方向确定所述目标点云的数量;根据所述目标点云的数量对所述前景点云进行分割以得到所述至少一个目标点云。
50、第三方面,本技术实施例提供一种电子设备,包括:一个或多个处理器;存储器,用于存储一个或多个程序;当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现如上述第一方面中任一项所述的方法。
51、第四方面,本技术实施例提供一种计算机可读存储介质,包括计算机程序,所述计算机程序在计算机上被执行时,使得所述计算机执行上述第一方面中任一项所述的方法。
52、第五方面,本技术实施例提供一种计算机程序产品,所述计算机程序产品包括计算机程序代码,当所述计算机程序代码在计算机上运行时,使得计算机执行上述第一方面中任一项所述的方法。
- 还没有人留言评论。精彩留言会获得点赞!