一种分布式模糊测试加速方法及系统与流程
本发明涉及模糊测试,具体涉及一种分布式模糊测试加速方法及系统。
背景技术:
1、模糊测试通过模糊测试器生成大量随机数据,触发软件深层缺陷,再通过各类检测器进行问题分析与定位,可以帮助发现、修复应用、协议、内核、数据库等各种被测软件的bug,减少测试的人力成本,提升软件系统安全性与健壮性。模糊测试技术持续自动持续生成测试数据,测试时间长,计算量大,对cpu、内存等硬件资源消耗较大是其突出特点。
2、现有的模糊测试产品,从测试任务运行方式上来说,可以分为两种:
3、第一种是单点运行,如defensics、peach等工具,模糊测试器以单体软件的形式执行,对待测对象进行测试,待测对象只运行一个实例。不具备大规模并行测试支持,因而测试能力将受限于计算资源限制。随着软件复杂度提升,测试效率成为瓶颈,对于复杂测试对象表现为覆盖率低,无法发现深层bug。
4、另一类支持分布式测试,如google推出的clusterfuzz平台、微软推出的onefuzz平台等。这类平台支持在1000+节点并行执行测试,并提供集群管理等功能。在平台每个节点均运行模糊测试器(fuzzer),持续生成测试用例数据,待测对象同样运行多个实例,分布于平台节点。这些平台在测试运行过程中,每个节点运行的模糊测试器、验证检测器均为预先设置,只能通过反复重新测试来进行调优。
5、现有的分布式模糊测试技术,可以利用大规模集群进行扩展,但是仍然存在灵活性差,资源利用率低的问题。
6、首先,这些分布式模糊测试系统,其执行时间,执行资源分配是静态设置的;这就导致集群中存在大量的模糊测试任务,部分任务执行到瓶颈阶段,覆盖率进展缓慢;而其他任务处于排队中,得不到执行,最终影响到了整体的测试效率。
7、其次,模糊测试的种子测试用例,会随着测试的展开动态变化,不同的种子集合,影响模糊测试的搜索方向,最终的覆盖率以及发现的bug也会有所区别。已有的分布式模糊测试系统,会在不同的测试节点上使用不同的种子,从而获取不同的搜索方向,提高覆盖率及测试效率。但是随着测试的展开,某些测试的执行会陷入停滞,某些测试却处于排队中,得不到执行。只能通过人工干预的方式,基于对测试过程和结果数据的分析反复重新启动测试。如果节点较多,会造成较大的人力成本负担,效率也得不到保障。
技术实现思路
1、为此,本发明提供一种分布式模糊测试加速方法及系统,以解决以上技术问题。
2、为了实现上述目的,本发明提供如下技术方案:
3、根据本发明实施例的第一方面,提出一种分布式模糊测试加速方法,所述方法包括:
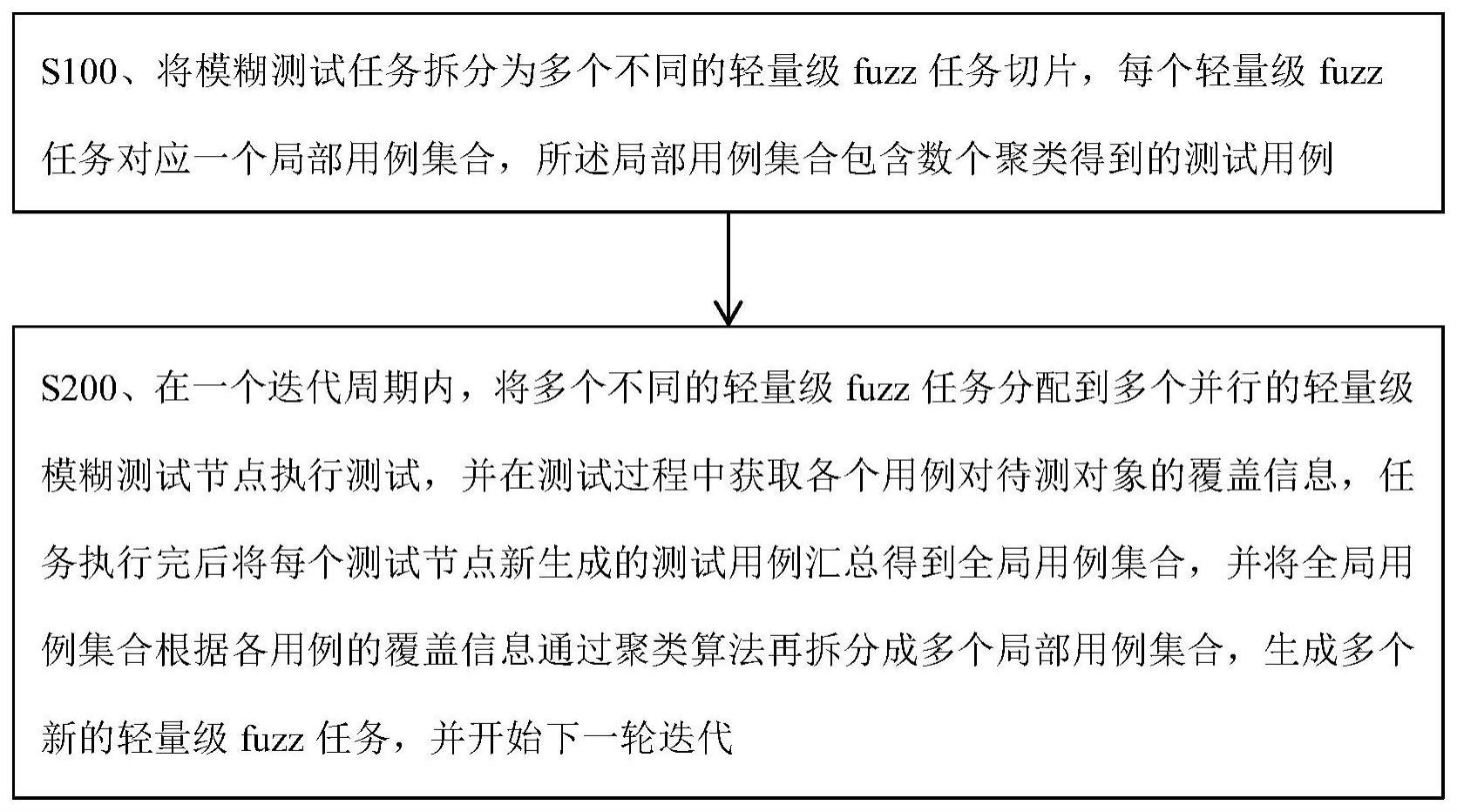
4、将模糊测试任务拆分为多个不同的轻量级fuzz任务切片,每个轻量级fuzz任务对应一个局部用例集合,所述局部用例集合包含数个聚类得到的测试用例;
5、在一个迭代周期内,将多个不同的轻量级fuzz任务分配到多个并行的轻量级模糊测试节点执行测试,并在测试过程中获取各个用例对待测对象的覆盖信息,任务执行完后将每个测试节点新生成的测试用例汇总得到全局用例集合,并将全局用例集合根据各用例的覆盖信息通过聚类算法再拆分成多个局部用例集合,生成多个新的轻量级fuzz任务,并开始下一轮迭代。
6、进一步地,所述全局用例集合是一个全局映射表,key中存储了各个用例对目标代码的详细覆盖信息;用例集合更新时,覆盖信息表现相同的用例会被替换。
7、进一步地,所述方法还包括:
8、轻量级模糊测试执行时间固定而且时间切片低于预设值,使得全局用例集合能够不断迭代更新。
9、进一步地,将全局用例集合根据各用例的覆盖信息通过聚类算法再拆分成多个局部用例集合,具体包括:
10、第一步,fuzz过程中获取各个用例对待测对象的详细覆盖信息,使用一个n纬向量来标记,其中n表示待测对象的代码总行数,0代表这一行被用例覆盖,1代表这一行没有被用例覆盖,把所有的用例都向量化;
11、第二步,任意选取k个向量,使用向量间的几何距离作为初始质心;
12、第三步,计算各个向量到质心的距离,距离把它划为跟质心同一聚簇之中;
13、第四步,每一个聚簇内,计算每一个向量到其他所有向量的距离,距离聚簇内所有其他向量最近的那个向量作为新的质心;
14、第五步,重复第三步到第四步,直到收敛。
15、进一步地,所述方法还包括:
16、通过动态调整k值,调整一个模糊测试任务的资源分配,k代表用例聚类的数量,同时也代表轻量级任务并发数,在资源比较紧张的情况或者重要性相对较低的任务,适当降低k值,反之则提高k值。
17、根据本发明实施例的第二方面,提出一种分布式模糊测试加速系统,所述系统包括云端服务器以及多个分布式测试节点;
18、所述云端服务器包括节点管理器和任务管理器;
19、所述节点管理器用于测试节点管理、测试集群组建以及测试过程管理;
20、所述任务管理器用于模糊测试任务的分配和用例聚类机制,负责局部用例的拆分和全局用例的更新维护,同时负责将一个模糊测试任务拆分为多个不同的轻量级任务切片执行并合并测试结果;
21、所述分布式测试节点用于并行运行多个模糊测试器以及对待测对象开展测试,测试节点上的检测器能够针对用例生成代码覆盖信息。
22、进一步地,所述任务管理器具体用于:
23、将模糊测试任务拆分为多个不同的轻量级fuzz任务切片,每个轻量级fuzz任务对应一个局部用例集合,所述局部用例集合包含数个聚类得到的测试用例;
24、在一个迭代周期内,将多个不同的轻量级fuzz任务分配到多个并行的轻量级模糊测试节点执行测试,并在测试过程中获取各个用例对待测对象的覆盖信息,任务执行完后将每个测试节点新生成的测试用例汇总得到全局用例集合,并将全局用例集合根据各用例的覆盖信息通过聚类算法再拆分成多个局部用例集合,生成多个新的轻量级fuzz任务,并开始下一轮迭代。
25、进一步地,所述任务管理器具体用于用例聚类,包括:
26、第一步,fuzz过程中获取各个用例对待测对象的详细覆盖信息,使用一个n纬向量来标记,其中n表示待测对象的代码总行数,0代表这一行被用例覆盖,1代表这一行没有被用例覆盖,把所有的用例都向量化;
27、第二步,任意选取k个向量,使用向量间的几何距离作为初始质心;
28、第三步,计算各个向量到质心的距离,距离把它划为跟质心同一聚簇之中;
29、第四步,每一个聚簇内,计算每一个向量到其他所有向量的距离,距离聚簇内所有其他向量最近的那个向量作为新的质心;
30、第五步,重复第三步到第四步,直到收敛。
31、进一步地,所述任务管理器具体用于:
32、通过动态调整k值,调整一个模糊测试任务的资源分配,k代表用例聚类的数量,同时也代表轻量级任务并发数,在资源比较紧张的情况或者重要性相对较低的任务,适当降低k值,反之则提高k值。
33、根据本发明实施例的第三方面,提出一种计算机存储介质,所述计算机存储介质中包含一个或多个程序指令,所述一个或多个程序指令用于被一种分布式模糊测试加速系统执行如上任一项所述的方法。
34、本发明具有如下优点:
35、本发明提出的一种分布式模糊测试加速方法及系统,将模糊测试任务拆分为多个不同的轻量级fuzz任务切片,每个轻量级fuzz任务对应一个局部用例集合,所述局部用例集合包含数个聚类得到的测试用例;在一个迭代周期内,将多个不同的轻量级fuzz任务分配到多个并行的轻量级模糊测试节点执行测试,并在测试过程中获取各个用例对待测对象的覆盖信息,任务执行完后将每个测试节点新生成的测试用例汇总得到全局用例集合,并将全局用例集合根据各用例的覆盖信息通过聚类算法再拆分成多个局部用例集合,生成多个新的轻量级fuzz任务,并开始下一轮迭代。采用“云-端”架构,在多个节点上利用时间切片执行轻量模糊测试任务,相比于现有技术具有多方面提升。本方案提出的模糊测试加速方法,基于测试覆盖信息,提高节点间的协作效率和整体测试效率,并且能动态调整资源分配,提升了分布式模糊测试的效率和灵活性。
- 还没有人留言评论。精彩留言会获得点赞!