一种基于双相机多分支网络的虚拟现实教学手势识别方法
本技术涉及模式识别与信息处理,更具体地,涉及一种基于双相机多分支网络的虚拟现实教学手势识别方法、系统及计算机设备。
背景技术:
1、教育,是各个时代都不可或缺的一项人类文化活动,把vr(虚拟现实)技术引入教育行业,开拓新的教学方法与方式,对于学生更高效、更主动地掌握各类技能至关重要。手势识别可以应用在vr、ar、辅助教学等多个场景中,手势识别的研究起着至关重要的作用。教学恰好是一个很好的虚拟现实应用场景,不论是各大高校教学或者是中小学、博物馆科技馆的科普教学等,都非常适合应用。目前的教学大部分停留在传统的图像教学,少部分应用了虚拟现实技术但存在交互性差且过于依赖游戏手柄的问题。
2、近年来,三维手势识别方法取得了一些重大进展。然而,相对于二维图像识别,三维手势中往往会出现遮挡问题,对于具体的实际应用来说,存在识别精度远远不够的问题,因此还有很大的改进空间。同时,对于教育应用方面,需要一种为教学设计的虚拟现实手势识别方法及系统。
技术实现思路
1、针对现有技术的至少一个缺陷或改进需求,本发明提供了一种基于双相机多分支网络的虚拟现实教学手势识别方法、系统及计算机设备,融合深度图像和3d点云图像两个模态的数据进行手部识别,两个模态的数据之间可以互补,具有更鲁棒的识别能力,从而提高识别精度。
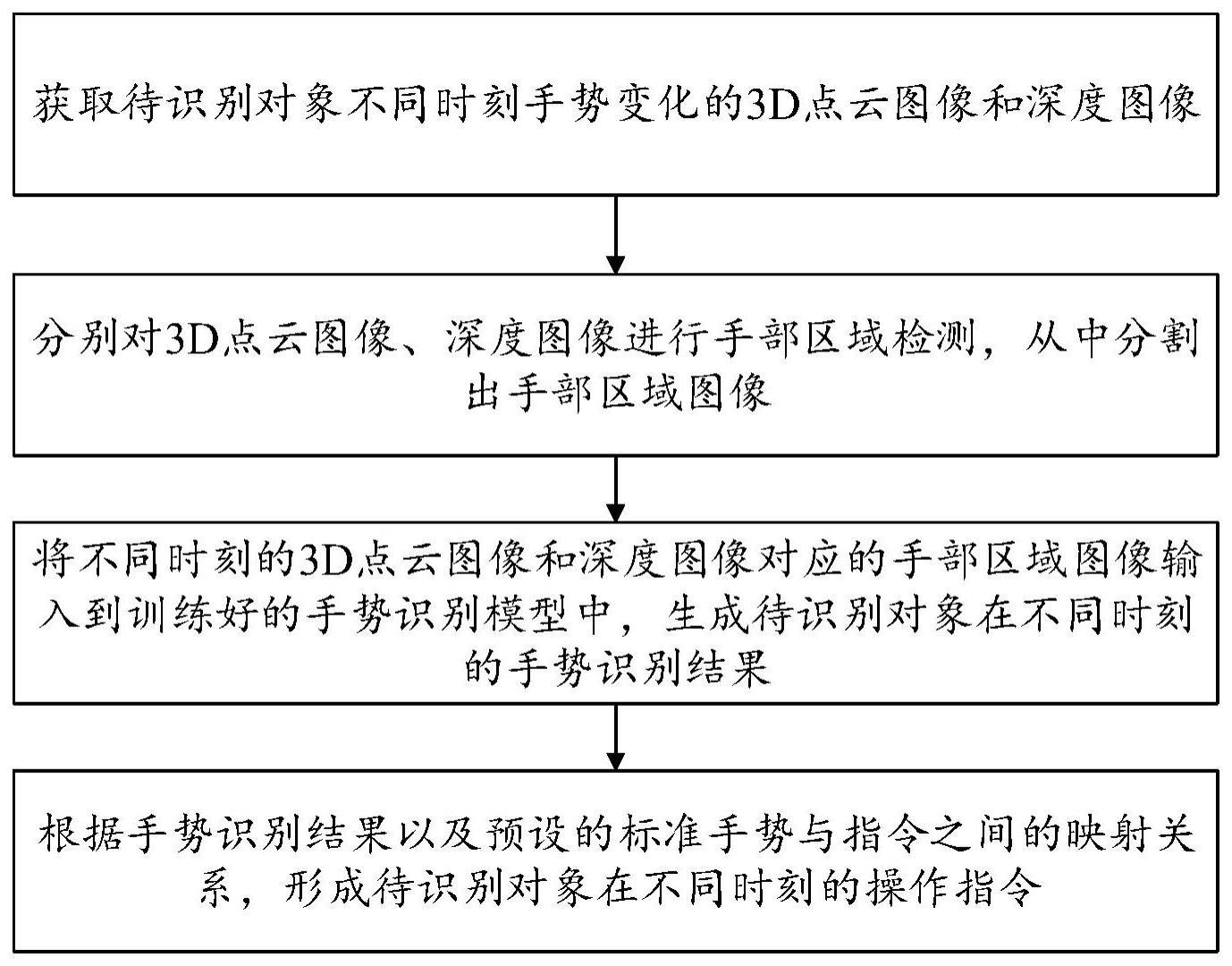
2、为实现上述目的,按照本发明的第一个方面,提供了一种基于双相机多分支网络的虚拟现实教学手势识别方法,该方法包括以下步骤:
3、获取待识别对象不同时刻手势变化的3d点云图像和深度图像;
4、分别对所述3d点云图像、深度图像进行手部区域检测,从中分割出手部区域图像;
5、将不同时刻的3d点云图像和深度图像对应的手部区域图像输入到训练好的手势识别模型中,分别提取手部区域的深度图像特征向量与点云图像特征向量并进行融合,基于融合特征向量生成待识别对象在不同时刻的手势识别结果;
6、根据所述手势识别结果以及预设的标准手势与指令之间的映射关系,形成待识别对象在不同时刻的操作指令。
7、进一步地,上述虚拟现实教学手势识别方法还包括:
8、对所述3d点云图像进行几何变换,包括平面内旋转、3d缩放和3d平移;
9、使用newdropout函数对所述深度图像进行图像增强。
10、进一步地,上述虚拟现实教学手势识别方法中,所述手势识别模型包括:
11、第一图像处理网络,其对深度图像中的手部区域图像进行特征提取,获得手部区域的深度图像特征向量;
12、第二图像处理网络,其对3d点云图像中的手部区域图像进行特征提取,获得手部区域的点云图像特征向量;
13、融合模块,其将所述深度图像特征向量与点云图像特征向量进行融合,生成融合特征向量;
14、手势识别网络,其基于所述融合特征向量生成待识别对象在不同时刻的手势识别结果。
15、进一步地,上述虚拟现实教学手势识别方法中,所述第一图像处理网络包括:
16、沙漏网络,其对深度图像中的手部区域图像进行特征提取,获得手部特征量;
17、深度图像空间分支,其根据沙漏网络输出的所述手部特征量计算每个关节的有监督注意力地图;
18、注意力增强分支,其根据沙漏网络输出的所述手部特征量计算每个关节的无监督注意力地图;
19、深度提取分支,其根据沙漏网络输出的所述手部特征量,生成包含每个关节的深度特征向量的密集深度特征图;
20、注意融合网络,其将所述有监督注意力地图与无监督注意力地图进行融合,得到融合注意图,并根据所述融合注意图和密集深度特征图识别每个关节的真实深度值,获得手部区域的深度图像特征向量。
21、进一步地,上述虚拟现实教学手势识别方法中,所述有监督注意力地图的计算方式为:
22、根据沙漏网络输出的手部特征量计算每个关节的注意力地图;
23、对所述注意力地图进行归一化处理,得到表征每个像素出现在关节位置的可能性的热图;
24、基于所述热图,通过积分运算计算每个关节在深度图像空间中的识别坐标;
25、以使每个关节在深度图像空间中的识别坐标与实际坐标之间的平均距离最小为条件对注意力地图进行监督,获得有监督注意力地图。
26、进一步地,上述虚拟现实教学手势识别方法中,所述第二图像处理网络包括:
27、下采样模块,其对输入的3d点云图像进行下采样,输出若干三维数据点;
28、归一化模块,其用于获取每个所述三维数据点的坐标值和曲面法线向量作为初始特征输入,在定向包围盒中进行归一化,获得归一化坐标;
29、分层提取模块,其以每个三维数据点的所述归一化坐标和三维曲面法线作为输入,将全部三维数据点划分为多个局部区域,通过对每个所述局部区域进行特征提取并映射为三维向量,得到手部区域的点云图像特征向量。
30、进一步地,上述虚拟现实教学手势识别方法中,所述手势识别网络包括:
31、多层transformer模型,其以融合模块输出的融合特征向量作为输入,生成偏移量和先验信息;在预定义的模板手网格的三维平均关节位置上加入所述偏移量,得到粗预测坐标;
32、自回归器,其根据所述先验信息对粗预测坐标进行多次迭代回归,得到细预测坐标,即为手势识别结果。
33、按照本发明的第二个方面,提供了一种基于双相机多分支网络的虚拟现实教学手势识别系统,该系统包括:
34、数据获取模块,用以获取待识别对象不同时刻手势变化的3d点云图像和深度图像;
35、预处理模块,用于分别对所述3d点云图像、深度图像进行手部区域检测,从中分割出手部区域图像;
36、识别模块,用于将不同时刻的3d点云图像和深度图像对应的手部区域图像输入到训练好的手势识别模型中,通过模型提取手部区域的深度图像特征向量与点云图像特征向量并进行融合,基于融合特征向量生成待识别对象在不同时刻的手势识别结果;
37、响应模块,用于根据所述手势识别结果以及预设的标准手势与指令之间的映射关系,形成待识别对象在不同时刻的操作指令。
38、进一步地,上述虚拟现实教学手势识别系统中,使用事件相机采集待识别对象不同时刻手势变化的3d点云图像;
39、使用leap motion控制器记录待识别对象不同时刻手势变化的深度图像。
40、按照本发明的第三个方面,还提供了一种计算机设备,其包括至少一个处理单元、以及至少一个存储单元,其中,所述存储单元存储有计算机程序,当所述计算机程序被所述处理单元执行时,使得所述处理单元执行上述任一项所述虚拟现实教学手势识别方法的步骤。
41、总体而言,通过本发明所构思的以上技术方案与现有技术相比,能够取得下列有益效果:
42、(1)本发明使用深度图像和3d点云图像两个模态的数据进行手势识别,两个模态的数据之间可以互补,使本方法具有更鲁棒的识别能力。
43、(2)本发明利用创新模型来提高对深度图像的手势识别精度,将三维手姿识别分解为深度图像空间中二维关节位置的识别,并通过两个互补的注意图来识别它们对应的深度,可以提取出关节特征和骨架特征,提高了识别精度。
44、(3)本发明引入事件相机获取对象的手势图像数据,事件相机可以敏感地捕捉到运动的物体,和传统相机相比,它具有低时延的特性,可以捕获很短时间间隔内的像素变化。同时通过事件相机采集图像数据可直接判断是否产生动作。
- 还没有人留言评论。精彩留言会获得点赞!