一种融合共现图和依赖关系图的双图神经网络及其构建方法
1.本发明涉及文本分类模型技术领域,尤其涉及一种融合共现图和依赖关系图的双图神经网络及其构建方法。
背景技术:
2.文本分类是自然语言处理的一项经典任务,使用预先定义的标签对文本进行标记。它被广泛应用于情感分析、推荐系统、新闻分类等。例如,自动判别一则新闻的类别,是体育类、政治类,还是经济类等。信息化时代,文本数量爆炸式增加。同时,由于其非结构化的特点,很难从中提取有价值的特征,因此降低了文本分类模型的泛化性能。
3.目前文本分类方法包括传统方法、深度学习方法。传统方法提取手工制作的特征,首先要对文本进行预处理操作,然后使用词袋模型、word2vec等方式表示文本,但会造成维度灾难,忽略文本语义,存在数据稀疏等问题。基于深度学习的模型被广泛提出,如cnn
1.、rnn
2.、lstm
3.等。然而上述模型在文本分类时,只关注顺序性和局部性特征,忽略了文本的全局词共现信息。2018年google基于transformer
4.构建了bert
5.模型,解决了序列到序列的问题。采用掩码语言模型和下句预测的方法,提高了模型的泛化性能,极大地改进了自然语言处理的无监督预训练技术。
4.图神经网络技术是指使用神经网络来学习图结构数据,提取图结构数据的特征和信息,继而进行下游的分类、聚类、预测等任务。bruna
6.等人提出将cnn应用到图上,通过巧妙的转化卷积算子,提出了图卷积网络(graph convolutional netwok,gcn)
7.,随之衍生出许多变体。gnn的主流算法包括图卷积神经网络、图注意力网络、门控图神经网络等。基于文本分类的图神经网络方法不断涌现,为文本分类提供新思路。文本之间的语序就包含图结构,如句法和语义解析树。
5.2019年,姚亮
8.构建语料级的词—词—文本图,并运行图卷积神经网络,捕捉文本单词间的关系。由于是直推式学习,不能轻易推广到新样本。当添加新样本时,需要从头重新构图和训练,浪费内存和时间。为了将gnn应用于短文本分类,2019年hgat
9.在构建语料级的大图时,引入了主题、实体信息,缓解了短文本稀疏的问题。为了解决直推和内存耗费的问题,lianzhe huang和yufeng zhang提出为文本单独构建图。lianzhe huang[10]首先为文本构建文本层次图,创建边共享矩阵捕捉全局信息,同时引入消息传递机制。
[0006]
但是未考虑不同的文本中词交互是不同的。2020年,yufeng zhang
[11]
使用滑动窗口在每个文档中构建独立的图,采用图门控机制(ggnn)
[12]
来聚合图上的邻居信息,在测试中可以对新文本进行归纳。2020年xienliu
[13]
提出张量图卷积网络进行文本分类,构建一个文本图张量来描述语义、句法和序列上下文信息,图内传播和图间传播相结合,但仍然是直推式学习。其他研究人员探索将bert或bilstm模型与gnn相结合,使两者相互补充,获取更全面的信息。2021年tw-tgnn
[14]
通过引入全局滑动窗口和局部滑动窗口来获取全局信息和局部信息。gfn
[15]
将预先计算的共现统计信息和预先训练的嵌入转换为结构信息来构建不同的文本级别的图,设计多头融合模块整合文本图结果。可以归纳学习文本信息,轻易泛
化到新文本。
[0007]
图神经网络方法在文本分类中取得了良好的效果,但仍存在一些不足。(1)语料图的构建是直推推理学习,从头训练新样本,浪费时间、内存。(2)部分学者提出构建文本级图来解决上述问题,但忽略构图质量,从而影响分类性能。(3)使用预先训练好的glove作为词向量的初始化特征,无法关注文本本身的特性。同时,图神经网络获取文本特征时,忽略文本顺序。
技术实现要素:
[0008]
本发明的目的在于提出一种具有较好泛化性能,有效提高分类精度的融合共现图和依赖关系图的双图神经网络及其构建方法。
[0009]
为达到上述目的,本发明提出一种融合共现图和依赖关系图的双图神经网络,双图神经网络将文本转换为图结构,将文本分类任务转换为图分类任务;为单个文本构建共现图和依赖关系图;使用双向长短时记忆网络捕捉序列特征,对glove初始化词向量获得的千层特征进行补偿。
[0010]
本发明还提出一种融合共现图和依赖关系图的双图神经网络的构建方法,包括以下步骤:
[0011]
s1:准备文本数据集;
[0012]
s2:对文本进行预处理,划分出训练集和测试集;
[0013]
s3:构建双图
[0014]
s3.1:共现文本图的构建:使用滑动窗口在文本上获得单词间的共现关系,依据共现关系构建一个无向共现文本图;
[0015]
s3.2:依赖关系图的构建:使用stanfordnlp来提取单词之间的依赖关系和词性信息,依据依赖关系构建一个无向依赖关系图;
[0016]
s4:图特征提取
[0017]
s4.1:利用门控图神经网络捕捉共现文本图的特征:针对共现文本图,使用门控图神经网络提取共现文本图的特征;捕捉得到的共现图的嵌入表示记作d
t
是共现文本图嵌入表示的维度;
[0018]
s4.2:利用图卷积神经网络捕捉依赖关系图的特征:使用bilstm模块提取文本的语义特征,得到的单词嵌入表示作为文本图的嵌入矩阵,运行图卷积神经网络提取依赖关系图的特征;捕捉依赖关系图的嵌入表示记作d2是依赖关系图嵌入表示的维度;
[0019]
s5:融合分类,将预测标签和真实标签对比,计算损失。
[0020]
进一步的,在步骤s2中,对文本的预处理包括将大写转化为小写、清洗非文本内容、去除停止词和低频词、glove初始化词嵌入;然后对数据集进行shuffle操作,按照7:3的比例划分数据集为训练集和测试集。
[0021]
进一步的,在步骤s3中,构建文本图时,有效地利用单词间的关系;使用t={w1,...,wi...wn}标记一个文本,该文本拥有n个单词,其中文本中的第i个单词记作wi;将文本输入到嵌入层,使用glove初始化单词为d维向量;对于t,为其构建相应的文本图,图中
的节点由单词构成,边由单词间的关系构成,文本图记作v
t
、e
t
是对应的节点集和边集;将ng设置为2,表明为单个文本构建两种图:共现图和依赖关系图;文本图的特征矩阵,记作第i个节点的向量表示为xi∈rd,n
t
是该文本图中的节点数量,n
t
=|v
t
|;文本图的邻接矩阵记作
[0022]
进一步的,在步骤s3.1中,依据单词之间局部共现的语言特征来构建共现文本图,记作g1=(v1,e1);使用固定大小的窗口在文本上从左向右滑动,在同一窗口的单词在图中是连接的。
[0023]
进一步的,在步骤s3.2中,依据单词间的依赖关系构建依赖关系图;首先,对于语料库中的文本,使用stanford nlp对文本进行解析,获取单词间的依赖关系;提取到的依赖是有向的,为了方便计算,将边视作无向;文本的依赖关系记作:dp={r
ij
|i≠j;i,j<n2},文本中单词wi和wj之间的依赖关系记作r
ij
;根据依赖关系构建依赖关系图,记作g2=(v2,e2),其中e2表示为:e2={e
ij
|r
ij
∈dp},由此构建的依赖图包含丰富的语义和句法特征。
[0024]
进一步的,在步骤s4.1中,在构建的共现文本图上,运行ggnn网络提取节点特征,使用门控循环单元的思路;
[0025]
图上进行消息传递时,节点接收邻居节点的信息,然后将其与之前的时间点表示合并,以更新节点自身的隐藏表示;模型在t时刻的传播过程如下:
[0026]nt
=a1h
t-1
wn+bn[0027]ut
=σ(w
unt
+m
uht-1
)
[0028]rt
=σ(w
r n
t
+m
r h
t-1
)
[0029][0030][0031]
式中,是共现图的邻接矩阵,聚合邻居信息记作n;u和r分别是更新门和重置门;r
t
决定利用哪些旧信息;(1-u
t
)选择遗忘不重要的信息,u
t
选择记住哪些新产生的信息;
⊙
是对应元素相乘的操作符;是新产生的信息,h
t
是t时刻最终的节点嵌入表示;捕捉共现图的嵌入表示记作d
t
是共现文本图嵌入表示的维度。
[0032]
进一步的,在步骤s4.2中,对依赖关系图的构建,通过bilstm获取节点特征作为初始嵌入表示,然后在gcn网络进一步提取特征;为捕捉单词间的顺序性特征,依赖图通过bilstm提取更深层次的文本特征;
[0033]
构建依赖关系图,由bilstm捕获的节点表示作为依赖关系图的特征矩阵,其邻接矩阵记作a2;gcn模型在图上执行;卷积层数依据数据集设置,最后将依赖关系图的嵌入表示记作d2是依赖关系图嵌入表示的维度。
[0034]
进一步的,在步骤s5中,计算损失步骤如下:
[0035]
依赖关系图、共现图节点表示首先被聚合生成图级表示h
g-dp
,h
g-co
,然后将两者表示融合起来,得到h
total
作为文本的最终表示;最后使用h
total
去预测文本的标签;
[0036]
首先,聚合邻居节点信息,得到双图的全图表示h
g-dp
,h
g-co
。通过ggnn获得共现文本
图的嵌入表示h
co
,gcn获得依赖关系图的嵌入表示h
dp
,以共现文本图为例,求得全图表示h
g-co
公式如下:
[0037]f1v
=σ(o(h
vco
))
[0038][0039]hv
=f
1v
⊙f2v
[0040][0041]
式中,o和p是多层感知机,f
1v
采用软注意力机制,依据节点的嵌入表示h
vco
决定哪个节点相对重要;f
1v
是单词v的注意力权重,f
2v
充当非线性变换;得到单词的权重表示hv;应用最大和全局池化获得文本的图表示h
g-co
;同理求得依赖关系图的图表示h
g-dp
;
[0042]
然后,采用concat方式,融合两个文本表示,最终文本表示如下:
[0043]htotal
=h
g-co
||h
g-dp
[0044]
最后,根据文本表示h
total
,使用softmax分类器预测文本的标签,使用交叉熵函数作为损失函数,计算所有文本的预测标签和真实标签之间的损失:
[0045][0046][0047]
与现有技术相比,本发明的优势之处在于:本发明的双图神经网络将文本转换为图结构,将文本分类任务转换为图分类任务。为单个文本构建共现图和依赖关系图,解决难以泛化到新样本以及不能充分利用词间依赖信息的问题。使用双向长短时记忆网络捕捉序列特征,对glove
[16]
初始化词向量获得的千层特征进行补偿。本发明的方法在文本分类上优于经典模型,具有较好的泛化性能较高的分类精度。
附图说明
[0048]
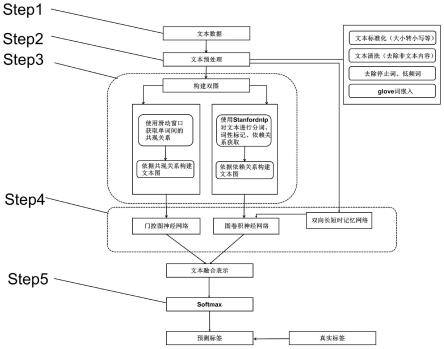
图1为本发明实施例中融合共现图和依赖关系图的双图神经网络的构建方法流程图;
[0049]
图2为本发明实施例中双图神经网络架构图;
[0050]
图3为本发明实施例中共现文本图构建图;
[0051]
图4为本发明实施例中依赖句法分析图。
具体实施方式
[0052]
为使本发明的目的、技术方案和优点更加清楚,下面将对本发明的技术方案作进一步地说明。
[0053]
本发明提出一种融合bilstm的双图神经网络(dual graph neural networks with bilstm,dgnn-b)用于文本分类。将文本转换为图结构,将文本分类任务转换为图分类任务。为单个文本构建共现图和依赖关系图,解决难以泛化到新样本以及不能充分利用词间依赖信息的问题。使用双向长短时记忆网络捕捉序列特征,对glove初始化词向量获得的千层特征进行补偿。该方法在文本分类上优于经典模型,具有较好的泛化性能较高的分类
精度。。
[0054]
如图1所示,本发明的双图神经网络的构建方法如下:
[0055]
s1:准备文本数据集;
[0056]
s2:对文本进行预处理;对文本的预处理包括将大写转化为小写、清洗非文本内容(如表情、html)、去除停止词和低频词、glove初始化词嵌入;然后对数据集进行shuffle操作,按照7:3的比例划分数据集为训练集和测试集。
[0057]
为解决构建大型语料库图浪费内存和不易泛化到新样本的问题,提出dgnn-b模型,以捕捉词共现图和依赖关系图特征,优化文本分类性能。该体系结构如图2所示。基于文本构建共现图和依赖关系图,提取局部词共现信息和词间依赖信息。同时,利用双向长短时间记忆网络将glove词向量表示和词性信息集成。然后,使用gcn和ggnn分别捕捉依赖关系图和共现图的特征;最后,融合双图表示,提高文本分类的性能,具体步骤如s3-s5所述。
[0058]
s3:构建双图
[0059]
构建文本图时,有效地利用单词间的关系;使用t={w1,...,wi...wn}标记一个文本,该文本拥有n个单词,其中文本中的第i个单词记作wi;将文本输入到嵌入层,使用glove初始化单词为d维向量;对于t,为其构建相应的文本图,图中的节点由单词构成,边由单词间的关系构成,文本图记作v
t
、e
t
是对应的节点集和边集;将ng设置为2,表明为单个文本构建两种图:共现图和依赖关系图;文本图的特征矩阵,记作第i个节点的向量表示为xi∈rd,n
t
是该文本图中的节点数量,n
t
=|v
t
|;文本图的邻接矩阵记作
[0060]
s3.1:共现文本图的构建:依据单词之间局部共现的语言特征来构建共现文本图,记作g1=(v1,e1);使用固定大小的窗口在文本上从左向右滑动,在同一窗口的单词在图中是连接的;如图3所示。
[0061]
局部滑动窗口可以有效地捕捉词间的局部共现特征。在共现文本图构建完成后,运行ggnn进行词特征信息传播和集合。
[0062]
s3.2:依赖关系图的构建:基于共现图可以捕获局部共现特征,但缺失了语义信息。依赖分析[17][18]可以捕获单词间的语法依赖关系,帮助理解文本。为了解决如上问题,如图4所示,对文本进行依赖分析依据单词间的依赖关系构建依赖关系图;首先,对于语料库中的文本,使用stanfordnlp对文本进行解析,获取单词间的依赖关系;提取到的依赖是有向的,为了方便计算,将边视作无向;文本的依赖关系记作:dp={r
ij
|i≠j;i,j<n2},文本中单词wi和wj之间的依赖关系记作r
ij
;根据依赖关系构建依赖关系图,记作g2=(v2,e2),其中e2表示为:e2={e
ij
|r
ij
∈dp},由此构建的依赖图包含丰富的语义和句法特征。
[0063]
构建文本级图可以减少节点和边的数量,在遇到新样本时,无需从零训练,是一种归纳学习。与单一文本图相比,构建两种不同类型的图,通过将依赖关系和共现信息融合,可以捕获多信息,有利于从两个方面提取特征,在图的传播中相互补充。
[0064]
s4:图特征提取
[0065]
s4.1:利用门控图神经网络捕捉共现文本图的特征:在构建的共现文本图上,运行ggnn网络提取节点特征,使用门控循环单元的思路;
[0066]
图上进行消息传递时,节点接收邻居节点的信息,然后将其与之前的时间点表示合并,以更新节点自身的隐藏表示;模型在t时刻的传播过程如下:
[0067]nt
=a1h
t-1
wn+bn[0068]ut
=σ(w
unt
+m
uht-1
)
[0069]rt
=σ(wrn
t
+m
rht-1
)
[0070][0071][0072]
式中,是共现图的邻接矩阵,聚合邻居信息记作n;u和r分别是更新门和重置门;r
t
决定利用哪些旧信息;(1-u
t
)选择遗忘不重要的信息,u
t
选择记住哪些新产生的信息;
⊙
是对应元素相乘的操作符;是新产生的信息,h
t
是t时刻最终的节点嵌入表示;捕捉共现图的嵌入表示记作d
t
是共现文本图嵌入表示的维度。
[0073]
s4.2:利用图卷积神经网络捕捉依赖关系图的特征:对于构建的依赖图,通过bilstm获取节点特征作为初始嵌入表示,然后在gcn网络进一步提取特征。为捕捉单词间的顺序性特征,依赖图通过bilstm提取更深层次的文本特征,不同于共现图只使用浅层特征glove。一方面,文本数据是非欧几里德结构。bilstm可以记录文本的位置信息,从而捕获文本的序列化特征。另一方面,bilstm的双向机制使得每个单词都能获得更多的语义信息,通过充分考虑上下文信息。
[0074]
构建依赖关系图,由bilstm捕获的节点表示作为依赖关系图的特征矩阵,其邻接矩阵记作a2;gcn模型在图上执行;卷积层数依据数据集设置,最后将依赖关系图的嵌入表示记作d2是依赖关系图嵌入表示的维度。
[0075]
s5:融合分类,将预测标签和真实标签对比,计算损失:
[0076]
依赖关系图、共现图节点表示首先被聚合生成图级表示h
g-dp
,h
g-co
,然后将两者表示融合起来,得到h
total
作为文本的最终表示;最后使用h
total
去预测文本的标签;
[0077]
首先,聚合邻居节点信息,得到双图的全图表示h
g-dp
,h
g-co
。通过ggnn获得共现文本图的嵌入表示h
co
,gcn获得依赖关系图的嵌入表示h
dp
,以共现文本图为例,求得全图表示h
g-co
公式如下:
[0078]f1v
=σ(o(h
vco
))
[0079][0080]hv
=f
1v
⊙f2v
[0081][0082]
式中,o和p是多层感知机,f
1v
采用软注意力机制,依据节点的嵌入表示h
vco
决定哪个节点相对重要;f
1v
是单词v的注意力权重,f
2v
充当非线性变换;得到单词的权重表示hv;应用最大和全局池化获得文本的图表示h
g-co
;同理求得依赖关系图的图表示h
g-dp
;
[0083]
然后,采用concat方式,融合两个文本表示,最终文本表示如下:
[0084]htotal
=h
g-co
||h
g-dp
[0085]
最后,根据文本表示h
total
,使用softmax分类器预测文本的标签,使用交叉熵函数作为损失函数,计算所有文本的预测标签和真实标签之间的损失:
[0086][0087][0088]
本技术参考文献:
[0089]
[1]kim y.convolutional neural networks for sentence classification[c]//proc ofthe 19th conference on empirical methods innatural language processing.2014:1746-1751.
[0090]
[2]mikolovt,karafiatm,burgetl,etal.recurrent neural network based language model[c]//proc ofthe 11th annual conference of the international speech communication association .2010:1045-1048.
[0091]
[3]hochreiter s,schmidhuber j.long short-term memory[j].neural computation,1997,9(8):1735-1780.
[0092]
[4]vaswani a,shazeer n,parmar n,el al.attention is all you need[c]//proc of the 31st international conference on neural information processing system.red hook,ny:curran associates inc,2017:6000-6010.
[0093]
[5]devlin j,chang m w,lee k,et al.bert:pre-training of deep bidirectional transformers for language understanding[c]//proc of annual conference of the north american chapter of association for computational linguistics:human languange technologies.stroudsburg,pa:association for computational lingustics,2019:4171-4186.
[0094]
[6]bruna j,zaremba w,szlam a,et al.spectral networks and locally connected networks on graphs[eb/ol].(2014-05-21).https://arxiv.org/ans/1312.6203.
[0095]
[7]kipf t n,welling m.semi-supervised classification with graph convolutional networks[c]//proc of international conference on learning representations.2017:36-50.
[0096]
[8]yao l,mao c,luo y.graph convolutional networks for text classification[c]//proc of the 33rd aaai conference on artificial intelligence.palo alto,ca:aaai press,2019:7370-7377.
[0097]
[9]hu,linmei,tianchi yang,chuan shi,houye ji and xiaoli li.“heterogeneous graph attention networks for semi-supervised short text classification.”emnlp(2019).
[0098]
[10]huang l,ma d,li s,et al.text level graph neural network for text classification[c]//proc of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing.2019:3442-3448.
[0099]
[11]zhang y,yu x,cui z,et al.every document owns its structure:inductive text classification via graph neural networks[c]//proc of the 58th annual meeting of the association for computational linguistics.stroudsburg,pa:association for computational lingustics,2020:334-339.
[0100]
[12]li y,tarlow d,brockschmidt m,et al.gated graph sequence neural networks[c]//proc of the 4th international conference on learning representations.2015.
[0101]
[13]liu x,you x,zhang x,et al.tensor graph convolutional networks for text classification[c]//proc of the 34th aaai conference on artificial intelligence.palo alto,ca:aaai press,2020,34(05):8409-8416.
[0102]
[14]wu x,luo z,du z,et al.tw-tgnn:two windows graph-based model for text classification[c]//2021international joint conference on neural networks.piscataway,nj:ieee,2021:1-8.
[0103]
[15]dai y,shoul,gong m,et al.graph fusion network for text classification[j].knowledge-based systems,2022,236:107659.
[0104]
[16]pennington j,socher r,manning c d.glove:global vectors for word representation[c]//proc ofthe 19th conference on empirical methods in natural language processing.2014:1532-1543.
[0105]
[17]范国凤,刘璟,姚绍文,等.基于语义依存分析的图网络文本分类模型[j].计算机应用研究,2020,37(12):3594-3598.(fan guofeng,liu jing,yao shaowen,et al.text classification model with graph network based on semantic dependency parsing[j].application research of computers,2020,37(12):3594-3598.)
[0106]
[18]邵党国,张潮,黄初升,等.结合onlstm-gcn和注意力机制的中文评论分类模型[j].小型微型计算机系统,2021,42(7):1377-1381.(shao dangguo,zhang chao,huang chusheng.chinese comment classification model combining onlstm-gcn and attention mechanism[j].journal of chinese computer systems,2021,42(7):1377-1381.)
[0107]
上述仅为本发明的优选实施例而已,并不对本发明起到任何限制作用。任何所属技术领域的技术人员,在不脱离本发明的技术方案的范围内,对本发明揭露的技术方案和技术内容做任何形式的等同替换或修改等变动,均属未脱离本发明的技术方案的内容,仍属于本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1