一种人脸过滤模型的训练方法、人脸识别方法及装置
本发明涉及人工智能,尤其涉及一种人脸过滤模型的训练方法、人脸识别方法及装置。
背景技术:
1、在监控视频人脸识别系统中为了实现大规模的视频分析,现有技术中,一方面是从算法模型本身入手,通过剪枝神经网络中不必要的参数使模型轻量化,降低视频分析的计算负载;另一方面,通过借助轻量级算法对视频流数据进行预处理,使用过滤器快速过滤掉大量与目标事件无关的视频帧,从而动态地降低实际到达人脸识别网络模型的视频帧的数量,实现快速的多视频流在线分析。
2、然而,由于监控视频场景下人脸离监控摄像头距离远,噪声干扰等因素,使得视频帧过滤中模型对部分视频帧中目标人脸的检测变得很困难,无法精准捕获监控视频中的目标人脸,导致部分含有目标人脸的视频帧被过滤掉,从而出现漏检的问题,降低了模型过滤视频帧的准确性,同时视频帧过滤机制中存在多个模型,多模型之间存在资源竞争的关系,并且实际场景是动态变化的,现有人脸识别模型无法场景变化调整过滤机制,从而降低了人脸识别模型对视频帧中人脸的识别效率和识别准确率。
技术实现思路
1、鉴于此,本发明实施例提供了一种人脸过滤模型的训练方法、人脸识别方法及装置,以解决现有视频帧过滤模型过滤效率低以及人脸识别效率低的问题。
2、本发明的一个方面提供了一种人脸过滤模型的训练方法,该方法包括以下步骤:
3、获取训练样本集,所述训练样本集包括多个样本,每个样本包括一个样本图片,对各样本图片添加真实人脸位置信息并以人脸作为标签;
4、获取预设神经网络,所述预设神经网络采用ssd网络提取所述样本图片多个尺寸的预测特征图,对每个样本图片的一个或多个预测特征图进行插值、维度统一和叠加后,输入线性激活函数得到融合特征图,基于所述融合特征图识别得到含有预测人脸位置的图片;
5、采用所述训练样本集对所述预设神经网络进行训练,将位置损失函数和置信损失函数加权求和后构建为总损失函数以对所述预设神经网络的参数迭代更新,得到人脸过滤模型。
6、在一些实施例中,所所述预设神经网络采用ssd网络提取所述样本图片多个尺寸的预测特征图,对每个样本图片的一个或多个预测特征图进行插值、维度统一和叠加后,输入线性激活函数得到融合特征图,基于所述融合特征图识别得到含有预测人脸位置的图片,包括:
7、将所述样本图片尺寸调整为300×300后输入所述人脸过滤模型,所述人脸过滤模型中的ssd网络分别利用conv4_3、conv5_3和fc_6三个预测特征层在所述样本图片中提取预测特征图;
8、采用双三次插值法对所述conv4_3提取的第一预测特征图中的像素点进行插值计算并采用3×3×512的卷积核提取插值后的所述第一预测特征图中的图像特征,对插值后的所述第一预测特征图归一化处理后得到第一特征图;
9、通过反卷积使得所述conv5_3提取的第二预测特征图的维度与所述第一预测特征图的维度一致,采用双三次插值法对反卷积后的所述第二预测特征图中像素点进行插值计算,并采用3×3×512的卷积核提取插值后的所述第二特征图中图像特征,对插值后的所述第二预测特征图归一化处理后得到第二特征图;
10、通过反卷积使得所述fc_6提取的第三预测特征图的维度与所述第一预测特征图的维度一致,采用双三次插值法对反卷积后的所述第三预测特征图中像素点进行插值计算,并采用3×3×512的卷积核提取插值后的所述第三特征图中图像特征,对插值后的所述第三预测特征图归一化处理后得到第三特征图;
11、将所述第一特征图、所述第二特征图以及所述第三特征图中的特征叠加,并输入线性激活函数得到第一融合特征图,将所述第一融合特征图卷积池化后输出得到含有多个预测框的第二融合特征图,过滤掉置信度低于阈值的预测框以及与真实人脸位置框重合率高于阈值的预测框,输出得到所述含有预测人脸位置的图片。
12、本发明的另一方面提供了一种人脸识别方法,包括:
13、获取多个视频流,并对各视频流统一编号;
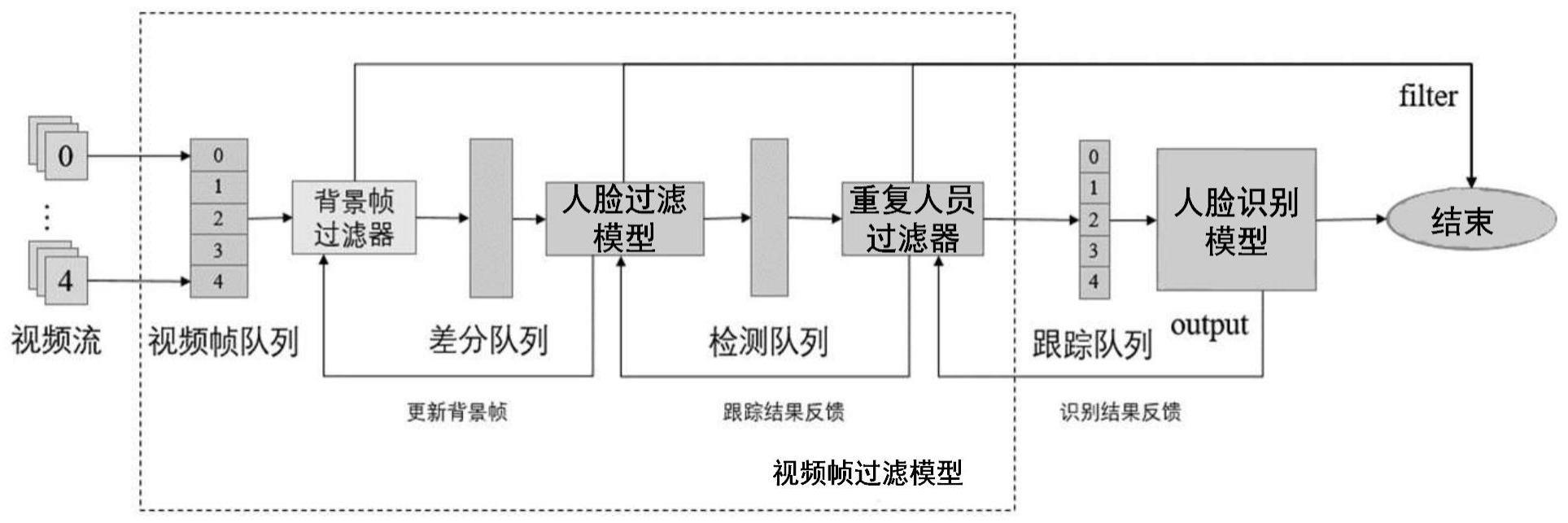
14、将各视频流按照编号顺序输入视频帧过滤模型,所述视频帧过滤模型包括依次连接的背景帧过滤器、如上述人脸过滤模型训练方法中的人脸过滤模型以及重复人员过滤器;其中,所述背景帧过滤器采用差分检测识别含有运动目标的第一类视频帧;将所述第一类视频帧输入所述人脸过滤模型并筛选得到含有预测人脸位置的第二类视频帧;所述重复人员过滤器采用dsst算法过滤所述第二类视频帧中含有重复人脸的视频帧,对重复的人脸仅保留一张目标视频帧输出;
15、将所述目标视频帧输入至预设人脸识别模型,进行识别得到目标人员身份信息;
16、将所述目标人员身份信息标记在对应视频流的各视频帧中,并存储至数据库。
17、在一些实施例中,所述背景帧过滤器采用差分检测识别含有运动目标的第一类视频帧,包括:
18、从所述视频流中选取一张视频帧作为背景视频帧,其余作为第三类视频帧;将所述第三类视频帧中像素点的灰度值依次与所述背景视频帧像素点的灰度值做差分运算,得到各第三类视频帧对应的差分图像;对所述差分图像进行二值化处理,将所述差分图像中像素值小于设定阈值的像素点赋值0作为背景点,像素值大于等于阈值的像素点赋值255作为前景点,得到所述第三类视频帧的二值化图像,对所述二值化图像中的前景点进行连通性分析后输出得到含有运动目标的所述第一类视频帧。
19、在一些实施例中,将所述第三类视频帧中像素点的灰度值依次与所述背景视频帧像素点的灰度值做差分运算,得到各第三类视频帧对应的差分图像,包括:
20、所述差分图像计算式为:
21、dn(x,y)=|fn(cn,yn)-fm(xm,ym)|;
22、其中,dn(x,y)表示所述差分图像,fn(xn,yn)表示所述第三类视频帧中像素点的灰度值,fm(xm,ym)表示所述背景视频帧中像素点的灰度值,(xn,yn)表示所述第三类视频帧中像素点的坐标,(xm,ym)表示所述背景视频帧中像素点的坐标,(x,y)表示所述差分图像中像素点的坐标。
23、在一些实施例中,将所述第一类视频帧输入所述人脸过滤模型并筛选得到含有预测人脸位置的第二类视频帧之后,还包括:
24、在处理过程中将所述第一类视频帧构建为差分队列,将所述第三类视频帧构建为视频帧队列,以供调用;
25、在所述差分队列中的所述第一类视频帧数量大于所述视频队列中的所述第三类视频帧数量时,将所述人脸过滤器检出的不包含人脸的视频帧更新为所述背景视频帧,以继续处理所述样本视频流中剩余的视频帧。
26、在一些实施例中,所述预设人脸识别模型对所述目标视频帧进行识别得到目标人员身份信息之前,还包括:
27、对所述目标视频帧进行预处理,所述预处理包括:人脸对准,人脸光线补偿,灰度变换、直方图均衡化、归一化、几何校正、中值滤波以及锐化。
28、在一些实施例中,所述预设人脸识别模型对所述目标视频帧进行识别得到目标人员身份信息,包括:
29、所述预设人脸识别模型提取所述目标视频帧中所述目标人员的人脸特征并与数据库中存储的多个已知身份信息人员进行人脸特征匹配,若所述目标人员的人脸特征与所述数据库中的一已知身份信息人员的人脸特征匹配度高于匹配度阈值,则认为所述目标人员与所述已知身份信息人员为同一人,从而得到所述目标人员身份信息。
30、另一方面,本发明还提供一种电子设备,包括处理器和存储器,所述存储器中存储有计算机指令,所述处理器用于执行所述存储器中存储的计算机指令,当所述计算机指令被处理器执行时该装置实现上述方法的步骤。
31、另一方面,本发明还提供一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现上述方法的步骤。
32、本发明的有益效果至少是:
33、本发明所述人脸过滤模型的训练方法、人脸识别方法及装置,通过背景帧过滤器过滤掉视频帧中的背景视频帧输出含运动目标的第一类视频帧,人脸过滤模型对第一类视频帧过滤输出含人脸的第二类视频帧,重复人脸过滤器过滤掉第二类视频帧中含重复人脸的视频帧对于相同人脸仅输出一张目标视频帧,预设人脸识别模型对目标视频帧中的人员进行身份信息识别,通过逐级过滤减少了预设人脸识别模型的工作量,同时提高了视频帧过滤模型的视频帧过滤效率。
34、进一步地,通过双三次插值法对ssd网络中预测特征层提取的预测特征图进行插值计算后特征叠加,增强了预测特征图中的人脸特征,避免了部分视频帧因人脸不清晰而被过滤掉,提高了视频帧过滤模型的过滤准确性。
35、进一步地,当差分队列中的第一类视频帧数量大于视频帧队列中的第三类视频帧数量时,更新背景视频帧,通过反馈机制,自适应更新背景帧过滤器中的背景视频帧,缓解了各模型处理视频帧速度不同造成的视频帧堆积问题,减少了不同过滤器之间的硬件资源竞争问题,提高了人脸识别模型的识别效率以及视频帧过滤模型的过滤效率。
36、本发明的附加优点、目的,以及特征将在下面的描述中将部分地加以阐述,且将对于本领域普通技术人员在研究下文后部分地变得明显,或者可以根据本发明的实践而获知。本发明的目的和其它优点可以通过在说明书以及附图中具体指出的结构实现到并获得。
37、本领域技术人员将会理解的是,能够用本发明实现的目的和优点不限于以上具体所述,并且根据以下详细说明将更清楚地理解本发明能够实现的上述和其他目的。
- 还没有人留言评论。精彩留言会获得点赞!