一种人物交互检测模型、方法、系统及装置与流程
1.本发明涉及计算机技术领域,更具体地说,涉及一种人物交互检测模型、方法、系统及装置。
背景技术:
2.人物交互(human object interraction,hoi)检测旨在解决人和物的交互关系问题,不同于常见的目标检测、动作识别等任务,人物交互检测需要更高层次的视觉理解。hoi检测要求模型明确地定位图像中人和物体的位置,同时正确预测其交互行为。hoi检测不仅需要定位到人的位置、物的位置,还需要捕获复杂的人与物体的相互作用,如“人踢球”、“人开车”等。
3.通过研究hoi检测来模拟人类认识周围世界的方式,可以促进服务型机器人等技术的研究。同时,识别图像蕴含的人物交互行为,是实现自动理解图像主题、自动描述图像主要内容的关键。现有技术中,一些方法通过视觉和语言预训练或者语言知识注入来激发hoi图像和文本对应的多模态模型,但大多数方法模态融合粗糙,忽视了不同模态之间的异质性差异,缺乏跨模态建模或单模态学习来缩小模态间差异和挖掘语义相关性,并且没有充分挖掘文本模态对hoi检测的能力。
技术实现要素:
4.1.要解决的技术问题
5.针对现有技术中在hoi检测人物时存在模态融合粗糙、模态之间差异较大等问题,本发明提供了一种人物交互检测模型、方法、系统及装置,它可以实现人物模态之间的对齐,生成细粒度的多模态特征,通过文本特征监督视觉特征学习,提升人物交互检测精度。
6.2.技术方案
7.本发明的目的通过以下技术方案实现。
8.一种人物交互检测模型,包括:
9.重挖掘视觉模块,包括主干网络、视觉实例检测模块、交互关系模块和池化层;输入图像到主干网络中,主干网络对图像处理后得到特征图,输出特征图到视觉实例检测模块、交互关系模块及池化层中;视觉实例检测模块获取特征图的空间特征,交互关系模块获取特征图的交互特征,池化层通过池化操作获取特征图的全局特征;将空间特征、交互特征和全局特征融合后得到融合特征,输出融合特征到交互解码器中得到解码后的融合特征;
10.语言知识生成模块,将文本标签映射为tokens,所述tokens通过token编码器处理得到文本特征;所述文本特征包括类别特征和可变长词嵌入特征;
11.交互模态学习模块,包括自注意力模块和交叉模态对齐模块,所述自注意力模块通过计算解码后的融合特征得到视觉特征,所述交叉模态对齐模块通过计算视觉特征和可变长词嵌入特征得到交叉注意力。
12.进一步地,所述视觉实例检测模块采用detr结构,获取特征图的实例特征、实例位
置及实例类别,通过实例类别获取人物交互对,人物交互对中的实例特征组合成所述空间特征,通过实例位置获取交互位置信息,通过实例类别获取交互类别信息;
13.所述空间特征表示为:sv∈rn×
dv
,所述交互位置信息表示为:bv∈rn×4,所述交互类别信息表示为:cv∈rn×
nc
,
14.其中,sv表示空间特征,bv表示交互位置信息,cv表示交互类别信息,r表示实数,n表示人物交互对的数量,dv表示空间特征的向量维度,nc表示实例类别数量。
15.进一步地,所述交互关系模块中,特征图通过交互关系编码器处理得到特征增强图,特征增强图与所述视觉实例检测模块中的交互位置信息结合,通过感兴趣区域裁剪操作,在特征增强图上得到与人物交互对对应的局部区域特征,局部区域特征为所述交互特征,所述交互特征的计算公式为:
[0016][0017]
其中,mv表示交互特征,fc表示全连接层,gap表示全局平均池化,roip表示感兴趣区域裁剪操作,hv表示交互关系模块的输出,表示交互特征的维度。
[0018]
进一步地,所述文本标签由所述视觉实例检测模块中获得的人物交互对对应的类别生成;所述类别特征用于表征文本含义,所述可变长词嵌入特征用于表征文本中词的含义;所述类别特征、可变长词嵌入特征的计算公式为:
[0019][0020]
其中,ec表示类别特征,ew表示可变长词嵌入特征,f
te
表示token编码器,z
l
表示文本标签对应的tokens。
[0021]
进一步地,所述自注意力模块用于增强解码后的融合特征的表征能力,自注意力模块的计算公式为:
[0022][0023]
其中,q表示transformer结构中的查询向量,k表示transformer结构中的键向量,v表示transformer结构中的值向量,dk表示k的维度,qk
t
表示查询向量与键向量转置的内积;
[0024]
所述自注意力模块通过计算解码后的融合特征得到视觉特征,所述视觉特征的计算公式为:
[0025]ovs
=attn(ov,ov,ov)
[0026]
其中,o
vs
表示视觉特征,ov表示解码后的融合特征;
[0027]
通过交叉模态对齐模块,计算视觉特征和可变长词嵌入特征得到交叉注意力,所述交叉注意力将文本特征融合到视觉特征中,用于增强视觉特征的表征能力;
[0028]
所述交叉注意力的计算公式为:
[0029][0030]
其中,表示交叉注意力。
[0031]
进一步地,通过交叉模态对齐损失及类别损失计算多模态损失,所述多模态损失的计算公式为:
[0032]
[0033]
其中,lm表示多模态损失,la表示交叉模态对齐损失,lc表示类别损失,ffn(ov)表示前馈网络,d
l1
表示l1损失,l1表示计算绝对平均误差,所述d
l1
的计算公式为:
[0034][0035]
其中,e
ho
表示人物交互对对应的文本标签的类别特征,f
ho
表示人物交互对的融合特征,m表示f
ho
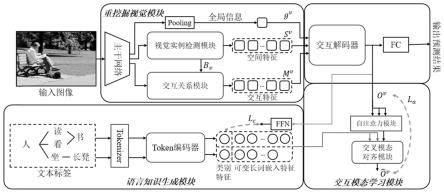
的向量长度,i表示向量元素。
[0036]
进一步地,所述解码后的融合特征通过全连接层输出hoi预测的交互类别,通过focal loss计算交互损失,所述交互损失的计算公式为:
[0037]
l
hoi
=focal(sigmoind(p),gt)
[0038]
focal(p)=-(1-p)
γ
log(p)
[0039]
其中,l
hoi
表示交互损失,gt表示人物交互对的真实标签,p表示交互对的预测结果,focal(p)表示focal loss的计算,γ为超参数。
[0040]
一种基于所述的人物交互检测模型的方法,步骤如下:
[0041]
训练阶段:
[0042]
采用预训练的detr模型获取特征图中的实例特征、实例位置及实例类别,通过实例类别获取人物交互对,人物交互对中的实例特征组合成空间特征,通过实例位置获取交互位置信息,通过实例类别获取交互类别信息;
[0043]
对主干网络输出的特征图通过交互关系编码器得到特征增强图,特征增强图与视觉实例检测模块中的交互位置信息结合,通过感兴趣区域裁剪操作,在特征增强图上得到与人物交互对对应的局部区域特征,即交互特征;
[0044]
池化层通过池化操作获取特征图的全局特征;
[0045]
将空间特征、交互特征和全局特征融合后得到融合特征,输出融合特征到交互解码器中得到解码后的融合特征;
[0046]
通过视觉实例检测模块中获得的人物交互对对应的类别生成文本标签,将文本标签映射为tokens,所述tokens通过token编码器处理得到文本特征;所述文本特征包括类别特征和可变长词嵌入特征;
[0047]
通过交叉模态对齐损失与类别损失计算多模态损失;
[0048]
解码后的融合特征通过自注意力模块得到视觉特征,输入视觉特征与可变长词嵌入特征到交叉模态对齐模块中融合得到交叉注意力;
[0049]
解码后的融合特征通过全连接层输出hoi预测的交互类别,通过focal loss计算交互损失;
[0050]
推理阶段:
[0051]
采用预训练的detr模型获取特征图中的实例特征、实例位置及实例类别,通过实例类别获取人物交互对,人物交互对中的实例特征组合成空间特征,通过实例位置获取交互位置信息,通过实例类别获取交互类别信息;
[0052]
对主干网络输出的特征图通过交互关系编码器得到特征增强图,特征增强图与视觉实例检测模块中的交互位置信息结合,通过感兴趣区域裁剪操作,在特征增强图上得到与人物交互对对应的局部区域特征,即交互特征;
[0053]
池化层通过池化操作获取特征图的全局特征;
[0054]
将空间特征、交互特征和全局特征融合后得到融合特征,输出融合特征到交互解码器中得到解码后的融合特征;
[0055]
解码后的融合特征通过全连接层输出hoi预测的交互类别。
[0056]
一种人物交互检测系统,其采用所述的基于人物交互检测模型及方法对输入的图像进行人物交互检测;所述人物交互检测系统包括:
[0057]
输入模块,输入图像;
[0058]
重挖掘视觉模块,图像通过主干网络处理得到特征图,所述特征图输出到视觉实例检测模块获取特征图的空间特征,所述特征图输出到交互关系模块获取特征图的交互特征,通过池化操作获取特征图的全局特征;将空间特征、交互特征和全局特征融合后得到融合特征,输出融合特征到交互解码器中得到解码后的融合特征;
[0059]
语言知识生成模块,通过视觉实例检测模块中获得的人物交互对对应的类别生成文本标签,将文本标签映射为tokens,所述tokens通过token编码器处理得到文本特征;所述文本特征包括类别特征和可变长词嵌入特征;
[0060]
交互模态学习模块,包括自注意力模块和交叉模态对齐模块,所述自注意力模块通过计算解码后的融合特征得到视觉特征,所述交叉模态对齐模块通过计算视觉特征和可变长词嵌入特征得到交叉注意力;
[0061]
输出模块,输出预测结果。
[0062]
一种人物交互检测装置,包括存储器、处理器以及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述程序时实现所述的基于人物交互检测方法的步骤。
[0063]
3.有益效果
[0064]
相比于现有技术,本发明的优点在于:
[0065]
本发明的一种人物交互检测模型、方法、系统及装置,通过重挖掘视觉模块、语言知识生成模块及交互模态学习模块,增强了模态之间的关联特征,实现了细粒度的模态之间的特征对齐,并且采用知识蒸馏的方式,通过文本特征监督视觉特征学习;同时,在hoi人物交互检测的推理阶段,语言知识生成模块和交互模态学习模块不再参与计算,不会增加额外的推理时间,缩小了视觉特征和文本特征之间的异质性差距,进一步提升了人物交互检测的精度。
附图说明
[0066]
图1为本发明的网络结构框架图。
具体实施方式
[0067]
下面结合说明书附图和具体的实施例,对本发明作详细描述。
[0068]
实施例
[0069]
如图1所示,本实施例提供的一种人物交互检测模型,包括重挖掘视觉模块、语言知识生成模块和交互模态学习模块。
[0070]
具体到本实施例中,输入图像到所述重挖掘视觉模块中,输入的图像的维度为h
×w×
3,其中,h表示图像的长度,w表示图像的宽度,3表示图像的通道数。重挖掘视觉模块中的主干网络将图像的长度缩小32倍、宽度缩小32倍、通道数增加到2048维,得到特征图,所述特征图的维度为h/32
×
w/32
×
2048维。进而通过一个1
×
1维的卷积层,将特征图的维度下采样至h/32
×
w/32
×
512维。由此,通过主干网络处理后可以更好地识别图像的特征。本实施例中,所述主干网络可以选择resnet50、resnet101或其他网络等。
[0071]
具体地,在所述重挖掘视觉模块中还包括视觉实例检测模块、交互关系模块和池化层(pooling),分别输出特征图到所述视觉实例检测模块、交互关系模块和池化层中。
[0072]
所述视觉实例检测模块采用detr结构,获取特征图的实例特征、实例位置及实例类别,通过实例类别获得所有的人物交互对,通过实例标签对人物交互对进行组合从而得到组合对实例,检测组合对实例的分数,将组合对实例的检测分数相乘用于表示组合对的分数,选择组合对分数大于阈值的组合对作为人物交互对。在每组交互对中,人物交互对中的实例特征组合成空间特征,由实例位置取并集得到交互位置信息,由实例类别得到交互类别信息。
[0073]
所述空间特征表示为:sv∈rn×
dv
,所述交互位置信息表示为:bv∈rn×4,所述交互类别信息表示为:cv∈rn×
nc
,
[0074]
其中,sv表示空间特征,bv表示交互位置信息,cv表示交互类别信息,r表示实数,n表示人物交互对的数量,dv表示空间特征的向量维度,nc表示实例类别数量。本实施例中,空间特征的向量维度dv为n
×
512维,实例类别数量nc为80类。
[0075]
进一步地,通过交互位置信息可以在主干网络输出的特征图h/32
×
w/32
×
512维度上通过裁剪操作得到对应的人物交互区域。
[0076]
所述交互关系模块中包括交互关系编码器,特征图通过交互关系编码器处理得到特征增强图,特征增强图与所述视觉实例检测模块中人物交互对的交互位置信息结合,通过感兴趣区域裁剪操作,在特征增强图上得到与hoi人物交互对对应的局部区域特征,所述局部区域特征为交互特征,所述交互特征的计算公式为:
[0077][0078]
其中,mv表示交互特征,fc表示全连接层,gap表示全局平均池化,roip表示感兴趣区域裁剪操作,hv表示交互关系模块的输出,表示交互特征的维度。
[0079]
在所述交互关系模块中,特征增强图的维度为h
×w×
512维,通过裁剪操作,得到n
×h×w×
512维的特征,其中,n表示人物交互对数量,h表示裁剪后特征增强图的长度,w表示裁剪后特征增强图的宽度,通过全局平均池化操作,得到交互特征的向量维度为n
×
512维。
[0080]
需要说明的是,本实施例所述交互关系模块采用的是标准的transformer结构。
[0081]
所述池化层中,特征图通过全局池化操作,获取特征图的全局信息,此时,特征图的维度为1
×1×
2048维,通过对齐降维操作,得到特征图的向量维度为1
×
512维。
[0082]
由此,通过重挖掘视觉模块,获得空间特征的向量维度为n
×
512维、交互特征的向量维度为n
×
512维以及全局特征的向量维度1
×
512维,将获得的三组特征向量通过cat方式融合后得到融合特征,将所述融合特征输出到交互解码器中解码。具体地,将全局特征的向量维度扩展为n
×
512维后,将三组特征向量在第一维度按顺序堆叠得到融合特征,由此,融合特征的向量维度为n
×
1536维,输出融合特征到交互解码器中得到解码后的融合特征。
[0083]
所述语言知识生成模块由视觉实例检测模块中获得的人物交互对对应的类别生成文本标签。如图1所示,输入的图像中包含了三种人物交互组合,分别为人读书(human read book)、人看书(human look book)以及人坐在长凳上(human sit on couch)。将文本标签通过tokenizer生成对应的tokens,每个词对应一个token,token编码器将tokens编码为对应的文本特征,该文本特征包括类别特征和可变长词嵌入特征。所述类别特征用于表征文本含义,所述可变长词嵌入特征用于表征文本中词的含义;本实施例中,所述token编码器为自然语言处理模型,如bert、mobilebert等。所述类别特征及可变长词嵌入特征的计算公式为:
[0084][0085]
其中,ec表示类别特征,ew表示可变长词嵌入特征,f
te
表示token编码器,z
l
表示文本标签对应的tokens。
[0086]
本实施例中,类别特征ec的向量维度为1
×
512维,可变长词嵌入特征ew的向量维度为nw×
512维,其中,nw表示对应文本标签中的词的数量。
[0087]
所述交互模态学习模块包括自注意力模块和交互模态对齐模块。所述自注意力模块用于增强经交互解码器解码后的融合特征,自注意力模块的计算公式为:
[0088][0089]
其中,q表示transformer结构中的查询(query)向量,k表示transformer结构中的键(key)向量,v表示transformer结构中的值(value)向量,dk表示k的维度,qk
t
表示查询(query)向量与键(key)向量转置的内积。
[0090]
由此,本实施例提供的一种人物交互检测模型,通过重挖掘视觉模块、语言知识生成模块及交互模态学习模块,增强了各个模块之间的关联特征,从而可以实现细粒度的模态之间的特征对齐。
[0091]
进而,通过自注意力模块计算解码后的融合特征得到视觉特征,所述视觉特征的计算公式为:
[0092]ovs
=attn(ov,ov,ov)
[0093]
其中,o
vs
表示视觉特征,ov表示解码后的融合特征;视觉特征o
vs
的向量维度为n
×
512维。
[0094]
通过交叉模态对齐模块,计算视觉特征和可变长词嵌入特征得到交叉注意力,所述交叉注意力将文本特征融合到视觉特征中,用于增强视觉特征的表征能力;所述交叉注意力的计算公式为:
[0095][0096]
其中,表示交叉注意力;
[0097]
同时,通过交叉模态对齐损失及类别损失计算多模态损失,从而通过文本特征监督视觉特征学习;所述的计算公式为:
[0098][0099]
其中,lm表示多模态损失,la表示交叉模块对齐损失,lc表示类别损失,ffn(ov)表示前馈网络,d
l1
表示l1损失,l1表示计算绝对平均误差,所述d
l1
的计算公式为:
[0100][0101]
其中,e
ho
表示人物交互对对应的文本标签的类别特征,f
ho
表示人物交互对的融合特征,m表示f
ho
的向量长度,i表示向量元素,本实施例中,求和符合∑用于计算从第1个向量元素到第m个向量元素的差值的绝对值的和。
[0102]
如图1所示,将经交互解码器解码后的融合特征通过全连接层(fc)层输出hoi预测的交互类别,通过focal loss计算交互损失l
hoi
,所述交互损失l
hoi
的计算公式为:
[0103]
l
hoi
=focal(sigmoind(p),gt)
[0104]
focal(p)=-(1-p)
γ
log(p)
[0105]
其中,gt表示人物交互对的真实标签,p表示交互对的预测结果,focal(p)表示focal loss的计算,γ为超参数,本实施例中,γ取值为0.2。
[0106]
本实施例中,loss函数均通过l=λ1l
hoi
+λmlm计算,其中,λ1取值为2,λm取值为1。
[0107]
本实施例中,所述交叉注意力将文本特征融合到视觉特征中,用于增强视觉特征的表征能力,即通过知识蒸馏的方式,利用文本特征监督视觉特征学习,进一步提升人物交互检测精度。
[0108]
由此,本实施例提供的一种人物交互检测方法,
[0109]
在训练阶段,输入图像到重挖掘视觉模块中,通过主干网络对图像进行处理,得到特征图;采用预训练的detr模型获取特征图中的实例特征、实例位置及实例类别,通过实例类别获取人物交互对,人物交互对中的实例特征组合成空间特征,通过实例位置获取交互位置信息,通过实例类别获取交互类别信息;对主干网络输出的特征图通过交互关系编码器得到特征增强图,特征增强图与视觉实例检测模块中的交互位置信息结合,通过感兴趣区域裁剪操作,在特征增强图上得到与人物交互对对应的局部区域特征,即交互特征;在池化层中通过池化操作获取特征图的全局特征;将空间特征、交互特征和全局特征融合后得到融合特征,输出融合特征到交互解码器中得到解码后的融合特征;通过视觉实例检测模块中获得的人物交互对对应的类别生成文本标签,将文本标签映射为tokens,所述tokens通过token编码器处理得到文本特征;所述文本特征包括类别特征和可变长词嵌入特征;由此,通过交叉模态对齐损失与类别损失计算多模态损失;解码后的融合特征通过自注意力模块得到视觉特征,输入视觉特征与可变长词嵌入特征到交叉模态对齐模块中融合得到交叉注意力;解码后的融合特征通过全连接层输出hoi预测的交互类别,通过focal loss计算交互损失;
[0110]
在推理阶段,输入图像到重挖掘视觉模块中,通过主干网络对图像进行处理,得到特征图;采用预训练的detr模型获取特征图中的实例特征、实例位置及实例类别,通过实例类别获取人物交互对,人物交互对中的实例特征组合成空间特征,通过实例位置获取交互位置信息,通过实例类别获取交互类别信息;对主干网络输出的特征图通过交互关系编码器得到特征增强图,特征增强图与视觉实例检测模块中的交互位置信息结合,通过感兴趣区域裁剪操作,在特征增强图上得到与人物交互对对应的局部区域特征,即交互特征;在池化层中通过池化操作获取特征图的全局特征;将空间特征、交互特征和全局特征融合后得到融合特征,输出融合特征到交互解码器中得到解码后的融合特征;解码后的融合特征通
过全连接层输出hoi预测的交互类别。
[0111]
值得说明的是,在人物交互检测模型的推理阶段,语言知识生成模块和交互模态学习模块不再参与计算,不会增加额外的推理时间,缩小了视觉特征和文本特征之间的异质性差距,有效提高人物交互检测效率。
[0112]
本实施例还提供一种人物交互检测系统,基于人物交互检测方法对输入的图像进行人物交互检测;所述人物交互检测系统包括:
[0113]
输入模块,输入图像;
[0114]
重挖掘视觉模块,图像通过主干网络处理得到特征图,所述特征图输出到视觉实例检测模块获取特征图的空间特征,所述特征图输出到交互关系模块获取特征图的交互特征,通过池化操作获取特征图的全局特征;将空间特征、交互特征和全局特征融合后得到融合特征,输出融合特征到交互解码器中得到解码后的融合特征;
[0115]
语言知识生成模块,通过视觉实例检测模块中获得的人物交互对对应的类别生成文本标签,将文本标签映射为tokens,所述tokens通过token编码器处理得到文本特征;所述文本特征包括类别特征和可变长词嵌入特征;
[0116]
交互模态学习模块,包括自注意力模块和交叉模态对齐模块,所述自注意力模块通过计算解码后的融合特征得到视觉特征,所述交叉模态对齐模块通过计算视觉特征和可变长词嵌入特征得到交叉注意力;
[0117]
输出模块,输出预测结果。
[0118]
本实施例还提供一种人物交互检测装置,人物交互检测装置为一种计算机设备,包括存储器、处理器以及存储在存储器上并可在处理器上运行的计算机程序。处理器执行程序时实现如本实施例中人物交互检测方法的步骤。该计算机设备可以是可以执行程序的智能手机、平板电脑、笔记本电脑、台式计算机、机架式服务器、刀片式服务器、塔式服务器或机柜式服务器(包括独立的服务器,或者多个服务器所组成的服务器集群)等。本实施例的计算机设备至少包括但不限于:可通过系统总线相互通信连接的存储器、处理器。存储器(即可读存储介质)包括闪存、硬盘、多媒体卡、卡型存储器(例如,sd或dx存储器等)、随机访问存储器(ram)、静态随机访问存储器(sram)、只读存储器(rom)、电可擦除可编程只读存储器(eeprom)、可编程只读存储器(prom)、磁性存储器、磁盘、光盘等。存储器可以是计算机设备的内部存储单元,例如该计算机设备的硬盘或内存,也可以是计算机设备的外部存储设备,例如该计算机设备上配备的插接式硬盘,智能存储卡(smart media card,smc),安全数字(secure digital,sd)卡,闪存卡(flash card)等。当然,存储器还可以既包括计算机设备的内部存储单元也包括其外部存储设备。本实施例中,存储器通常用于存储安装于计算机设备的操作系统和各类应用软件等。此外,存储器还可以用于暂时地存储已经输出或者将要输出的各类数据。处理器在一些实施例中可以是中央处理器(central processing unit,cpu)、控制器、微控制器、微处理器、或其他数据处理芯片。该处理器通常用于控制计算机设备的总体操作,在本实施例中,处理器用于运行存储器中存储的程序代码或者处理数据。
[0119]
以上示意性地对本发明创造及其实施方式进行了描述,该描述没有限制性,在不背离本发明的精神或者基本特征的情况下,能够以其他的具体形式实现本发明。附图中所示的也只是本发明创造的实施方式之一,实际的结构并不局限于此,权利要求中的任何附
图标记不应限制所涉及的权利要求。所以,如果本领域的普通技术人员受其启示,在不脱离本创造宗旨的情况下,不经创造性的设计出与该技术方案相似的结构方式及实施例,均应属于本专利的保护范围。此外,“包括”一词不排除其他元件或步骤,在元件前的“一个”一词不排除包括“多个”该元件。产品权利要求中陈述的多个元件也可以由一个元件通过软件或者硬件来实现。第一,第二等词语用来表示名称,而并不表示任何特定的顺序。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1