基于计算机视觉与深度学习的施工人员智能监测系统
1.本发明涉及智能统计技术领域,具体来说,涉及基于计算机视觉与深度学习的施工人员智能监测系统。
背景技术:
2.目前,在建筑施工过程中,要求施工现场原则上实施封闭式管理,设立进出场门禁系统。当前建筑施工现场所使用的门禁系统多为由三辊闸,摆闸,翼闸,不锈钢栅栏门等通道系统与感应卡读写器结合构成的系统,所有管理人员和施工人员提前将人脸或者二代身份证录入系统后便可自由进出,人员未经登记和授权则无法擅自进入施工现场,同时在施工现场出入口安装监控摄像头,将一段时间内的视频录像存储在本地服务器内以便查阅。
3.然而,目前的门禁系统在实际应用时存在以下缺陷:
4.1)建筑工地出入口处人员出入频繁,人员无序流动,现场管理困难;2)采用纸质记录考勤数据,难以准确统计实际工时,且数据易被篡改;3)施工现场人员数量多、分包单位多、工种和岗位多的特点,项目管理人员无法清晰和及时掌握现场的施工作业人员数量、各工种人员数量和各专业分包单位人数,不利于现场管理效率提高;4)发生建筑劳务人员工资纠纷时,监管部门难以取证,维权困难重重;5)车辆以及车辆内人员进出场统计困难。
5.针对相关技术中的问题,目前尚未提出有效的解决方案。
技术实现要素:
6.针对相关技术中的问题,本发明提出基于计算机视觉与深度学习的施工人员智能监测系统,以克服现有相关技术所存在的上述技术问题。
7.为此,本发明采用的具体技术方案如下:
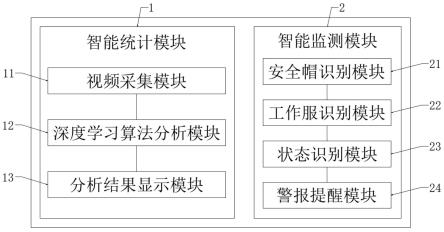
8.基于计算机视觉与深度学习的施工人员智能监测系统,该系统包括智能统计模块和智能监测模块;
9.其中,所述智能统计模块用于利用训练好的深度学习算法对通过工地入口的施工人员进行检测,并通过跟踪算法对目标进行跟踪,在目标碰撞检测线时进行计数并统计,同时通过客户端进行实时展示;
10.所述智能监测模块用于利用预设的图像识别技术分别对通过工地入口的施工人员的着装及状态进行识别,并对不符合标准的施工人员进行提醒。
11.进一步的,所述智能统计模块包括视频采集模块、深度学习算法分析模块及分析结果显示模块;
12.所述视频采集模块用于根据架设在施工现场各出入口的监控摄像头采集实时监控画面,并将实时监控画面输入poe交换机经转换后得到初始视频素材;
13.所述深度学习算法分析模块用于通过训练好的深度学习算法实时输出与初始视频素材相对应的视频分析画面以及人员统计数据,并将分析画面和统计结果输出至客户端;
14.所述分析结果显示模块用于在客户端显示视频分析画面及人员与车辆的统计数据,还用于管理人员根据需求切换不同出入口摄像头所获取的分析画面以及统计数据。
15.进一步的,所述深度学习算法分析模块包括检测区域设定模块、视频分析模块、数据统计模块及数据传输模块;
16.所述检测区域设定模块用于根据不同出入口的画面布局,通过对相应的检测范围进行调整来控制各个画面中的实际检测范围,实现检测区域的设定;
17.所述视频分析模块用于通过撞线检测点坐标来对初始视频素材中的图像进行分析,实现对检测区域人员及车辆的分析及统计;
18.所述数据统计模块用于通过目标框是否撞线及目标框撞线区域的颜色来实现对目标进出的判定和统计;
19.所述数据传输模块用于将分析画面和统计结果通过rtsp服务器以及http推送服务输出至客户端。
20.进一步的,所述检测区域的设定包括以下步骤:
21.依照所需区域的形状依次确定各处端点位置并通过一个数组来表达,且该数组的每个元素为表征图形端点的二元数组,通过数组的调整来实现检测区域的调整及设定。
22.进一步的,所述通过撞线检测点坐标来对初始视频素材中的图像进行分析,实现对检测区域人员及车辆的分析及统计包括以下步骤:
23.获取当前图像中所有物体的位置参数及类别;
24.判断新一帧图像中是否有物体的几何中心与上一帧图像中某个物体几何中心的偏移量在预设偏移量内,若是,则判定两个物体为同一物体,拥有相同id,若否,则判定新一帧图像中存在新物体,并为该物体赋予新id;
25.采用矩形表示物体范围且已知物体id的图像,设某个物体范围的参数为x1,y1,x2,y2,其中x1《x2,y1《y2,撞线检测点坐标为(check_point_x,check_point_y),check_point_x=x1,check_point_y=int[y1+(y
2-y1)*0.6],int指对运算结果取整;
[0026]
判断物体撞线检测点是否位于判定区内,若是,则对该物体进行统计运算,若否,则不进行统计运算。
[0027]
进一步的,所述通过目标框是否撞线及目标框撞线区域的颜色来实现对目标进出的判定和统计包括以下步骤:
[0028]
规定当前摄像头所捕捉到的全部画面为检测区域,并设定蓝色与黄色的条形区域为判定区,且当目标上行撞黄线时记为进,目标下行撞蓝线时记为出;
[0029]
获取施工现场各出入口监控摄像头采集的实时监控画面,并对获取的实时监控画面进行尺寸缩小处理;
[0030]
判断缩小后的实时监控画面的检测区域中是否有目标出现,若否,则将该监控画面视为无效画面并进行忽略清理,若是,则为目标赋框后输出;
[0031]
检测目标框是否撞线及目标框撞线区域的颜色,并依据目标框撞线区域的颜色对目标的进出进行判定与统计。
[0032]
进一步的,所述智能监测模块包括安全帽识别模块、工作服识别模块、状态识别模块及警报提醒模块;
[0033]
所述安全帽识别模块用于利用图像识别技术对通过工地入口的未佩带安全帽的
施工人员进行识别;
[0034]
所述工作服识别模块用于利用图像识别技术对通过工地入口的未穿着工作服的施工人员进行识别;
[0035]
所述状态识别模块用于利用图像识别技术对通过工地入口的施工人员的精神状态进行识别;
[0036]
所述警报提醒模块用于对未佩戴安全帽、未穿着工作服及精神状态不符合标准的施工人员进行提醒。
[0037]
进一步的,所述状态识别模块包括施工人员面部图像获取模块、融合特征识别模块及状态识别结果输出模块;
[0038]
所述施工人员面部图像获取模块用于获取施工现场各出入口实时监控画面中施工人员的面部图像;
[0039]
所述融合特征识别模块用于利用基于独立特征融合的面部状态识别算法对施工人员的面部图像进行识别,实现对进入施工现场的施工人员的精神状态进行识别;
[0040]
所述状态识别结果输出模块用于输出施工现场各出入口实时监控画面中施工人员的精神状态信息。
[0041]
进一步的,所述融合特征识别模块包括全局状态特征提取模块、局部状态特征提取模块、状态特征融合模块及状态特征分析识别模块;
[0042]
所述全局状态特征提取模块用于通过离散余弦变换提取面部图像的全局状态特征,并利用独立成分分析技术对全局状态特征的相关性进行去除,得到独立全局状态特征;
[0043]
所述局部状态特征提取模块用于提取图像序列中眼部和嘴部区域的特征,并分别对眼部和嘴部区域进行gabort小波变换和特征融合,得到两个局部区域的动态多尺度特征作为面部图像的局部状态特征;
[0044]
所述状态特征融合模块用于将独立全局状态特征与局部状态特征进行融合,在全局特征中加入局部细节信息,得到面部状态融合特征;
[0045]
所述状态特征分析识别模块用于通过预设的分类器对得到的面部状态融合特征进行分析与识别,得到施工人员的精神状态信息,其中,所述施工人员的精神状态包括清醒状态、轻度疲劳状态、中度疲劳状态及重度疲劳状态。
[0046]
进一步的,所述预设的分类器通过adaboost算法挑选部分特征,去除冗余特征并进行训练得到,所述预设的分类器的计算公式为:
[0047][0048]
其中,t表示算法循环的最终次数,a
t
表示分类器h
t
(x)被挑选的权值,由adaboost算法学习确定,x=(x1,x2,
…
,x
t
)表示挑选出来的面部图像序列的动态gabor特征。
[0049]
本发明的有益效果为:
[0050]
1)通过利用训练好的深度学习算法对通过工地入口的施工人员进行检测,并利用跟踪算法对目标进行跟踪,在目标碰撞检测线时进行计数并统计,从而可以实现对施工现
场人员及车辆进、出数量以及当地内人员与车辆总数的智能统计,此外,本发明还可以利用图像识别技术分别对通过工地入口的施工人员的着装及状态进行识别,并对不符合标准的施工人员进行提醒,从而可以有效地避免因施工人员未佩带安全帽、未穿着工作服或精神状态欠佳而导致的安全事故现象的发生,进而可以有效地提高施工现场的施工安全性能。
[0051]
2)本发明不仅可以在各类光照条件下识别准确率均能达到95%以上,而且还可以在保证统计数据准确地同时,使得分析画面与原画面时间差不超过1秒,具有识别准确率高和识别速度快的优点。
[0052]
3)基于本发明所使用的算法与ui所包含的可塑性,可根据不同的需求加入不同的功能,如人脸识别、工种识别等,可拓展性高;此外,本发明所需硬件设备价格低廉,在节约成本的同时提高现场管理效率获取更多的经济效益。
附图说明
[0053]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0054]
图1是根据本发明实施例的基于计算机视觉与深度学习的施工人员智能监测系统的结构框图;
[0055]
图2是根据本发明实施例的基于计算机视觉与深度学习的施工人员智能监测系统中深度学习算法分析模块的结构框图;
[0056]
图3是根据本发明实施例的基于计算机视觉与深度学习的施工人员智能监测系统中状态识别模块的结构框图;
[0057]
图4是根据本发明实施例的基于计算机视觉与深度学习的施工人员智能监测系统中融合特征识别模块的结构框图。
[0058]
图中:
[0059]
1、智能统计模块;2、智能监测模块;11、视频采集模块;12、深度学习算法分析模块;121、检测区域设定模块;122、视频分析模块;123、数据统计模块;124、数据传输模块;13、分析结果显示模块;21、安全帽识别模块;22、工作服识别模块;23、状态识别模块;231、施工人员面部图像获取模块;232、融合特征识别模块;2321、全局状态特征提取模块;2322、局部状态特征提取模块;2323、状态特征融合模块;2324、状态特征分析识别模块;233、状态识别结果输出模块;24、警报提醒模块。
具体实施方式
[0060]
为进一步说明各实施例,本发明提供有附图,这些附图为本发明揭露内容的一部分,其主要用以说明实施例,并可配合说明书的相关描述来解释实施例的运作原理,配合参考这些内容,本领域普通技术人员应能理解其他可能的实施方式以及本发明的优点,图中的组件并未按比例绘制,而类似的组件符号通常用来表示类似的组件。
[0061]
根据本发明的实施例,提供了基于计算机视觉与深度学习的施工人员智能监测系统。
[0062]
现结合附图和具体实施方式对本发明进一步说明,如图1-图4所示,根据本发明实施例的基于计算机视觉与深度学习的施工人员智能监测系统,该系统包括智能统计模块1和智能监测模块2;
[0063]
所述智能统计模块1用于利用训练好的深度学习算法对通过工地入口的施工人员进行检测,并通过跟踪算法对目标进行跟踪,在目标碰撞检测线时进行计数并统计,同时通过客户端进行实时展示;
[0064]
其中,所述智能统计模块1包括视频采集模块11、深度学习算法分析模块12及分析结果显示模块13;
[0065]
所述视频采集模块11用于根据架设在施工现场各出入口的监控摄像头采集实时监控画面,并将实时监控画面输入poe交换机经转换后得到初始视频素材;
[0066]
所述深度学习算法分析模块12用于通过训练好的深度学习算法实时输出与初始视频素材相对应的视频分析画面以及人员统计数据,并将分析画面和统计结果输出至客户端;
[0067]
其中,本实施例的算法采用的主干特征提取网络优于跨级部分网络,降低了显存消耗,在加强卷积神经网络的学习能力的同时,也进一步加宽网络,保证算法精度。在主干特征提取网络的训练策略中,为保障复杂环境下的识别精度,将多张图像进行拼接,模拟复杂环境下的物体。本算法还将更改后图像进行再次决策,改善决策边界的薄弱环境,提高系统鲁棒性。该算法识别物体有如下三步:
[0068]
首先,采用步长为2、卷积核为3
×
3的卷积层对图像进行5次采样,从而提取图像的主干特征,并产生五张不同尺寸特征层。
[0069]
其次,将较小尺寸特征层进行多尺度感受野融合并进行最大值池化,再通过张量拼接将处理后的小尺寸特征图与较大尺寸图进行参数聚合。故本算法在不同尺寸检测下依旧适用。
[0070]
最后,将特征层划分为不同尺寸的网格,目的在于能检测大小相差较大的各类目标,避免目标丢失。再对不同尺寸网格上产生多规格的先验框,每个先验框返回物体为预设物体类别概率,再将多个先验框中包含最大置信度的先验框作为物体实际位置,返回所有预设物体类别的置信度与物体实际位置。
[0071]
具体的,置信度区间是人为设定,置信度在算法识别出物体后给出。在测试中,置信度最低值为0.3,置信度区间为(0.3,1),在此区间下,由于待检测物体种类较为单一,自然环境变化小,识别正确率较高。最佳置信度区间受环境因素影响大,故不存在适用于不同环境的最佳置信度区间,应在实际环境下多次调试置信度区间才能得到对应条件下最佳置信度区间。
[0072]
具体的,所述深度学习算法分析模块12包括检测区域设定模块121、视频分析模块122、数据统计模块123及数据传输模块124;
[0073]
所述检测区域设定模块121用于根据不同出入口的画面布局,通过对相应的检测范围进行调整来控制各个画面中的实际检测范围,实现检测区域(检测区域包含全部画面范围,判定区仅包含蓝黄条形区,如果人员出现在画面中但未通过蓝黄条区,则该人员会被捕捉到但不会计入统计数据)的设定;
[0074]
本实施例中在现场测试过程中发现,需要对不同区域的视频画面检测范围进行调
整。一般来说,摄像头所获取的全部画面会被默认作检测区域进行识别,然而在实际应用中,往往不需要整个监控画面全部参与识别,例如在开发过程中测试的项目工地的主要人员进出通道,该通道画面主要包含闸机通道与右侧门卫值班室。算法在默认情况下会对整个画面中的人员进行识别与检测,如果有人员在值班室中来回走动,也会被算法判定为“进场”或者“出场”,这种误判会给系统统计结果造成巨大误差。因此,本系统在项目现场落地过程中,需要根据不同出入口的画面布局,对相应的后台算法检测范围进行调整。通过在算法代码设置检测区域,来控制各个画面中的实际检测范围。对于图像上的任意一点,都可以通过一个二元数组来确定,若需要设置一个检测区域,可依照所需区域的形状依次确定各处端点位置,此时的检测区域通过一个数组来表达,该数组的每个元素为表征图形端点的二元数组,从而用数组来达到调整几何区域的目的。所有进入该通道画面中的人员都会被识别出来,但是只有通过图中检测区域的人员会计入统计数据,而在检测区域以外活动的人员,不会对统计数据产生影响。
[0075]
所述视频分析模块122用于通过撞线检测点坐标来对初始视频素材中的图像进行分析,实现对检测区域人员及车辆的分析及统计;
[0076]
本实施例中的算法在完成初始化之后,就可识别并给出图像中的物体类别与范围,算法采用矩形框确定图像的位置,在平面内,确定一个矩形位置只需要知道其一条对角线坐标,例如右上角顶点坐标值(x1,y1)与左下角顶点坐标值(x2,y2)四个参数,即可确定矩形在图像的位置,故算法只需返回该四项参数与物体类别。算法返回的四个参数用于撞线检测点的确定和绘制矩形。在得到当前图像所有物体的位置参数与类别之后,若新一帧图像中有物体的几何中心与上一帧图像的一个物体几何中心的偏移量在设定偏移量以内,则两个物体视为同一物体,拥有相同id。若新一帧存在新物体,为该物体赋予新id。经过上述处理后,得到用矩形表示物体范围且已知物体id的图像。现设某物体范围的参数为x1,y1,x2,y2,其中x1《x2,y1《y2,撞线检测点坐标为(check_point_x,check_point_y),check_point_x=x1,check_point_y=int[y1+(y
2-y1)*0.6],int指对运算结果取整。仅当某一物体撞线检测点位于判定区内时,算法才会进行统计运算,否则不进行统计运算。
[0077]
所述数据统计模块123用于通过目标框是否撞线及目标框撞线区域的颜色来实现对目标进出的判定和统计;
[0078]
本实施例在实现人员统计功能时,采用了一种更为直观与准确的判定方式。即在算法中预设判定区,预设蓝色与黄色的条形区域为判定区。当目标上行撞黄线时记为进,目标下行撞蓝线时记为出,以此来计算行人进出数量。在算法运行时,将对视频进行处理,首先缩小尺寸再检测画面中是否有目标出现,假设画面中无目标出现,算法会将其视为无效画面忽略并清理,当画面中有目标存在时,算法会为目标赋框后输出,最后检测目标框是否撞线以及目标框所撞区域是为蓝色或者黄色作为目标进出的判断依据。
[0079]
所述数据传输模块124用于将分析画面和统计结果通过rtsp服务器以及http推送服务输出至客户端。
[0080]
视频素材在经过深度学习算法识别分析后,需要将分析画面输出到客户端内,为使实时监控画面与客户端内展示的分析画面之间的延迟降到最低,本实施例所使用的传输方式为rtsp服务器,rtsp(real time streaming protocol)实时流协议,在使用rtsp时,客户端和服务器都可以发出请求,也就是说,rtsp可以是双向的,可以根据实际负载情况对提
供服务的服务器进行转换,避免过多负载集中在同一个服务器上造成延迟。首先在算法中写入可以支持rtsp协议的视频流接口,然后根据摄像头的ip地址、端口号,设备用户名及密码等信息,获取rtsp流。进一步地,将流地址输入算法预设的接口内即可将分析画面传出到客户端内。
[0081]
与输出实时分析画面类似,在深度学习算法中统计得到的数据同样需要实时传输至客户端内,本实施例采用http实现数据传输。http(hyper text transfer protocol)即超文本传输协议,具有简单、灵活和易于扩展的优点。本实施例首先在服务端即深度学习算法内编写http程序,接着创建一个客户端到服务端的tcp连接并在客户端内写好数据请求报文,当客户端发送报文时就实现了一个http请求。在服务端接收请求后便会根据请求内容组织响应并复用tcp连接将响应内容回报至客户端,在客户端内解析并读取响应的内容最后实时显示在客户端用户界面上。
[0082]
所述分析结果显示模块13用于在客户端显示视频分析画面及人员与车辆的统计数据,还用于管理人员根据需求切换不同出入口摄像头所获取的分析画面以及统计数据。
[0083]
为使本实时视频分析画面更加直观的呈现给现场管理人员和方便现场管理人员根据需求获取不同出入口的分析画面,本实施例通过深度学习算法与虚幻4引擎的结合,在算法中加入rtsp和http推流服务,将所获取的视频分析画面和人员统计的结果实时展示在客户端,并在客户端添加其他功能。
[0084]
该客户端所包含的功能主要包括:
[0085]
(1)人员与车辆统计功能,包括人员与车辆进、出数量以及当地内人员与车辆总数;
[0086]
(2)视角切换功能,当在不同出入口架设多个摄像头时,可通过客户端在不同摄像头之间进行切换并实时获取该摄像头所记录的人员与车辆进出数据。
[0087]
所述智能监测模块2用于利用预设的图像识别技术分别对通过工地入口的施工人员的着装及状态进行识别,并对不符合标准的施工人员进行提醒。
[0088]
其中,所述智能监测模块2包括安全帽识别模块21、工作服识别模块22、状态识别模块23及警报提醒模块24;
[0089]
所述安全帽识别模块21用于利用图像识别技术对通过工地入口的未佩带安全帽的施工人员进行识别;
[0090]
所述工作服识别模块22用于利用图像识别技术对通过工地入口的未穿着工作服的施工人员进行识别;
[0091]
所述状态识别模块23用于利用图像识别技术对通过工地入口的施工人员的精神状态进行识别;
[0092]
具体的,所述状态识别模块23包括施工人员面部图像获取模块231、融合特征识别模块232及状态识别结果输出模块233;
[0093]
所述施工人员面部图像获取模块231用于获取施工现场各出入口实时监控画面中施工人员的面部图像;
[0094]
所述融合特征识别模块232用于利用基于独立特征融合的面部状态识别算法对施工人员的面部图像进行识别,实现对进入施工现场的施工人员的精神状态进行识别;
[0095]
所述融合特征识别模块232包括全局状态特征提取模块2321、局部状态特征提取
模块2322、状态特征融合模块2323及状态特征分析识别模块2324;
[0096]
所述全局状态特征提取模块2321用于通过离散余弦变换(discrete cosine transform,dct)提取面部图像的全局状态特征,并利用独立成分分析(independent component analysis,ica)技术对全局状态特征的相关性进行去除,得到独立全局状态特征;
[0097]
离散余弦变换是一种常用的图像数据压缩方法,对于一幅mxn的数字图像(x,y),其2d离散余弦变换的定义为:
[0098][0099][0100]
式中,u=0,1,2,...,m-1;v=0,1,2,...,n-1;
[0101]
离散余弦变换的特点是:当频域变化因子u、v较大时,dct系数c(u,v)的值很小;而数值较大的c(u,v)主要分布在u、v较小的左上角区域,这也是有用信息的集中区域,本实施例中便是提取此区域的有用信息作为图像的全局疲劳特征。
[0102]
独立主元分析作为一种用于解决盲信号分离问题的有效方法,通过ica能从混合信号中通过变换矩阵成功地分离出互相独立的源信号,这种性质用在疲劳特征提取方面不仅能降低疲劳特征向量的维数,还可以减少特征向量中各分量间的高阶相关性。
[0103]
人脸表情图像中除了pca方法能去除的二阶统计相关之外,高阶统计相关量也占有很大成分,因此,用ica方法去除表情图像中的高阶相关量将会得到更有鉴别能力的特征。ica算法的基本思想是用一组基函数来表示一系列随机变量,同时假设各成分之间统计独立或尽可能独立。
[0104]
本实施例中采用ica从面部图像序列的全局dct特征中通过变换矩阵成功地分离出互相独立的特征,这样不仅能降低特征向量的维数,还可以减少特征向量中各分量间的高阶相关性而得到更有鉴别能力的独立全局特征。
[0105]
所述局部状态特征提取模块2322用于提取图像序列中眼部和嘴部区域的特征,并分别对眼部和嘴部区域进行gabort小波变换和特征融合,得到两个局部区域的动态多尺度特征作为面部图像的局部状态特征;
[0106]
人脸疲劳时的表现特征具有不同的尺度,有整体的较大的尺度,也有细微的较小的尺度,所以单一尺度的分析很难提取到人脸疲劳表情的全部重要特征,然而利用多尺度分解,提取包含较多疲劳信息的尺度和方向上的特征进行分析,能更好地对面部视觉信息进行有效分析,对于面部视频图像序列,由于疲劳时不同的面部运动的尺度不同,因此需要用多尺度方法来分析疲劳信息。
[0107]
gabor小波是多尺度分析的有力工具,与dct相比,gabor变换同时在时域和频域获得最佳局部化,其变换系数描述了图像上给定位置附近区域的灰度特征,并且具有对光照、位置等不敏感的优点,适合用于表示人脸的局部特征,而由于dct更注重图像的全局信息,它往往忽略了在人脸识别过程中更为重要的局部信息,因此,本实施例中引人了gabor小波
变换进行图像局部多尺度特征的提取,并将之与独立全局特征进行融合,在全局信息中加入了图像的局部特征。
[0108]
所述状态特征融合模块2323用于将独立全局状态特征与局部状态特征进行融合,在全局特征中加入局部细节信息,得到面部状态融合特征;
[0109]
所述状态特征分析识别模块2324用于通过预设的分类器对得到的面部状态融合特征进行分析与识别,得到施工人员的精神状态信息,其中,所述施工人员的精神状态包括清醒状态(眼睛正常争开,眼球状态活跃,头部端正,注意力集中,眉毛平展)、轻度疲劳状态(眼球活跃程度下降,目光呆港,眉毛出现下垂趋势,额头紧皱,头部转动频率增加,精神不振)、中度疲劳状态(出现眼睛闭合、打哈欠、点头等现象,眉毛严重下垂,脸部肌肉变形严重)及重度疲劳状态(眼睛闭合趋势加重,且出现持续闭眼现象,注意力涣散)。
[0110]
所述预设的分类器通过adaboost算法挑选部分特征,去除冗余特征并进行训练得到,所述预设的分类器的计算公式为:
[0111][0112]
其中,t表示算法循环的最终次数,a
t
表示分类器h
t
(x)被挑选的权值,由adaboost算法学习确定,x=(x1,x2,
…
,x
t
)表示挑选出来的面部图像序列的动态gabor特征。
[0113]
所述状态识别结果输出模块233用于输出施工现场各出入口实时监控画面中施工人员的精神状态信息。
[0114]
所述警报提醒模块24用于对未佩戴安全帽、未穿着工作服及精神状态不符合标准的施工人员进行提醒。
[0115]
综上所述,借助于本发明的上述技术方案,通过利用训练好的深度学习算法对通过工地入口的施工人员进行检测,并利用跟踪算法对目标进行跟踪,在目标碰撞检测线时进行计数并统计,从而可以实现对施工现场人员及车辆进、出数量以及当地内人员与车辆总数的智能统计,此外,本发明还可以利用图像识别技术分别对通过工地入口的施工人员的着装及状态进行识别,并对不符合标准的施工人员进行提醒,从而可以有效地避免因施工人员未佩带安全帽、未穿着工作服或精神状态欠佳而导致的安全事故现象的发生,进而可以有效地提高施工现场的施工安全性能。
[0116]
同时,本发明不仅可以在各类光照条件下识别准确率均能达到95%以上,而且还可以在保证统计数据准确地同时,使得分析画面与原画面时间差不超过1秒,具有识别准确率高和识别速度快的优点。
[0117]
同时,基于本发明所使用的算法与ui所包含的可塑性,可根据不同的需求加入不同的功能,如人脸识别、工种识别等,可拓展性高;此外,本发明所需硬件设备价格低廉,在节约成本的同时提高现场管理效率获取更多的经济效益。
[0118]
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1