一种基于元学习的早产儿视网膜眼底图像定量化指标及分期方法与流程
本发明涉及了一种基于元学习的早产儿视网膜眼底图像定量化指标及分期方法,属于计算机视觉处理。
背景技术:
1、早产儿视网膜病变(retinopathy of prematurity,rop)是一种与视网膜血管发育相关的疾病,通常认为与氧气浓度有关。早产儿出生时视网膜血管未发育成熟,周边为无血管区,正在发育的血管末梢为未分化的新生血管。未成熟的视网膜血管对氧气十分敏感,高浓度氧气会使视网膜毛细血管内皮细胞损伤、血管收缩和闭塞,导致视网膜缺氧,从而刺激纤维血管组织增生。孕龄越短,rop发病率越高;早产儿体重越轻,rop发病率越高。我国的早产儿发生率约为6%-7%。rop会引起异常血管的破裂出血,纤维增殖,严重的可能会导致眼底病变,视力严重丧失。如果任其发展可能出现继发性青光眼、白内障、角巩膜葡萄肿、眼球萎缩等严重晚期并发症,甚至可导致失明,给患儿终身痛苦并给家庭及社会造成负担。
2、随着人工智能技术的发展,针对于rop疾病的自动筛查和分期成为可能,极大的缓解了医疗资源不足的问题,然而当前技术的应用仍然存在一定的问题。首先,rop数据来源广泛,不同设备或不同医院之间的数据集存在差异,无法直接进行应用,需要进行针对性的数据收集和模型训练,这将耗费大量人力物力财力和时间成本;其次,rop数据标注存在困难,由于rop病灶不清晰,因此需要专业的医师来标注,难以获得较多数据影像用于构建数据集;最后,rop分期存在困难,一般而言,临床上将rop分5期:即分界期、嵴形成期、增生期、次全视网膜脱离期、视网膜全脱离期,然而一期和二期之间过于相似难以分类。上述问题导致rop分期的临床应用存在较大困难。
技术实现思路
1、本发明所要解决的技术问题是提供一种基于元学习的早产儿视网膜眼底图像定量化指标及分期方法,通过引入元学习的方法,将原型分割网络adnet与gan相结合的分割模型的定量分析结果应用于rop病变分期,可以用少量的数据和更快的速度达到较好的效果,并且提高了早产儿视网膜病变一期二期的分类准确率。
2、为了解决上述技术问题,本发明所采用的技术方案是:
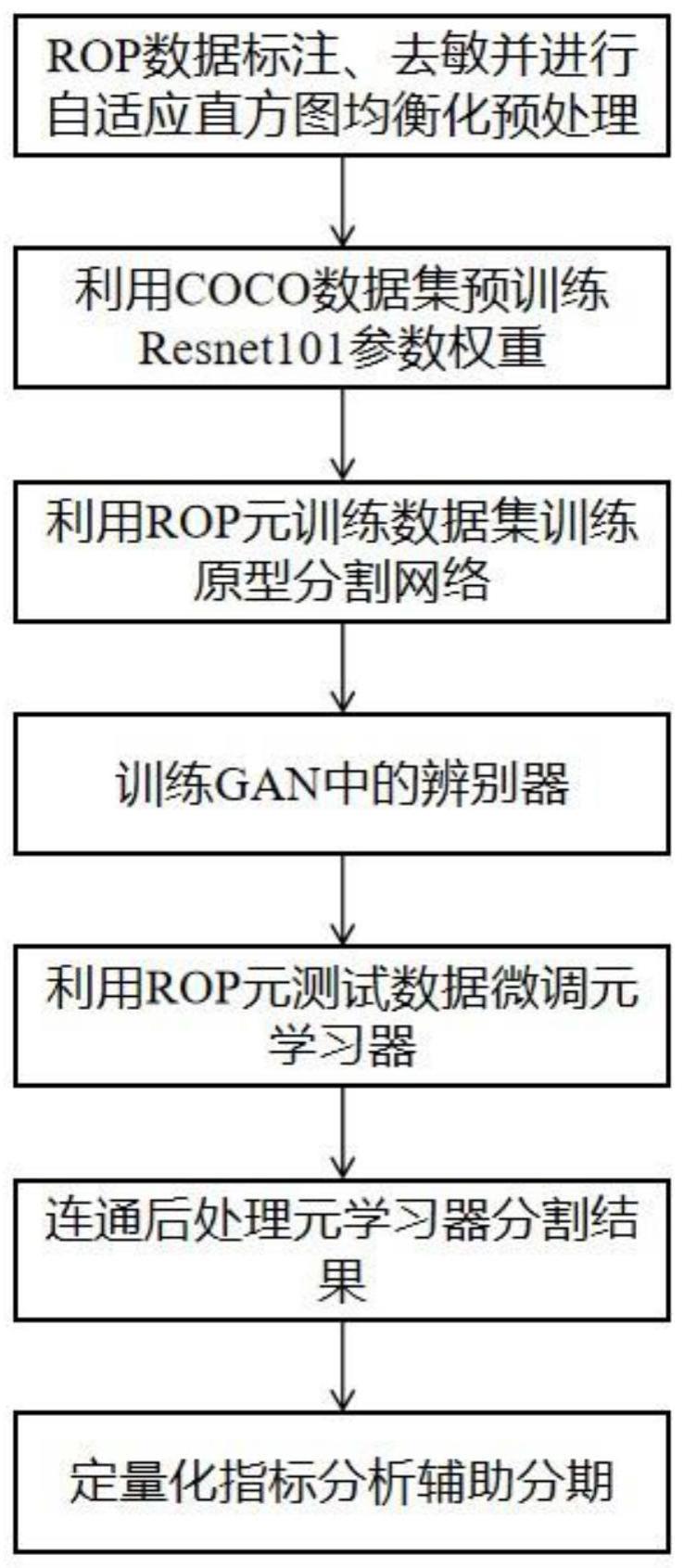
3、一种基于元学习的早产儿视网膜眼底图像定量化指标及分期方法,包括如下步骤:
4、(1)元数据采集:收集两组来源不同的rop数据集分别作为元学习训练过程的元训练数据和元学习测试过程的元测试数据,其中,元训练数据即为源域数据,元测试数据即为目标域数据,并将数据按照正常、一期、二期、三期、四期和五期共六个阶段分别放置在不同的文件夹中;
5、(2)元数据集的标注:使用labelme软件对rop数据集进行标注,得到rop病灶的分割mask,即金标准;
6、(3)元数据集预处理:使用快速进行算法去除rop影像上的病人信息,同时将rop影像转换到ycrcb空间,再使用自适应直方图均衡化,在保留rop细节的同时增强病灶和背景的对比度,之后将图片和标注图像进行扩增;
7、(4)建立元学习模型:使用了原型网络adnet和gan相结合的分割模型,作为rop病灶的分割任务的网络模型,使用resnet101作为骨架网络;
8、(5)元学习模型预训练:将元学习模型在coco数据集上以深度学习的方式进行预训练,保存好预训练权重;
9、(6)元学习模型元训练阶段:在源域数据中采集样本组成若干个训练任务进行模型训练,每个训练任务中均包含支持集和查询集,支持集用来生成病灶原型,查询集用来与病灶原型生成分割结果,元训练数据集的构建采取6-way和5-shot,即训练任务中包含六个类别(来自正常和一到五期),支持集中每个类别有5张训练图像,默认支持集中每个类别有15张图像,此外,损失函数选用交叉熵损失函数,并将该处损失记为l1。
10、(7)gan的辨别器的训练:只使用生成对抗网络中辨别器的部分,该辨别器是一个二分类卷积神经网络,该辨别器的训练需要用到元训练阶段的查询集图像及其分割结果图像和标注图像,辨别器的两个类别为:(a)rop原图及其分割结果图像;(b)rop原图及其标注图像,因此,同时输入辨别器的有两张图像,对于类别(a)的label为0(即fake),对于类别(b)的label为1(即true),此外,此处损失函数选用交叉熵损失函数,并将该处损失记为l2。
11、(8)网络参数更新:网络更新总损失l为l1和l2的总和,反向传播更新元学习器和辨别器。
12、(9)元学习模型元测试阶段:元测试阶段与元训练阶段类似,在目标域数据采集样本生成测试任务,每个测试任务也包含支持集和测试集,支持集用来生成病灶原型,测试集用来与病灶原型生成分割结果;
13、(10)分割结果后处理:对输出的分割结果进行后处理,处理方式为膨胀腐蚀,目的是连通分割出来的病灶区域,方便后续定量化指标的计算,包括长度、平均宽度、占比面积和明显程度,用于辅助rop分期分类,此外,首先需要对元测试数据集进行指标分析,统计分析不同分期的病灶的长度、平均宽度、占比面积和明显程度。然后再将元测试中查询集的分割结果的定量化指标与统计结果进行比对,从而进行rop分期。
14、前述的一种基于元学习的早产儿视网膜眼底图像定量化指标及分期方法,其特征在于:长度指标的计算需要使用骨架提取算法,具体算法如下:
15、
16、其中,n代表骨架像素点的数量;pibone代表第i个骨架像素点。
17、前述的一种基于元学习的早产儿视网膜眼底图像定量化指标及分期方法,其特征在于:将骨架一侧的病灶区域去掉,计算每个骨架像素点与距其最近的病灶边界像素点的距离,并将所有距离取平均值作为平均宽度,如下式所示:
18、
19、其中,n代表骨架像素点的个数,即病灶长度;pi代表第i个骨架像素点;pi′代表距离第i个骨架像素点最近的病灶边界像素点。
20、前述的一种基于元学习的早产儿视网膜眼底图像定量化指标及分期方法,其特征在于:占比面积的计算即病灶区域像素点数量占整张图像像素点数量的比值,如下式所示:
21、
22、其中,n代表病灶像素点的个数,k代表整张图像像素点的数量;代表第i个病灶像素点,代表第i个图像像素点。
23、前述的一种基于元学习的早产儿视网膜眼底图像定量化指标及分期方法,其特征在于:明显程度计算公式如下:
24、obvious=avesur-aveseg
25、其中,aveseg表示网络分割出来的病灶区域在原图上的平均像素值,avesur表示病灶区域周围的部分区域在原图上的平均像素值。
26、前述的一种基于元学习的早产儿视网膜眼底图像定量化指标及分期方法,其特征在于:l1的计算过程为:直接将分割结果与金标准,利用nn.crossentropyloss()函数,计算得到l1,具体的计算流程如下:对分割结果的每个像素值取log,然后与金标准相乘,最后再将每个元素相加取平均值,再取反,得到最终的l1;l2的计算过程为:利用nn.crossentropyloss()函数,计算得到l2,具体流程如下:辨别器输出一个二维向量,将该二维输出向量经过softmax函数处理,然后将该二维输出向量取log,对标签(非0即1)进行one-hot处理,得到一个二维标签向量,将二维输出向量与二维标签向量逐元素相乘,求和取平均值,得到l2;将l1和l2加起来得到总损失l,resnet101和辨别器中的每个参数都可以对总损失l链式求导得到一个梯度值,每个参数再梯度下降的方式更新参数值。本发明的有益效果是:
27、1、面对新的应用场景(如不同医院或不同成像设备)的rop影像时,可以使用少量的数据和时间便可以训练得到一个性能较好的模型;
28、2、通过对分割结果使用一些定量化指标分析,辅助早产儿视网膜一期二期的分类,能够达到一个更好的分类效果。
- 还没有人留言评论。精彩留言会获得点赞!