一种基于自编码网络的碑文文字修复模型及修复方法
1.本发明涉及一种基于自编码网络的碑文文字修复模型及修复方法,是一种端到端的修复网络,属于碑文文字修复技术领域。
背景技术:
2.现有技术中,文字修复模型较多,但是目前没有针对碑文修复的神经网络模型,碑文修复属于文字修复的一个子问题,其过程更加复杂。
3.中国的汉字结构性强,传统的图像修复方法无法完成该任务。近几年人工智能领域特别是深度学习技术的迅速发展,尤其是数字图像处理技术的发展为文字的自动修复提供了可能。
4.传统的图像修复算法主要有偏微分方程和补丁匹配,这两类方法都不能成出图像缺失的部分。偏微分方程方法是根据周围已知像素分布规律建立抛物型方程,利用方程将像素值扩散到破损区域。这类方法只能修复一些老照片的划痕,不能修复大坑洞,并且求解高维抛物型方程的数值解也存在很大难度。
5.补丁匹配方法从图像角度去修复,用图像中未破损部分匹配度最高的像素块去填充坑洞,甚至可以从外部数据库去搜索匹配度高的像素块去填充。
6.这两类传统的图像修复方法都缺乏对图像语义信息的理解,无法根据语义信息生成出缺失的部分,更无法应用到文字修复。
7.以神经网络为基础的文字修复分为两类,一类是以提高不完整手写汉字的识别准确率为目标,另一类以数字化保护古籍文献为目的,第二类有gan和u-net两种模型。基于gan和u-net网络的两种模型都有缺陷,特别是基于gan网络的模型。gan模型的输入是随机噪声和标签,网络模型没有学习文字的语义结构信息,不能根据文字的语义信息进行图像生成,只能根据标签的信息进行定向图像生成。基于u-net网络的模型可以学习文字的语义结构信息,但u-net网络中每层编码器都向对应的解码器传递局部结构信息,导致u-net网络作为文字修复网络的生成器时稳定性低,不易训练。
技术实现要素:
8.针对现有技术的不足,本发明提供一种基于自编码网络的碑文文字修复模型及修复方法。
9.本发明采用以下技术方案:
10.一种基于自编码网络的碑文文字修复模型,采用上下文编码器,包括生成器和判别器,其中生成器采用变分自编码器,包括一个编码器和解码器;
11.生成器包括卷积层c1层、4层扩张卷积c2~c5层,卷积层c6~c9层、4层反卷积dc1~dc4层以及卷积层c10层,判别器包括4层卷积层c11~c14层和一层全连接层;
12.每一个卷积模块都有激活函数层,c2~c5层采用relu激活函数,c1层、c6~c9层和dc1~dc4层均采用elu激活函数,c10层采用tanh激活函数。
13.本发明采用上下文编码器,结合gan网络后稳定性高,易于训练,并且变分自编码器也可以学习碑文文字的语义结构信息。
14.此外,本发明在变分自编码网络前面加入4层扩张卷积,可以更准确的学习到破损碑文文字的语义特征信息。将除扩张卷积外的leakyrelu和relu激活函数替换为elu激活函数,可以增加模型的鲁棒性。
15.本发明生成器的详细参数如表1所示,生成器的输入是遮挡的碑文文字,输出是重建的碑文文字。判别器的参数如表2所示;
16.表1:生成器参数
[0017][0018]
表2:判别器参数
[0019][0020][0021]
优选的,生成器的编码器负责学习遮挡碑文文字的结构语义特征,加上编码器前面的四层扩张卷积,编码器能学习到更准确的语义特征;编码器将学习到碑文文字的语义特征传递给生成器的解码器,解码器根据学习到的语义特征反卷积进行碑文文字的重建;将修复好的碑文文字和对应的原碑文文字输入到判别器,输出该文字为原碑文文字的概率;
[0022]
前向传播完成后(前向传播就是数据集从模型输入到输出的过程。神经网络模型是一个非常复杂的嵌套函数f(x),数据集是x,将x根据函数映射到x’就是前向传播。反向传播就是根据模型输出的数据和原数据的差别优化模型,其实就是一个求导的过程。相当于根据x和x’的差别,调整f(x)的参数),通过均方差损失函数和交叉熵损失函数分别计算重
建损失和对抗损失;将模型的梯度清零(梯度是一个向量,用来指明在函数的某一点,沿着哪个方向函数值上升最快,这个向量的模指明函数值上升程度(速度)的大小),反向传播,根据重建损失和对抗损失的联合损失使用adam优化器优化模型的生成器和判别器;
[0023]
模型的生成器和判别器不断优化,最后达到一种平衡,生成器生成出的碑文文字能骗过判别器的识别(在gan网络中,生成器的图像生成能力和判别器的图像识别能力会达到一种纳什均衡,生成器生成出的碑文文字能骗过判别器是指判别器不能识别出一个文字是原文字还是生成器生成的),判别器能识别出生成器生成的碑文文字和原碑文文字。
[0024]
优选的,模型的重建损失如下式所示:
[0025][0026]
其中,x是指原文字图像,m是掩码函数,将64*64大小的原图输入到掩码函数中,得到一张随机位置遮挡25%面积的遮挡图;g是模型的生成器,将遮挡图输入到生成器中,重建输出碑文文字;
[0027]
模型的对抗损失如下式所示:
[0028][0029]
其中,d是判别器,判别输入的碑文文字是原碑文文字还是生成器重建的碑文文字;该损失函数的思想来自于gans,加入该损失函数可以使重建的碑文文字看起来更真实一些;
[0030]
联合损失函数是加权重建损失和对抗损失,如下所示:
[0031]
l
loss
(x)=(1-λ)l
rec
+λl
adv
[0032]
其中,l
rec
是重建损失,l
adv
是对抗损失,λ是总的损失函数的权重。
[0033]
优选的,λ=0.001。
[0034]
优选的,数据集是神经网络中至关重要的一部分,本发明以柳公权的《玄秘塔碑》和《金钢经》中的碑文文字作为模型的训练集和测试集,其中模型训练集有4000张碑文文字图像。
[0035]
由于人为因素或自然因素,大量现存碑文文字损毁严重,表面模糊不清,文字难以识别,导致传统的数字化技术难以得到较好的视觉效果。
[0036]
数据集的预处理过程如图1所示,对预处理完的图像进行遮挡处理,模拟实际破坏的碑文文字,碑文文字在随机位置遮挡25%面积的矩形方块。然后图像的标准化,将像素值压缩到-1~1之间,然后按批次输入模型。
[0037]
在模型训练时,将遮挡的碑文文字分批输入到生成器中,输出完整的碑文文字,然后把生成的碑文文字和对应的原碑文文字输入到判别器判别,不断循环训练,优化生成器和判别器。判别器的作用是辅助生成器的训练,使生成器生成出的碑文文字更真实。
[0038]
生成器的编码器负责学习遮挡碑文文字的结构语义特征,加上编码器前面的四层扩张卷积,编码器能学习到更准确的语义特征(扩张卷积是在标准卷积的基础上增加了卷积核的坑洞,这样可以增加卷积核的感受野,卷积核的感受野大了就可以学习到更多的语义特征,相对学习到的语义特征更加准确。
[0039]
编码器将学习到碑文文字的语义特征传递给生成器的解码器,解码器根据学习到的语义特征反卷积进行碑文文字的重建。
[0040]
本发明的训练集有4000张图像,批大小为32,共训练300轮,每轮循环125次。每轮训练都将4000张碑文文字图像训练一遍。
[0041]
模型训练完后,保存模型生成器的所有权重参数,以便后面测试。本发明用到的实验性神经网络框架为tensorflow,训练模型的显卡是nvidia的gtx2080ti,操作系统为win11家庭版。
[0042]
模型权重参数保存后,测试模型的碑文文字修复效果。模型输出重建碑文文字后,对其进行像素向上取整纠错。
[0043]
本发明用到的数据集是单通道二值图像,只有0和255两个像素值,这是根据碑文文字的特点做地预处理。相比一般的图像,碑文文字没有丰富的色彩信息,但有更复杂的结构信息。因此两个像素值完全可以表示碑文文字,碑文文字的修复更要注重碑文文字的结构信息。
[0044]
输入到模型中的碑文文字只有两个像素值,如果模型重建输出的碑文文字是正确的,那么也只有两个像素值。模型输出碑文文字的像素值即使是正确的,也会略有偏差,要么接近-1,要么接近1。
[0045]
对输出的像素值进行向上取整,接近-1的像素值就能取到-1,接近1的像素值取到1,这样会大大减小碑文文字总体上的像素值损失。
[0046]
一种基于自编码网络的碑文文字修复模型的修复方法,包括以下步骤:
[0047]
(1)碑文数据集收集;
[0048]
(2)将收集的碑文数据集借用opencv工具包进行数据预处理,首先对截取出的碑文文字做去噪处理,调用opencv的去噪函数和高斯滤波器去噪;然后阈值处理,将碑文文字处理成单通道二值图像;最后重置碑文文字的大小,重置成模型输入的大小64x64x1;
[0049]
(3)将预处理后的图像进行标准化,并分配训练集和测试集;
[0050]
(4)将训练集输入碑文文字修复模型,对模型进行训练、测试,得到训练后的碑文文字修复模型;
[0051]
(5)将预处理后的待修复的碑文文字输入已训练好的碑文文字修复模型,遮挡碑文文字输入到生成器,经过编码器的学习和解码器的重建,模型的生成器输出修复好的碑文文字;
[0052]
(6)在模型输出重建后的碑文文字后对其进行像素向上取整纠错。
[0053]
优选的,神经网络用到的数据集图像大多是8位图,图像像素值的范围是0-255,标准化是将像素值的范围从0-255压缩到-1~1之间,修复完后再扩大到0-255,单通道二值图为一个二阶矩阵,即将像素值压缩到-1~1之间。
[0054]
首先,本发明借用opencv工具包对数据集进行了预处理,得到了比较好的视觉效果。其次,本发明对上下文编码器了改进,加入的扩张卷积能让编码器学习到更准确的语义特征,碑文文字没有色彩,有的只是结构和轮廓;其次用elu激活函数替换leakyrelu/relu激活函数,增加了模型的鲁棒性;最后对模型输出的碑文文字进行像素值向上取整,可以大大减少像素值的损失。
[0055]
本发明未详尽之处,均可采用现有技术。
[0056]
本发明的有益效果为:
[0057]
本发明改进模型的重建输出为整个碑文文字,不仅仅是缺失部分,可以修复任意
位置、任意大小补丁的碑文文字。输入为整张遮挡碑文文字,输出整张碑文文字,模型的输入和输出是对称的,语义信息也是对称的,输出相对更准确。
[0058]
本发明用到的数据集是单通道二值图像,不仅降低了碑文文字修复的难度,也节省了模型优化时的计算资源。碑文文字就只有黑色石碑和文字,处理成二值图像有更好地视觉效果。模型的输入是二值图像,可以将模型扩展到二值图像修复。
[0059]
本发明选择的基础模型是变分自编码器,变分自编码器的编码器不向解码器传递局部特征,降低了模型的复杂度。变分自编码器结合gan网络使修复模型更稳定(对抗损失即结合gan的体现,变分自编码器自身只有重建损失,而结合gan网络后,上下文编码器有一个生成器,还有一个判别器,有重建损失,也有对抗损失),模型易于训练,比较容找到模型的最优解。
附图说明
[0060]
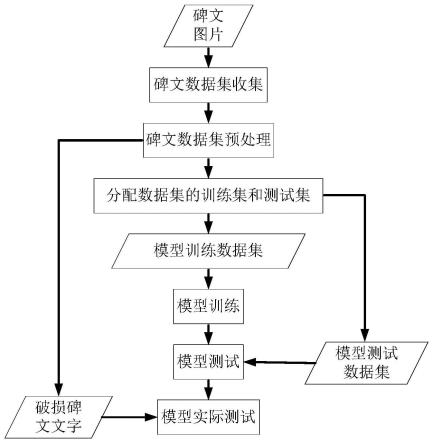
图1为数据预处理的过程示意图;本发明截取出柳公权的《玄秘塔碑》和《金钢经》中的碑文文字组成数据集。该过程主要借助opencv函数库对数据集进行预处理;
[0061]
图2为预处理提取出的部分碑文文字,即经过预处理组成模型的训练;
[0062]
图3为本发明的修复模型简图,由一个生成器和判别器组成,其中生成器是一个变分自编码器,有一个编码器和解码器;
[0063]
图4为模型训练完所有参数已不再变化,在测试集上对中心区域遮挡25%面积的碑文文字进行修复;其中,第1、4、7行是原碑文文字,第2、5、8行是中心区域遮挡25%面积的碑文文字,第3、6、9行是模型修复的碑文文字;
[0064]
图5为模型进行实际碑文修复测试结果,其中遮挡区域是根据碑文文字的缺失部分遮挡的,遮挡区域要和缺失区域匹配;
[0065]
图6为卷积示意图,其中(a)为标准卷积,(b)为扩张率为2的扩张卷积;
[0066]
图7为基于自编码网络的碑文文字修复模型的修复方法示意图。
具体实施方式:
[0067]
为使本发明要解决的技术问题、技术方案和优点更加清楚,下面将结合附图及具体实施例进行详细描述,但不仅限于此,本发明未详尽说明的,均按本领域常规技术。
[0068]
实施例1
[0069]
一种基于自编码网络的碑文文字修复模型,如图3所示,采用上下文编码器,包括生成器和判别器,其中生成器采用变分自编码器,包括一个编码器和解码器;
[0070]
生成器包括卷积层c1层、4层扩张卷积c2~c5层,卷积层c6~c9层、4层反卷积dc1~dc4层以及卷积层c10层,判别器包括4层卷积层c11~c14层和一层全连接层;
[0071]
每一个卷积模块都有激活函数层,c2~c5层采用relu激活函数,c1层、c6~c9层和dc1~dc4层均采用elu激活函数,c10层采用tanh激活函数。
[0072]
本发明采用上下文编码器,结合gan网络后稳定性高,易于训练,并且变分自编码器也可以学习碑文文字的语义结构信息。
[0073]
此外,本发明在变分自编码网络前面加入4层扩张卷积,可以更准确的学习到破损碑文文字的语义特征信息。将除扩张卷积外的leakyrelu和relu激活函数替换为elu激活函
数,可以增加模型的鲁棒性,总的模型简图如图3所示。
[0074]
本发明生成器的详细参数如表1所示,生成器的输入是遮挡的碑文文字,输出是重建的碑文文字。判别器的参数如表2所示;
[0075]
表1:生成器参数
[0076][0077]
表2:判别器参数
[0078][0079][0080]
实施例2
[0081]
一种基于自编码网络的碑文文字修复模型,如实施例1所述,所不同的是,生成器的编码器负责学习遮挡碑文文字的结构语义特征,加上编码器前面的四层扩张卷积,编码器能学习到更准确的语义特征;编码器将学习到碑文文字的语义特征传递给生成器的解码器,解码器根据学习到的语义特征反卷积进行碑文文字的重建;将修复好的碑文文字和对应的原碑文文字输入到判别器,输出该文字为原碑文文字的概率;
[0082]
前向传播完成后(前向传播就是数据集从模型输入到输出的过程。神经网络模型是一个非常复杂的嵌套函数f(x),数据集是x,将x根据函数映射到x’就是前向传播。反向传播就是根据模型输出的数据和原数据的差别优化模型,其实就是一个求导的过程。相当于根据x和x’的差别,调整f(x)的参数),通过均方差损失函数和交叉熵损失函数分别计算重建损失和对抗损失;将模型的梯度清零(梯度是一个向量,用来指明在函数的某一点,沿着哪个方向函数值上升最快,这个向量的模指明函数值上升程度(速度)的大小),反向传播,根据重建损失和对抗损失的联合损失使用adam优化器优化模型的生成器和判别器;
[0083]
模型的生成器和判别器不断优化,最后达到一种平衡,生成器生成出的碑文文字能骗过判别器的识别(在gan网络中,生成器的图像生成能力和判别器的图像识别能力会达到一种纳什均衡,生成器生成出的碑文文字能骗过判别器是指判别器不能识别出一个文字是原文字还是生成器生成的),判别器能识别出生成器生成的碑文文字和原碑文文字。
[0084]
模型的重建损失如下式所示:
[0085][0086]
其中,x是指原文字图像,m是掩码函数,将64*64大小的原图输入到掩码函数中,得到一张随机位置遮挡25%面积的遮挡图;g是模型的生成器,将遮挡图输入到生成器中,重建输出碑文文字;
[0087]
模型的对抗损失如下式所示:
[0088][0089]
其中,d是判别器,判别输入的碑文文字是原碑文文字还是生成器重建的碑文文字;该损失函数的思想来自于gans,加入该损失函数可以使重建的碑文文字看起来更真实一些;
[0090]
联合损失函数是加权重建损失和对抗损失,如下所示:
[0091]
l
loss
(x)=(1-λ)l
rec
+λl
adv
[0092]
其中,l
rec
是重建损失,l
adv
是对抗损失,λ是总的损失函数的权重,本实施例中λ=0.001。
[0093]
数据集是神经网络中至关重要的一部分,本发明以柳公权的《玄秘塔碑》和《金钢经》中的碑文文字作为模型的训练集和测试集,其中模型训练集有4000张碑文文字图像。
[0094]
由于人为因素或自然因素,大量现存碑文文字损毁严重,表面模糊不清,文字难以识别,导致传统的数字化技术难以得到较好的视觉效果。
[0095]
数据集的预处理过程如图1所示,对预处理完的图像进行遮挡处理,模拟实际破坏的碑文文字,碑文文字在随机位置遮挡25%面积的矩形方块。然后图像的标准化,将像素值压缩到-1~1之间,然后按批次输入模型。
[0096]
图3的上半部分是模型的生成器,是一个变分自编码网络,图3的每个箭头代表一步卷积操作,对应表1中的每一行,每一行对应每一步操作的参数。
[0097]
图3下半部分是模型的生成器,前4层是标准卷积,最后一层是全连接层。表2的每一行应判别器的每一步卷积操作。训练模型时,默认生成的碑文文字的标签为0,原碑文文字的标签为1,判别器不断提取碑文文字的特征,然后将提取到的特征打平成一维向量,经过一个全连接层将一维向量全连接到一个数,如果这个数接近0,就认为这个碑文文字是生成的,相反就认为这个文字是原碑文文字。
[0098]
在模型训练时,将遮挡的碑文文字分批输入到生成器中,输出完整的碑文文字,然后把生成的碑文文字和对应的原碑文文字输入到判别器判别,不断循环训练,优化生成器和判别器。判别器的作用是辅助生成器的训练,使生成器生成出的碑文文字更真实。
[0099]
生成器的编码器负责学习遮挡碑文文字的结构语义特征,加上编码器前面的四层扩张卷积,编码器能学习到更准确的语义特征(扩张卷积是在标准卷积的基础上增加了卷积核的坑洞,这样可以增加卷积核的感受野,卷积核的感受野大了就可以学习到更多的语
义特征,相对学习到的语义特征更加准确。图6(a)展示了标准卷积,图6(b)展示了扩张率为2的扩张卷积。
[0100]
编码器将学习到碑文文字的语义特征传递给生成器的解码器,解码器根据学习到的语义特征反卷积进行碑文文字的重建。
[0101]
本发明的训练集有4000张图像,批大小为32,共训练300轮,每轮循环125次。每轮训练都将4000张碑文文字图像训练一遍。
[0102]
模型训练完后,保存模型生成器的所有权重参数,以便后面测试。本发明用到的实验性神经网络框架为tensorflow,训练模型的显卡是nvidia的gtx2080ti,操作系统为win11家庭版。
[0103]
模型权重参数保存后,测试模型的碑文文字修复效果。模型输出重建碑文文字后,对其进行像素向上取整纠错。
[0104]
本发明用到的数据集是单通道二值图像,只有0和255两个像素值,这是根据碑文文字的特点做地预处理。相比一般的图像,碑文文字没有丰富的色彩信息,但有更复杂的结构信息。因此两个像素值完全可以表示碑文文字,碑文文字的修复更要注重碑文文字的结构信息。
[0105]
输入到模型中的碑文文字只有两个像素值,如果模型重建输出的碑文文字是正确的,那么也只有两个像素值。模型输出碑文文字的像素值即使是正确的,也会略有偏差,要么接近-1,要么接近1。
[0106]
对输出的像素值进行向上取整,接近-1的像素值就能取到-1,接近1的像素值取到1,这样会大大减小碑文文字总体上的像素值损失。
[0107]
实施例3
[0108]
一种基于自编码网络的碑文文字修复模型的修复方法,如图7所示,包括以下步骤:
[0109]
(1)碑文数据集收集;
[0110]
(2)将收集的碑文数据集借用opencv工具包进行数据预处理,首先对截取出的碑文文字做去噪处理,调用opencv的去噪函数和高斯滤波器去噪;然后阈值处理,将碑文文字处理成单通道二值图像;最后重置碑文文字的大小,重置成模型输入的大小64x64x1;
[0111]
(3)将预处理后的图像进行标准化,并分配训练集和测试集;
[0112]
(4)将训练集输入碑文文字修复模型,对模型进行训练、测试,得到训练后的碑文文字修复模型;
[0113]
(5)将预处理后的待修复的碑文文字输入已训练好的碑文文字修复模型,遮挡碑文文字输入到生成器,经过编码器的学习和解码器的重建,模型的生成器输出修复好的碑文文字;
[0114]
(6)在模型输出重建后的碑文文字后对其进行像素向上取整纠错。
[0115]
本实施例中神经网络用到的数据集图像大多是8位图,图像像素值的范围是0-255,标准化是将像素值的范围从0-255压缩到-1~1之间,修复完后再扩大到0-255,单通道二值图为一个二阶矩阵,即将像素值压缩到-1~1之间。
[0116]
首先,本发明借用opencv工具包对数据集进行了预处理,得到了比较好的视觉效果。其次,本发明对上下文编码器了改进,加入的扩张卷积能让编码器学习到更准确的语义
特征,碑文文字没有色彩,有的只是结构和轮廓;其次用elu激活函数替换leakyrelu/relu激活函数,增加了模型的鲁棒性;最后对模型输出的碑文文字进行像素值向上取整,可以大大减少像素值的损失。
[0117]
加载训练好的模型对测试集碑文文字进行测试,所有碑文文字中心遮挡25%面积,经过预处理输入模型,输出重建的碑文文字。如图4所示,模型可以修复出缺失的碑文文字部分,并且重建的碑文文字的像素值是连续的,没有偏移。碑文文字不仅有结构还有轮廓,模型重建的碑文文字结构大部分是正确的,模型没有输出不存在的碑文文字。
[0118]
然后对模型进行实际测试,破损的碑文文字也来自《玄秘塔碑》和《金刚经》。针对破损的碑文文字进行遮挡处理,可以根据缺失区域遮挡任意位置、任意大小。如图5所示,模型可以重建碑文文字缺失的笔画。模型对遮挡区域非常敏感,一定要将破损区域遮挡住。值得注意的是,遮挡破损碑文文字的不同区域,修复的结果不同,模型会默认认为未遮挡区域是完整的。
[0119]
以上所述是本发明的选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明所述原理的前提下,还可以作出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1