一种基于向量处理器的QR分解后的矩阵向量乘法实现方法
一种基于向量处理器的qr分解后的矩阵向量乘法实现方法
技术领域
1.本发明涉及高性能数字信号处理器(digital signal processor,dsp)芯片代码优化,更加具体的,涉及一种基于向量处理器的qr分解后的矩阵乘法实现方法。
背景技术:
2.vsip库是ge智能平台推出的向量、信号和图像处理库,是专为需要使用强化型信号和图像处理的开发人员而提供的开放标准应用程序编程接口,若直接调用vsip库中的原函数,则丧失了向量处理器优秀的硬件性能,想要发挥出高性能处理器的硬件优势,提高算法的并行性与效率,将vsip库中的算法优化后适配不同的高性能处理器,是一种不错的选择。
3.在现代处理器中,拥有向量处理单元的vliw体系结构日渐成为了高性能数字信号处理器的典型结构,国产高性能dsp发展迅速,出现了许多由不同公司生产的高性能处理器,这些处理器通常具有寄存器资源丰富,执行单元多的特点。向量处理器一般由多个处理单元组成,支持基于向量的数据加载、运算和存储。每个处理单元包含多个独立的多功能部件,一般包括加法部件、乘法部件、移位部件、比较部件、向量元素累加器、标量向量转换部件。向量处理器一般都支持单指令多数据流simd操作,即在同一条向量指令的控制下,所有的处理单元同时对相应的局部寄存器进行相同的操作,实现开发应用程序的数据级并行性。为了加快数据访存速度,向量处理器的内部或外部通常有高速缓存:cache,为有效的发挥dsp向量处理硬件性能优势,亟待出现适配的高效矩阵乘法优化算法。矩阵乘法作为许多科学应用中被频繁使用的关键部分,其具有计算量巨大且稠密的本质,使得高性能计算领域中矩阵、向量乘法并行算法的研究一直是经久不衰的话题。此外,矩阵乘法常被用于评估新型处理器架构的性能和效率,以及探究如何在新的体系结构上进行高性能优化。
4.申请公布号cn 103294648a,申请公布日2013年9月11日的发明专利申请公开了一种支持多mac运算部件向量处理器的分块矩阵乘法向量化方法。该方法将被乘子矩阵a的每一行的每一个元素扩展成一个向量数据和矩阵b的一行数据进行累加乘,该方案和本方案实现方法不相同,该方案也没有实现qr分解后矩阵向量乘法。
5.申请公布号cn 114090954a,申请公布日2022年2月25日的发明专利申请公开了一种基于ft-2000+的整数矩阵乘法内核优化方法。该方法据输入和输出矩阵数据长度的不同,对子函数的设计内容加以区分,结合飞腾2000+体系结构,确定寄存器分配策略和矩阵分块策略,实现对整数矩阵乘法的优化,该方案和本方案实现方法不相同,该方案也没有实现qr分解后矩阵向量乘法。
6.本发明涉及一种基于向量处理器的qr分解后的矩阵乘法实现方法,所针对的qr分解算法为vsip库函数中的vsip_cqrd_f函数,在调用完cqrd函数后,取出该函数的输出qrd结构体,该结构体中主要包括了复数矩阵a,复数向量ci和实数向量beta。复数矩阵a中上三角的部分为r矩阵,下三角的部分为q矩阵,将上述数据作为该算法的输入,实现了与qr分解中的q矩阵在四种不同情况的矩阵向量乘法运算。
技术实现要素:
7.本发明为了解决上述技术问题,提出一种基于向量处理器的qr分解后的矩阵乘法实现方法。
8.本发明的技术方案为:包括以下步骤,步骤1,判断输入矩阵c是否需要转置共轭以及矩阵c在矩阵乘法的左边还是右边,以便进入不同的子函数处理。各子函数处理方式大同小异,本方案主要叙述共同的处理方法。
9.步骤2,对a矩阵进行预处理,将a矩阵对角线上元素置1,对角线右上部分元素置0,对角线左下部分元素不变。变换后,将a矩阵按列分块,按次序把每一列分别命名为向量、,例如:向量包含矩阵a第1列的值,各分量的值命名为 、 。
10.步骤3,矩阵 c与向量 做矩阵乘法运算,通过dma传输将整个c矩阵以及向量 传输到cache中,向量 与矩阵c每一行各取p个数传入向量运算部件中,同时执行乘法指令,将乘法结果传入临时向量寄存器tr;再取第p+1~2p个数据,进行同样计算,并和tr已保存对应的值累加;直至算完矩阵c的一行,将tr的值传入向量元素累加器vea中,vea进行累加操作,并乘以beta后存入ddr指定空间内;接着进行第二行计算,直至所有行计算完成,得到一个存储在ddr内长度为m的向量 。
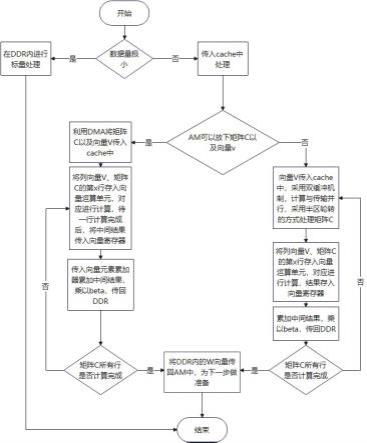
11.本发明上述步骤3的具体方式包括如下步骤,步骤3.1,根据原始数据大小判断如何处理,当原始数据极小时,进入步骤3.2,当原始数据大小未超过cache尺寸时,进入步骤3.3,当原始数据大小超过cache尺寸时,进入步骤3.4;步骤3.2,当数据量极小时,将直接在ddr内通过标量处理;步骤3.3,当数据量未超过cache尺寸时,通过dma传输将整个c矩阵以及向量传输到cache中,向量与矩阵c每一行各取p个数传入向量运算部件中,同时执行乘法指令,将乘法结果传入临时向量寄存器tr;再取第p+1~2p个数据,进行同样计算,并和tr已保存对应的值累加;直至算完矩阵c的一行,将tr的值传入向量元素累加器vea中,vea进行累加操作,并乘以beta后存入ddr指定空间内;接着进行第二行计算,直至所有行计算完成,得到一个存储在ddr内长度为m的向量;步骤3.4,当数据量超过cache尺寸时,将cache分为三个部分,第一部分用来存储向量,剩下的空间均分为上下半区,通过dma传输按行将矩阵c的内容传入上半区,待传输数据完毕,继续向下半区传输矩阵c的剩余行,上半区开始计算,计算过程如步骤3.3,传输与计算并行,待上半区的计算与下半区的传输完成后,再向上半区继续传输矩阵c剩余内容,同时开始下半区的计算,重复以上步骤,直至所有运算完成。
12.与现有技术相比,本发明的有益效果是:本发明根据向量处理器的硬件特点,移植并优化了vsip库中qr分解后的矩阵乘法,充分利用硬件性能优势,提高计算单元的利用效率,达到更高的指令并行性。
附图说明
13.图1为本发明的步骤2对矩阵a预处理示意图。
14.图2为本发明的步骤3中矩阵c与向量做矩阵乘法运算以及更新向量公式示意图。
15.图3为本发明的步骤3运行流程图。
16.图4为本发明的步骤3计算过程示意图。
具体实施方式
17.现结合附图说明与实施例对本发明进一步说明。
18.参考表1,本发明考虑的矩阵运算情况示意图,表示转置求共轭后的q矩阵。以矩阵乘法运算为例,左侧矩阵为q,右侧矩阵为c,若左侧矩阵q规模为m*m,右侧矩阵为m*k,则输出矩阵规模为m*k,按情况决定是否对输入矩阵c进行转置求共轭操作。处理完成后,a矩阵内存有q矩阵的部分内容,对a矩阵进行处理,将a矩阵对角线上元素置1,对角线右上部分元素置0,对角线左下部分元素不变,如图1所示。变换后,将a矩阵按列分块,按次序把每一列分别命名为向量、 ,例如:向量包含矩阵a第1列的值,各分量的值命名为、。
19.参考图2、图3,将a矩阵按列分块后,先根据原始数据大小判断如何处理,当原始数据极小时,将直接在ddr内进行标量处理,当原始数据大小未超过cache尺寸时,通过dma传输将整个c矩阵以及向量 传输到cache中,按行处理矩阵c,具体计算过程可参考下一段说明,直至所有计算完成,得到一个存储在ddr内长度为m的向量。当原始数据大小超过cache尺寸时,将cache分为三个部分,第一部分用来存储向量,剩下的空间均分为上下半区,通过dma传输按行将矩阵c的内容传入上半区,待传输数据完毕,继续向下半区去传输矩阵c的剩余行,上半区开始计算,传输与计算并行,待上半区的计算与下半区的传输完成后,将计算完成的部分通过dma传输传回ddr中,传回结束后,再向上半区继续传输矩阵c剩余内容,同时开始下半区的计算,重复以上步骤,直至所有运算完成。
20.参考图4,本发明的步骤3计算过程示意图。设向量 ={ },矩阵c={},{},{},设向量运算部件有4个处理单元,可以同时处理4个数据,即p=4。第一行计算时,第一次,从cache中传输{ }和{}这些数据到向量运算部件,执行向量乘法运算,=,=,=,= ,将、、、传入向量寄存器tr,然后开始第二次运算,将、 传输到向量运算部件中,执行乘法运算,= ,将传入向量寄存器tr中,并和 相加,将{,,,}存入向量元素累加器vea,累加后乘以并传回ddr,第二行计算类似。
21.综上所述,本领域的普通技术人员阅读本发明文件后,根据本发明的技术方案和
技术构思无需创造性脑力劳动而做出其他各种相应的变换方案,均属于本发明所保护的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1