一种基于弱监督学习的云服务器配置异常识别方法与流程
本发明涉及数据处理领域,具体涉及一种基于弱监督学习的云服务器配置异常识别方法。
背景技术:
1、云计算平台也称为云平台,是指基于算力资源的服务,提供计算、网络和存储能力。算力资源可以分为硬件资源和软件资源,其中的硬件资源有服务器、存储器和cpu等,软件资源包括应用软件和集成开发环境等。用户只需要通过网络发送请求就可以从云端获取满足需求的资源到本地的计算机,所有的计算任务都是在远程的云数据中心完成。云计算平台与人们熟知的电商平台在组成上十分相似,都拥有用户、提供商、商品三大要素。在云计算平台中,用户是算力资源的使用者,其人群主要由科研人员(教师、学生等)、企业中的技术人员(软件开发、数据库管理者),以及部分有需求的大众组成,通常具备一定的计算机软硬件知识。云计算平台的提供商是算力资源的实际拥有者,往往是拥有算力基础设施的大型互联网公司。云计算平台的商品含云、网、边、端四大类,其中以云这一类别中的云服务器为主。云服务器通常分为通用云服务器和gpu云服务器,随着人工智能的发展,为了满足日益增长的神经网络训练的需求,gpu云服务器成为不可或缺的热门商品。
2、将合适的商品推荐给用户可以提升用户体验,是推荐系统最重要的目标。推荐系统本质上一种信息过滤系统,通过一定的算法在数据中过滤掉用户不太可能产生行为的物品,从而为用户推荐所需要的物品。推荐系统在日常生活中应用十分广泛,小到商场的捆绑销售,大到电商、新闻网站,无时不刻不在影响和改变着人们都生活方式。传统的推荐系统是基于用户的行为,通过协同过滤算法,计算商品与商品之间或是用户与用户之间的相似度,然后进行推荐。目前市场上最常见的电商平台推荐系统是以多路召回架构为基石,通过嵌入学习和知识图谱等人工智能相关的手段,提供个性化、智能化的推荐方案。然而云计算平台在用户行为、商品类型等各方面都与传统推荐系统所适用的电商平台存在一定差异,因此不能完全参考电商平台的推荐系统。计算平台用户通常购买的商品类型较少,且会较为长期的使用,像电商平台那样频繁地推荐琳琅满目的不同类型的商品并不合适。此外,云计算平台有一个很为关键的场景,即部分商品需要用户自定义相关的配置,例如购买云服务器的用户需要对磁盘容量、cpu、内存、gpu等做出选择。因此,在构建云计算平台推荐系统时需要结合平台自身的真实数据,致力于发觉各类应用场景并通过场景创新的方式将人工智能相关技术更好地落实在应用层面,从而全方位提高用户体验、给云计算平台赋能。
3、在上述的服务器配置选择场景中,由于用户的专业背景不同,有些用户并不知道自己的选择是否合理。例如用户在购买gpu云服务器时选择了32gb的内存,但是磁盘容量却只选择了30gb。由于选择多核高内存gpu服务器的用户大多是为了训练机器学习模型,因此若是将这样的配置直接投入使用,很快便会出现磁盘空间不足引起的各种错误。
4、异常检测的传统方法有以下两种:
5、1)基于规则的方式:根据用户可选择的配置,手动定义各类异常状况的触发条件。例如手动定义所选的内存容量与磁盘空间异常时的规则。
6、2)基于统计学的方式:利用统计学的指标,通过某个连续变量衡量当前用户所选的配置和绝大多数用户相比是否属于异常的。例如,统计中使用iqr方法(interquartilerange,四分距离)或是正态分布对某一连续变量的值进行异常识别。
7、但这两种方法,均有一定的局限性,第一种方法有太多的主观因素,性能不稳定,且费时费力,第二种方法,模型过于粗糙,适用性不强。
技术实现思路
1、本发明的目的是解决用户云在计算平台上选择服务器这一场景下的配置搭配相关的推荐问题,提出了一种基于弱监督学习的配置搭配异常识别方案。
2、一种基于弱监督学习的云服务器配置异常识别方法,包括以下步骤:
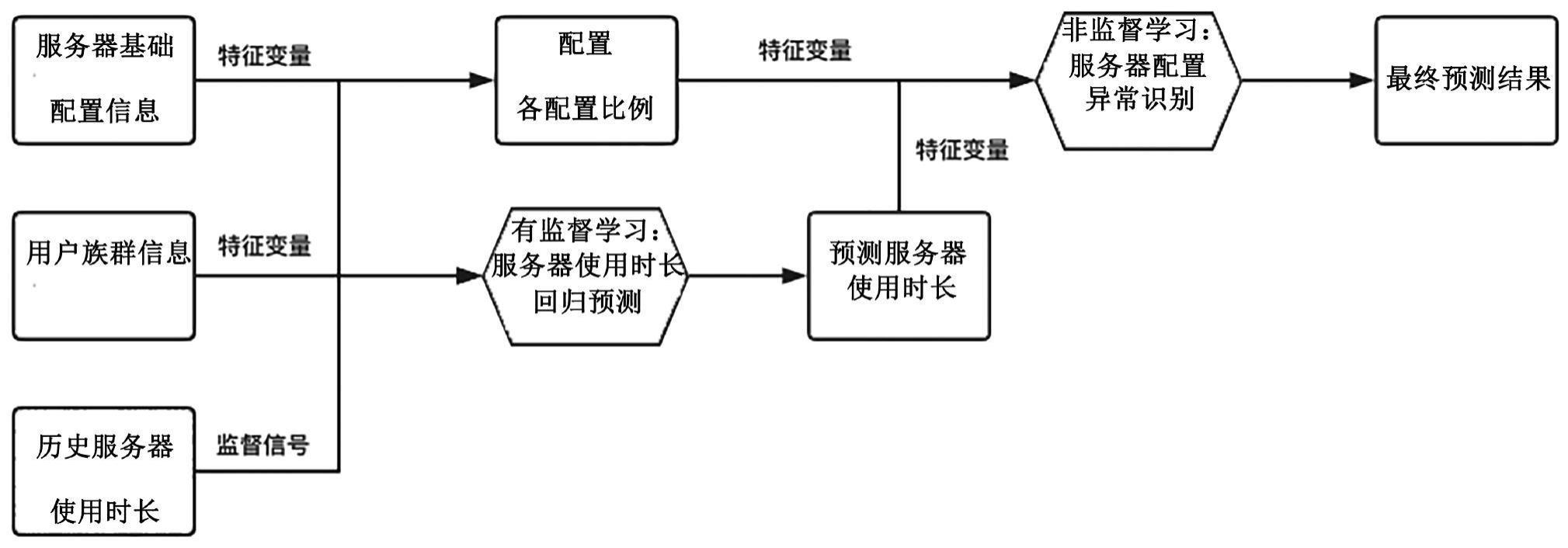
3、s1:从历史数据中,读取服务器基础配置信息,所述服务器基础配置信息包括离散变量与非离散变量,读取历史服务器使用时长;
4、s2:将服务器基础配置信息作为catboost回归模型的特征变量,将历史服务器使用时长作为catboost回归模型的监督信息,得到服务器使用时长的预测模型,用于计算预期服务器使用时长;
5、s3:将服务器基础配置信息中的非离散变量、使用服务器使用时长的预测模型得到的预期服务器使用时长作为孤立森林模型的特征变量,得到异常识别模型;
6、s4:将待测试的数据中服务器基础配置信息输入到服务器使用时长的预测模型,并将得到的预期服务器使用时长作为异常识别模型的输入,同时将服务器基础配置信息中的非离散变量作为异常识别模型的输入,即可得到被识别为异常的服务器。
7、进一步的,
8、s1中还包括从历史数据中,读取用户族群信息;
9、s2中还包括将用户族群信息作为catboost回归模型的特征变量;
10、s4中还包括将待测试的数据中用户族群信息输入到服务器使用时长的预测模型。
11、进一步的,
12、s3中服务器基础配置信息中的非离散变量,变量间相关度低于相关度阈值的变量独立作为孤立森林模型的特征变量,变量间相关度高于相关度阈值的变量取互相之间的比例,作为孤立森林模型的特征变量。
13、进一步的,对所述比例进行对数转化处理后,再作为孤立森林模型的特征变量。
14、进一步的,所述相关度阈值为皮尔森相关系数0.25。
15、进一步的,所述孤立森林模型生成的异常识别模型,在其异常识别步骤增加一个条件,需同时满足预期服务器使用时长低于服务器使用时长阈值时,才能判定为异常。
16、进一步的,所述服务器使用时长阈值为168小时。
17、进一步的,所述服务器基础配置信息的离散变量为系统、架构,所述所述服务器基础配置信息的非离散变量为cpu核数、内存容量、硬盘容量、网络带宽。
18、进一步的,所述s2中catboost回归模型使用的超参数包括:迭代次数:1000,决策树结构:对称,l2正则化强度:3,决策树最大深度:6,学习率:0.0496,最大叶子数量:64。
19、进一步的,所述s3中孤立森林模型的超参数包括:是否使用bootstrap:是的,污染度:0.01,最大特征数:1.0,决策树数量:1000。
20、有益效果:
21、关键点1,使用服务器使用时长作为弱监督信号。技术效果:从某种意义上说给用户推荐其能够最长期使用的商品可以被视为一种合理的推荐,因为使用时长往往与用户满意程度成正相关。往往用户发现配置不合适后会注销原服务器并重新创建新服务器,因此服务器使用时长与配置合理性存在一定的关联。但是由于部分被长时间投入使用的服务器也存在配置搭配不合理的情况,因此服务器使用时长只能作为弱监督学习中不确切监督的粗粒度信号,对服务器配置搭配的合理性进行一定程度的量化,但是不能作为服务器配置是否合理的唯一判定标准。由于用户在创建新服务器选择配置时尚未使用该服务器,因此需要基于已有的配置信息和用户自身信息对该用户使用服务器的时长做出预测。该方案中弱监督学习在具体实施时可以被拆分为有监督机器学习和无监督机器学习两个步骤(由关键点2和关键点3中阐述)。
22、关键点2,基于有监督学习模型catboost,通过服务器配置和用户族群信息对服务器的使用时长进行回归预测。技术效果:用户在使用的过程中若是发现所选的云服务器配置不合适,往往会删除已有的服务器并重新选择新的服务器,因此配置搭配不合理的服务器往往总使用时长要小于长期投入使用的配置搭配合理的服务器。因此,服务器的使用时长可以提供与配置搭配合理性相关的监督信号。本方法利用了catboost模型对离散变量的特殊处理机制,综合考虑了服务器使用时长相对于用户族群、操作系统等离散变量的不同分布情况。
23、关键点3,基于非监督学习模型isolation forest(孤立森林),通过服务器配置间的比例关系和基于有监督学习模型预测出的服务器使用时长,进行异常识别。技术效果:使用配置间的比例代替独立的配置信息,可以避免高配置的服务器由于数量稀少被判定为不合理的情况;特征变量中引入了预期使用时长,可以起到微弱监督信号的作用。传统的用于异常检测的非监督学习模型是基于数据点之间的距离计算密度或是分离程度(距离),而这样的计算中不同的特征变量的贡献是相同的,若是特征变量之间本身的含义或是标度差异较大,则这样的计算存在不合理性。本方法中所使用的孤立森林算法不牵涉距离、密度等指标,而是通过组合不同的随机决策树对数据分割的情况孤立出样本中的异常点。此外,由于服务器使用时长与配置搭配合理性呈正相关,因此为了避免模型将预测使用时长“过高”的样本识别为异常样本,本方案对原有的孤立森林算法做出了改进,在模型识别异常样本时除了需要满足原方法中的异常得分高于一定阈值的条件,还需要额外满足预测使用时长小于一定阈值的条件。
24、本发明与现有的技术相比有以下几个方面的优势:第一,相比于基于规则和统计学的识别方式而言,该方法使用了机器学习相关的技术,可以综合考虑多个特征变量以及用户群组行为习惯的差异,解决了传统异常识别模型无法处理离散变量从而可能导致建模时重要信息缺失的问题。第二,本发明利用了服务器使用时长作为服务器搭配异常问题的弱监督信号,将通过模型预测得到的预期服务器使用时长加入非监督学习的特征变量和预测结果的筛选条件中,从而提升模型的表现力。第三,本发明使用了孤立森林算法来建立非监督学习模型,该算法不需要计算有关距离、密度的指标,且由于其基于ensemble(组合模型)架构,具有线性的时间复杂度,可大幅度提升速度,减小系统开销。孤立森林算法中的每颗决策树都是独立生成的,因此可以部署在大规模分布式系统上来加速运算,相比于传统算法更具有可拓展性,更适用于大数据场景,满足数据量不断增长下的需求。
- 还没有人留言评论。精彩留言会获得点赞!