一种基于层级任务信息的少样本视频动作识别方法及系统与流程
本发明涉及视频识别,尤其涉及一种基于层级任务信息的少样本视频动作识别方法及系统。
背景技术:
1、随着大数据和计算能力的增强,深度学习相关技术已经得到快速发展。在深度学习领域中,少样本学习已经被应用到许多下游任务中。例如,视频的显著性检测、视频跟踪以及视频的目标检测任务。当然,少样本动作识别任务也是下游任务其中之一,且该任务旨在用少量有标签的视频样本训练一个分类器,根据与已知动作相似程度对未知动作进行分类。
2、然而,现阶段的少样本动作识别方法仍存在两个问题:(1)在与动作识别视频相关的样本较少的条件下,训练出来的深度学习模型存在泛化性能差,难以适用于新的任务上;(2)不同视频内容具有特征间语义相关信息,使得训练出来的深度学习模型对于度量视频特征间语义相关性的能力较弱,导致度量效率与准确性不足。
3、因此,为了解决以上两个问题,有必要提供一种高泛化性能和高度量效率的少样本视频动作识别方法。
技术实现思路
1、本发明实施例所要解决的技术问题在于,提供一种基于层级任务信息的少样本视频动作识别方法及系统,用以解决现有少样本视频动作识别方法中泛化性能差及度量效率不足的问题。
2、为了解决上述技术问题,本发明实施例提供了一种基于层级任务信息的少样本视频动作识别方法,所述方法包括以下步骤:
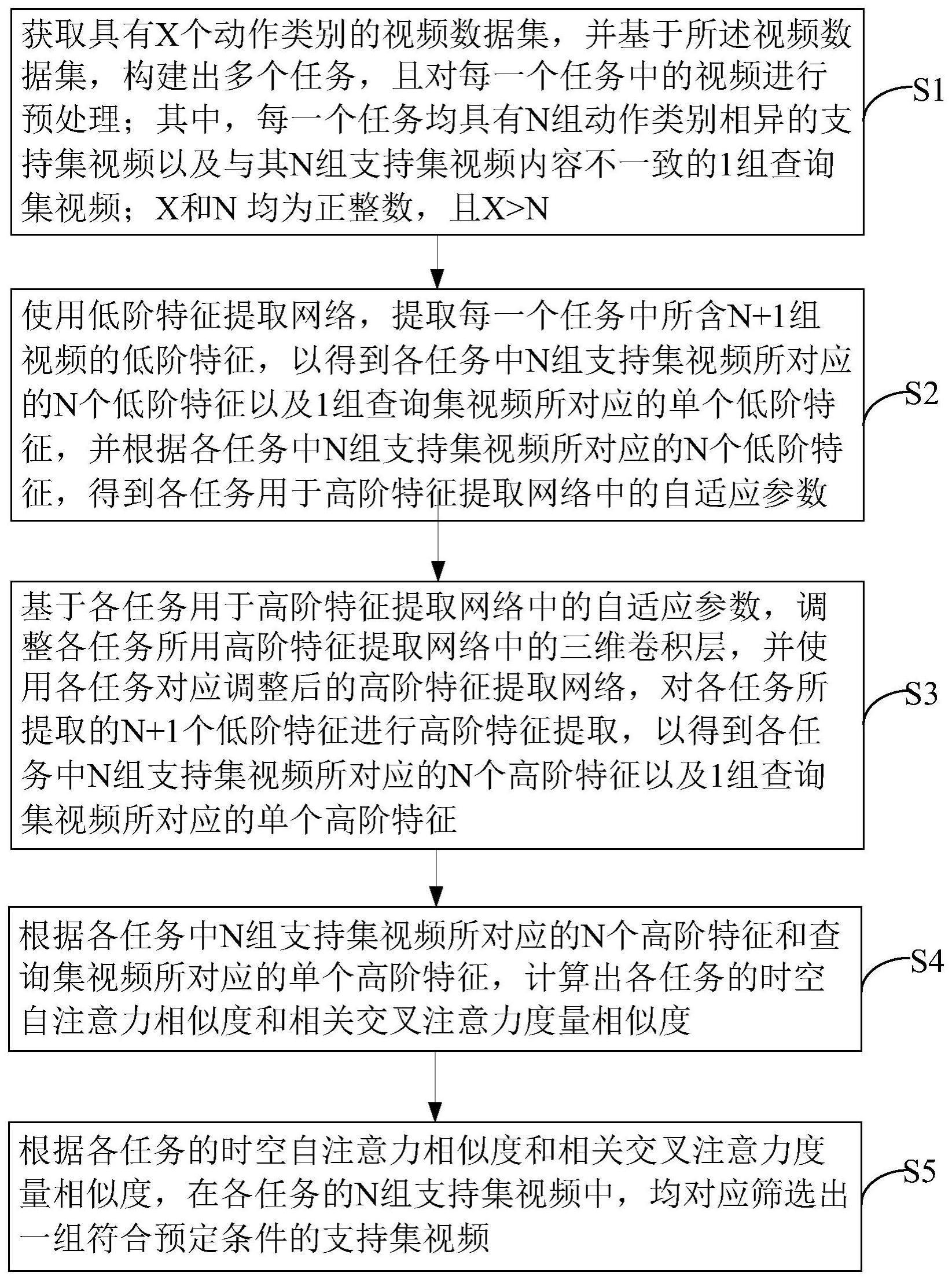
3、s1、获取具有x个动作类别的视频数据集,并基于所述视频数据集,构建出多个任务,且对每一个任务中的视频进行预处理;其中,每一个任务均具有n组动作类别相异的支持集视频以及与其n组支持集视频内容不一致的1组查询集视频;x和n均为正整数,且x>n;
4、s2、使用低阶特征提取网络,提取每一个任务中所含n+1组视频的低阶特征,以得到各任务中n组支持集视频所对应的n个低阶特征以及1组查询集视频所对应的单个低阶特征,并根据各任务中n组支持集视频所对应的n个低阶特征,得到各任务用于高阶特征提取网络中的自适应参数;
5、s3、基于各任务用于高阶特征提取网络中的自适应参数,调整各任务所用高阶特征提取网络中的三维卷积层,并使用各任务对应调整后的高阶特征提取网络,对各任务所提取的n+1个低阶特征进行高阶特征提取,以得到各任务中n组支持集视频所对应的n个高阶特征以及1组查询集视频所对应的单个高阶特征;
6、s4、根据各任务中n组支持集视频所对应的n个高阶特征和查询集视频所对应的单个高阶特征,计算出各任务的时空自注意力相似度和相关交叉注意力度量相似度;
7、s5、根据各任务的时空自注意力相似度和相关交叉注意力度量相似度,在各任务的n组支持集视频中,均对应筛选出一组符合预定条件的支持集视频。
8、其中,所述步骤s1具体包括:
9、构建视频数据集,所述视频数据集包括x个动作类别的动作视频;
10、将数据集划分成出m个任务,且每一个任务均包含n组不同动作类别的视频作为支持集视频,以及在这n类中随机挑选出1组与支持集视频的内容完全不一致的视频作为查询集视频;
11、对各任务中的每组支持集视频和查询集视频均进行预处理。
12、其中,所述对每组支持集视频和查询集视频均进行预处理的步骤均包括视频帧采样和采样之后帧图像处理,具体为:
13、随机选择每组视频的第一帧图像初始位置,然后连续采样16帧;
14、对每帧都裁剪成长宽分辨率为224×224的图像块,并进行归一化,得到归一化处理之后的n+1组视频被记作{sp1,sp2,...,spn,qpi};其中,sp1,sp2,...,spn表示归一化处理之后的n组不同动作类别的支持集视频;qpi表示归一化处理之后的1组动作类别i的支持集视频;i∈n。
15、其中,所述步骤s2具体包括:
16、确定低阶特征提取网络是由一层三维卷积层、一层归一化层和一层最大池化层构成的;
17、在每一个任务中,n+1组视频均经过所述低阶特征提取网络中的一层具有64个3×3×3的三维卷积核、输出通道为64的三维卷积层进行处理,得到fconv,并将fconv经过所述低阶特征提取网络中的归一化层进行处理,得到fbatchnorm,且进一步将fbatchnorm输入到所述低阶特征提取网络中的最大池化层进行处理,得到n组支持集视频所对应的n个低阶特征fsl和1组查询集视频所对应的单个低阶特征fql:
18、
19、fbatchnorm=batchnorm3(fconv);
20、其中,是一层包含了64个3×3×3的三维卷积核、输出通道个数为64的三维卷积层,vn={sn1,sn2,...,snn,qni};batchnorm3()表示归一化操作;
21、求解每一个任务中n组支持集视频所对应的n个低阶特征fsl各自的期望μ和标准差σ,并通过公式info=g(μ,diag(σ2)),对每一个任务所求解的期望μ和标准差σ进行多元高斯化,且进一步将每一个任务的多元高斯化的输出值info,均传入全连接层进行线性变换,以转化成各任务用于高阶特征提取网络的三维卷积自适应参数padaptive;其中,padaptive=f(info);info表示对期望μ和标准差σ进行多元高斯化的输出值;diag()表示对角矩阵构建函数。
22、其中,所述步骤s3具体包括:
23、基于各任务用于高阶特征提取网络中的自适应参数padaptive,调整各任务所用高阶特征提取网络中的三维卷积层;其中,每个任务所用高阶特征提取网络中三维卷积层均是三层具有64个3×3×3的三维卷积核、输出通道个数为64的三维卷积构成;
24、在每一个任务中,n+1个低阶特征均经过各自对应调整后的高阶特征提取网络中的三层具有64个3×3×3的三维卷积核、输出通道个数为64的三维卷积进行处理,得到n组支持集视频所对应的n个高阶特征fsh和1组查询集视频所对应的单个高阶特征fqh:
25、
26、
27、其中,所述步骤s4具体包括:
28、第一步、计算出各任务的时空自注意力相似度,具体为:
29、在每一个任务中,根据n组支持集视频所对应的n个高阶特征fsh和1组查询集视频所对应的单个高阶特征fqh,并通过公式mst=mean(fsh×(fsh)t),得到每组支持集视频的时空自注意力向量mst,以及通过公式mqt=mean(fqh×(fqh)t),得到查询集视频的时空自注意力向量mqt;其中,mean()表示求取平均值操作;t表示转置;
30、确定任务内学习器kinner()是由一层二维卷积层、一层relu非线性激活层、一层二维卷积层和softmax逻辑回归函数构成的;
31、将各任务中的每组支持集视频的时空自注意力向量mst和查询集视频的时空自注意力向量mqt分别输入任务内信息学习器kinner(),得到各任务的每组支持集视频的优化自注意力向量ast和各任务的查询集视频的优化自注意力向量aqt;其中,ast=kinner(mst);aqt=kinner(mqt);
32、通过公式tst=fsh×ast+fsh,得到各任务中的每组支持集视频的强化时空自信息的特征tst,以及通过公式tqt=fqh×aqt+fqh,得到各任务中的查询集视频的强化时空自信息的特征tqt;
33、通过公式simt=dcos(tst,tqt),计算每一个任务中的查询集视频的强化时空自信息的特征tqt与其同任务中每一组支持集视频的强化时空自信息的特征tst的余弦距离,以得到各任务的n个时空自注意力相似度simt:
34、第二步、计算出各任务的相关交叉注意力度量相似度,具体为:
35、在每一个任务中,根据n组支持集视频所对应的n个高阶特征fsh和1组查询集视频所对应的单个高阶特征fqh,并通过公式msr=mean(fsh·(fqh)t),得到每组支持集视频的相关交叉注意力向量msr,以及通过公式mqr=mean(fqh·(fsh)t),得到查询集视频的相关交叉注意力向量mqr;
36、将各任务中的每组支持集视频的相关交叉注意力向量msr和查询集视频的相关交叉注意力向量mqr分别输入任务内信息学习器kinner(),得到各任务的每组支持集视频的优化相关交叉注意力向量asr和各任务的查询集视频的优化相关交叉注意力向量aqr;其中,asr=kinner(msr);aqr=kinner(mqr);
37、通过公式rsr=fsh×asr+fsh,得到各任务中的每组支持集视频的强化时空自信息的特征rsr,以及通过公式rqr=fqh×aqr+fqh,得到各任务中的查询集视频的强化时空自信息的特征rqr;
38、通过公式simr=dcos(rsr,rqr),计算每一个任务中的查询集视频的强化时空自信息的特征rqr与其同任务中每一组支持集视频的强化时空自信息的特征rsr的余弦距离,以得到各任务的n个相关交叉注意力相似度simr。
39、其中,所述步骤s5具体包括:
40、在每一个任务中,根据所得到的n个时空自注意力相似度simt与n个相关交叉注意力相似度simr,确定出同属一个动作类别的时空自注意力相似度simt及交叉注意力相似度simr,并通过公式sim=α×simt+(1-α)×simr,得到查询集视频与n组支持集视频所对应的n个相似度sim;
41、将各任务中所对应得到的n个相似度sim均进行从大到小排序,并在每一个任务的n组支持集视频中,对应筛选出相似度sim均为最大时所对应的支持集视频。
42、本发明实施例还提供了一种基于层级任务信息的少样本视频动作识别系统,包括:
43、视频任务构建单元,用于获取具有x个动作类别的视频数据集,并基于所述视频数据集,构建出多个任务,且对每一个任务中的视频进行预处理;其中,每一个任务均具有n组动作类别相异的支持集视频以及与其n组支持集视频内容不一致的1组查询集视频;x和n均为正整数,且x>n;
44、低阶特征提取单元,用于使用低阶特征提取网络,提取每一个任务中所含n+1组视频的低阶特征,以得到各任务中n组支持集视频所对应的n个低阶特征以及1组查询集视频所对应的单个低阶特征,并根据各任务中n组支持集视频所对应的n个低阶特征,得到各任务用于高阶特征提取网络中的自适应参数;
45、高阶特征提取单元,用于基于各任务用于高阶特征提取网络中的自适应参数,调整各任务所用高阶特征提取网络中的三维卷积层,并使用各任务对应调整后的高阶特征提取网络,对各任务所提取的n+1个低阶特征进行高阶特征提取,以得到各任务中n组支持集视频所对应的n个高阶特征以及1组查询集视频所对应的单个高阶特征;
46、相似度计算单元,用于根据各任务中n组支持集视频所对应的n个高阶特征和查询集视频所对应的单个高阶特征,计算出各任务的时空自注意力相似度和相关交叉注意力度量相似度;
47、视频识别单元,用于根据各任务的时空自注意力相似度和相关交叉注意力度量相似度,在各任务的n组支持集视频中,均对应筛选出一组符合预定条件的支持集视频。
48、实施本发明实施例,具有如下有益效果:
49、1、本发明通过元学习来解决样本少的问题。元学习的目的是为了让深度神经网络“学会学习”,通过对神经网络的设计,并在有少量样本作为预训练的前提下,使得神经网络模型能够快速的泛化到其他场景中去,能够解决现有少样本视频动作识别方法中泛化性能差及度量效率不足的问题;
50、2、本发明通过少量样本就能使得深度学习模型具有较高的泛化性能和较高的度量性能,而且根据输入任务动态生成特征提取网络的自适应参数,用以构建任务相关特征空间,进而提升模型泛化性;
51、3、本发明将任务内信息学习器结合自注意力机制、交叉注意力机制,用以挖掘任务内特征关键自信息和互信息,强化特征时空关键信息及特征间相关性,进而提升度量效率。
- 还没有人留言评论。精彩留言会获得点赞!