知识图谱构建方法、CWE社区描述方法以及存储介质与流程
本发明涉及网络安全,具体涉及一种知识图谱构建方法、cwe社区描述方法以及存储介质。
背景技术:
1、当前很多开源软件被广泛使用,比如操作系统领域的开源软件android和linux;大数据领域的开源软件hadoop(一个由apache基金会所开发的分布式系统基础架构)、spark(指apache spark,是专为大规模数据处理而设计的快速通用的计算引擎)和storm(一款网络服务测试工具);数据库领域的开源软件mysql(一个关系型数据库管理系统)和tomcat(一个web服务器软件)等。基于此,软件的安全性得到了广泛的关注,越来越多的漏洞分析文章踊跃出现在互联网上。比如先知社区论坛、freebuf(国内的一个互联网安全新媒体)社区、洞悉漏洞社区、洞见安全社区等,这些论坛汇集了大量的关于漏洞安全的分析文章。其中,有的文章是对某一个具体漏洞的攻击过程分析,有的是对某一个具体漏洞的应对措施描述,有的则是对某一组件(比如apache:storm组件)或者某一类型漏洞(比如sql注入)的综合分析等。若能把这些文章有效地利用起来,对漏洞的分析以及对相关研究或者工作人员有着十分重要的意义。
2、业界对漏洞分析文章的利用侧重点在于,针对某一个或者某一类型的漏洞,能够快速定位到其所属的分析文章,使网络安全的工作人员或者漏洞研究人员能够快速洞悉该漏洞攻击的实现过程、涉及的组件、使用的技术,以及应该采取的缓解措施等信息。目前业界对此的处理机制,主要是利用一些预定的规则,结合一些关键字、正则匹配、模糊匹配技术来实现快速定位、筛选文章的作用,其优点是:准确率较高、较直观、便于进行规则用途的扩展,比如进行知识推理、信息和关系挖掘等。
3、针对上述相关技术,发明人认为还存在如下缺点:对文章所属的cwe(commonweakness enumeration,常见缺陷列表)社区没有一个比较标准化的描述,影响网络安全研究人员的工作效率。
技术实现思路
1、为了解决现有技术中的上述问题,本发明提出了一种知识图谱构建方法、cwe社区描述方法以及存储介质,提供了一种规范化描述cwe社区的方法。
2、本发明的第一方面,提出一种知识图谱构建方法,所述方法包括:
3、对多个漏洞分析文章的内容进行实体识别,得到文章实体;
4、基于所述文章实体、cwe实体、capec(common attack pattern enumeration andclassification,攻击类型枚举和分类数据集)实体和cve(common vulnerabilities andexposures,通用漏洞披露)实体,构建所述知识图谱的实体列表;
5、根据所述文章中的漏洞名,在所述文章实体与所述cve实体之间建立映射关系;
6、根据所述cve实体中的cwe_id,在所述cve实体与所述cwe实体之间建立映射关系;
7、根据所述capec实体中的cwe_id,在所述capec实体与所述cwe实体之间建立映射关系,从而完成所述知识图谱的构建。
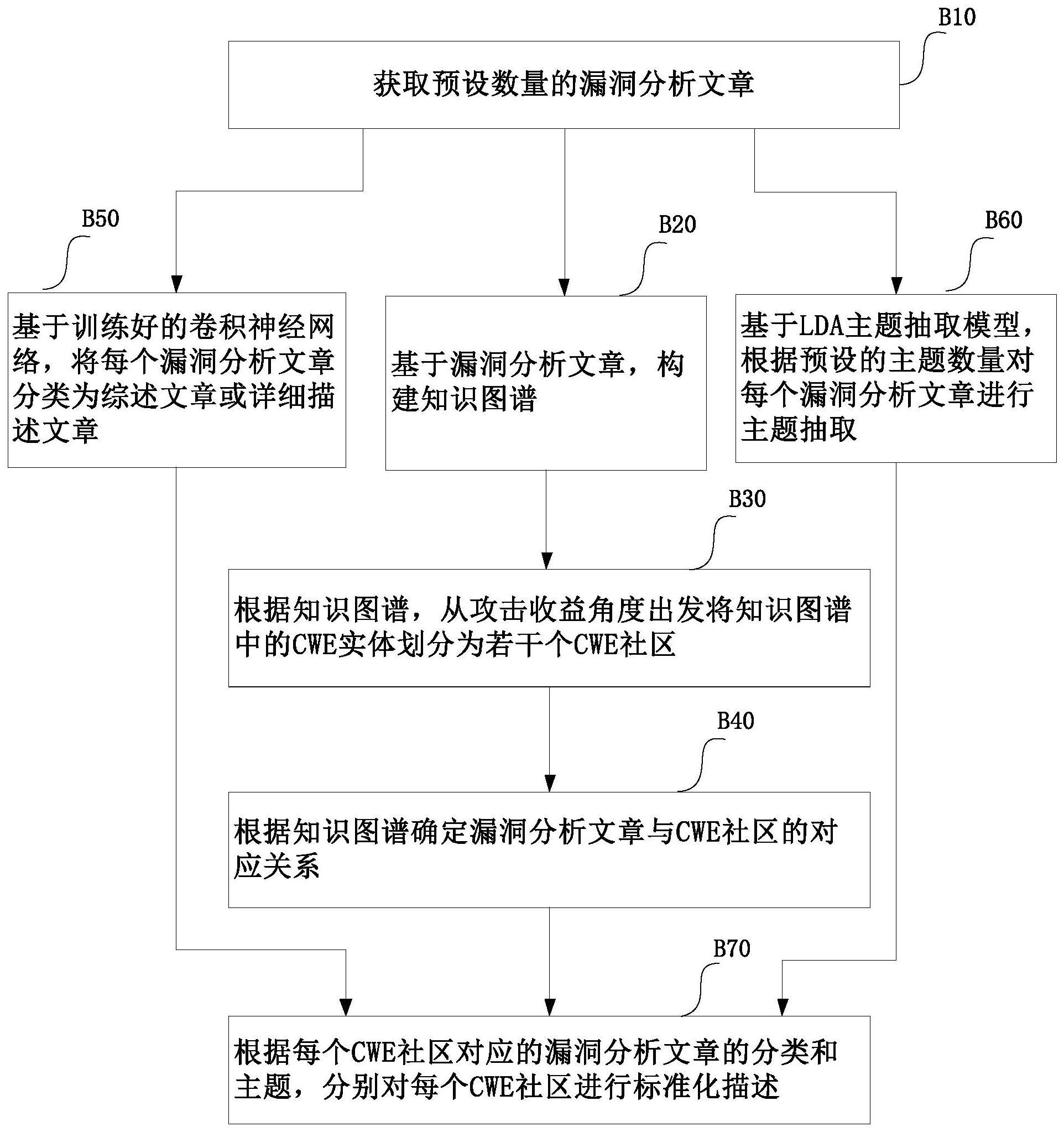
8、优选地,所述文章实体的属性包括:文章标题、文章内容和文章的可读性;
9、所述cwe实体为cwe数据集中的漏洞,所述cwe实体的属性包括:名称和描述信息;
10、所述capec实体为capec数据集中的漏洞,所述capec实体的属性包括:名称、描述信息、攻击收益和攻击难度;
11、所述cve实体为cve数据集中的漏洞,所述cve实体的属性包括:名称、攻击收益向量、攻击组件向量、cvss(common vulnerability scoring system,通用漏洞评分系统)评分和对应的cwe_id。
12、优选地,所述文章的可读性包括:复现漏洞层面的可读性、漏洞执行层面的可读性、补丁和缓解措施层面的可读性、漏洞分析层面的可读性,以及文章长度的可读性。
13、本发明的第二方面,提出一种cwe社区描述方法,所述方法包括:
14、获取预设数量的漏洞分析文章;
15、基于所述漏洞分析文章,利用上面所述的知识图谱构建方法,构建知识图谱;
16、根据所述知识图谱,从攻击收益角度出发将所述知识图谱中的所述cwe实体划分为若干个cwe社区;
17、根据所述知识图谱确定所述漏洞分析文章与所述cwe社区的对应关系;
18、基于训练好的卷积神经网络,将每个所述漏洞分析文章分类为综述文章或详细描述文章;
19、基于lda(latent dirichlet allocation,隐含狄利克雷分布)主题抽取模型,根据预设的主题数量对每个所述漏洞分析文章进行主题抽取;
20、根据每个所述cwe社区对应的所述漏洞分析文章的分类和主题,分别对每个所述cwe社区进行标准化描述。
21、优选地,所述根据所述知识图谱确定所述漏洞分析文章与所述cwe社区的对应关系,包括:
22、根据所述知识图谱中所述文章实体与所述cve实体之间的映射关系,以及所述cve实体与所述cwe实体之间的映射关系,确定所述漏洞分析文章与所述cwe社区的对应关系。
23、优选地,所述根据每个所述cwe社区对应的所述漏洞分析文章的分类和主题,分别对每个所述cwe社区进行标准化描述,包括:
24、根据所述漏洞分析文章的分类情况,统计某个cwe社区对应的综述文章的数量和详细描述文章的数量,进而计算数量较多的那一类文章的占比;
25、根据抽取结果,确定该cwe社区对应的每个漏洞分析文章的主题;
26、将该cwe社区对应的各漏洞分析文章的主题词分布相加并求平均值,得到该cwe社区的主题词平均分布;
27、将所述主题词平均分布中的所有主题词按出现频率的高低进行排序;
28、按照所述占比截取排在前面的主题词,用于对该cwe社区进行标准化描述。
29、优选地,所述卷积神经网络包括:预处理模块、第一子网络、第二子网络、拼接层、第一全连接层、第二全连接层、归一化层和概率输出层;
30、其中,
31、所述预处理模块用于对待分类文章的内容和标题进行预处理,得到所述待分类文章内容的词向量和标题的词向量;
32、所述第一子网络和所述第二子网络分别用于对所述待分类文章内容的词向量和标题的词向量进行特征提取,得到第一特征向量和第二特征向量;
33、所述第一全连接层用于对所述待分类文章的可读性属性进行维度转换,得到与所述第一特征向量和所述第二特征向量维度相同的可读性向量;
34、所述拼接层用于对所述第一特征向量、所述第二特征向量和所述可读性向量进行拼接,得到拼接后的特征向量;
35、所述归一化层用于对所述拼接后的特征向量进行归一化处理;
36、所述第二全连接层用于对归一化后的特征向量进行融合;
37、所述概率输出层用于根据融合后的结果计算二分类的概率值。
38、优选地,所述预处理包括:将所述待分类文章的内容进行分词、去除停用词、向量化和长度补齐,将所述待分类文章的标题进行分词、去除停用词和向量化,从而得到所述待分类文章内容的词向量和标题的词向量;
39、所述待分类文章的可读性属性从所述知识图谱中获取得到。
40、优选地,所述第一子网络与所述第二子网络结构相同,均包括:词嵌入层、卷积层和池化层。
41、本发明的第三方面,提出一种计算机可读存储介质,存储有能够被处理器加载并执行如上面所述方法的计算机程序。
42、与最接近的现有技术相比,本发明具有如下有益效果:
43、本发明在构建知识图谱时,cve实体和cwe实体的映射关系通过cve实体的字段cwe_id进行映射,而不再对二者的映射关系进行描述,把cve和cwe划分到两个不同的子图中;同样,capec实体和cwe实体的映射关系通过capec实体中的cwe_id进行映射,把capec也放到一个单独的子图中。因此,构建的知识图谱复杂度较低。
44、本发明从自然语言处理方向出发,利用深度学习中的卷积神经网络技术结合文章的多维度特征(文章可读性属性、文章内容、标题等),并对特征进行了拼接、融合,有效地实现了漏洞分析文章的分类。
45、本发明利用基于模块度的社区发现算法对cwe划分的社区,结合漏洞分析文章的分类结果,从主题抽取角度出发对cwe社区进行了规范化的描述,避免了人工制定大量规则,有效提高了网络安全研究人员的工作效率。
- 还没有人留言评论。精彩留言会获得点赞!