基于深度学习语义特征分离的空域小目标检测方法
本发明涉及计算机视觉领域,具体而言,涉及一种基于深度学习语义特征分离的空域小目标检测方法。
背景技术:
1、近年来随着无人机技术的不断发展,无人机技术在运输、航拍、电业、安防等多个行业得到了越来越多的应用,促进了相关工业和商业的繁荣。同时,随着无人机技术的发展和数量的增多,无人机技术在带来便利的同时,无人机的违规使用越来越多,给公共治安和个人隐私带来了极大的危害。相比传统飞行器,无人机具有更小的体积,更高的机动性,更强的隐蔽性,并且更易获得,因此无人机的“黑飞”,“滥飞”逐渐成为一个严重危害个人和公众治安的安全问题。如何有效检测、跟踪、反制非法入侵的无人机已经成为一个越来越重要的技术安全研究领域,而如何有效检测无人机是跟踪、反制无人机的前提条件,尤为重要。由于无人机体积小,飞行高度较高,距离远,因此无人机在成像时通常呈现出小目标的特征,即像素数量少,所含有的特征信息少,难以准确检测。目前的空域小目标检测问题存在诸多挑战,现有的神经网络目标检测方法并不能直接准确检测到目标,亟需设计一种准确可靠、低漏检率的空域小目标检测方法。
2、需要说明的是,在上述背景技术部分公开的信息仅用于加强对本公开的背景的理解,因此可以包括不构成对本领域普通技术人员已知的现有技术的信息。
技术实现思路
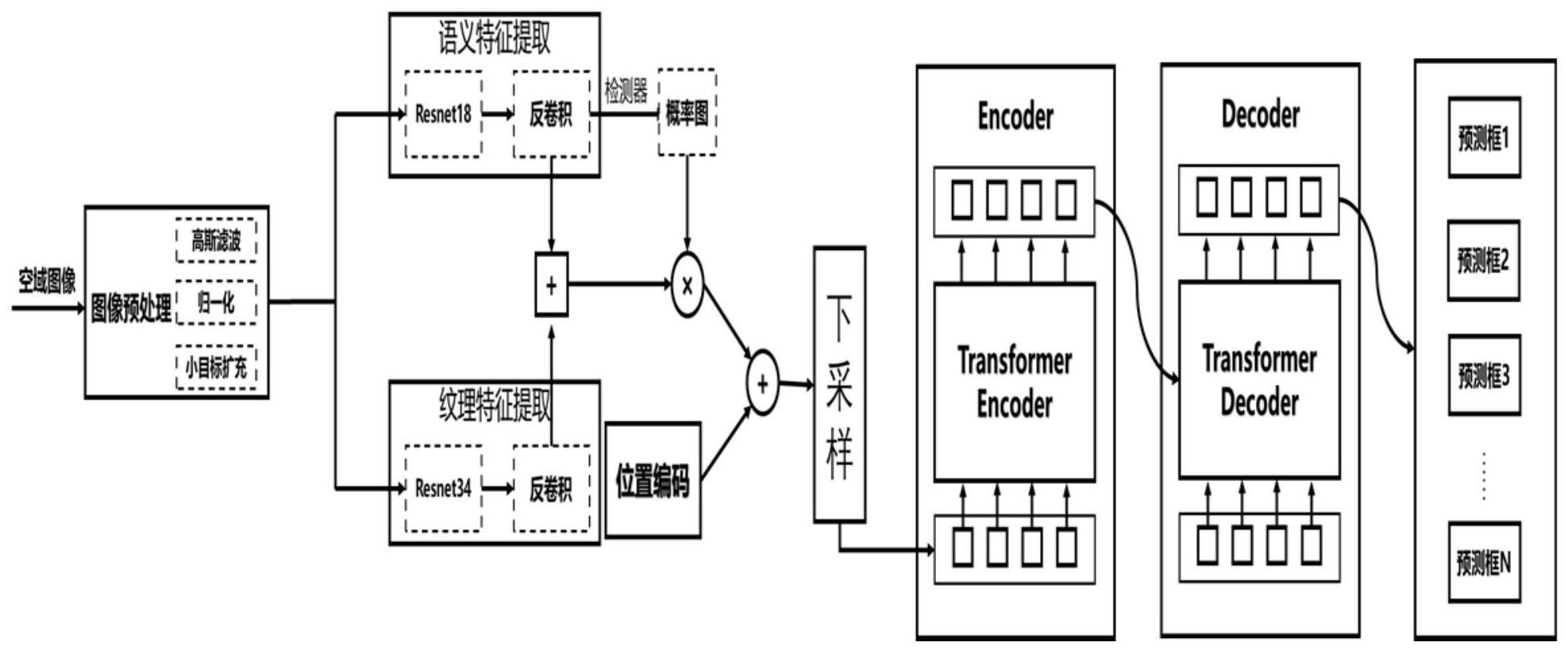
1、有鉴于此,本发明提供一种基于深度学习语义特征分离的空域小目标检测方法,对于输入的图片首先通过高斯滤波、尺寸变化、小目标扩充进行预处理,之后利用神经网络进行图片中语义和纹理特征提取、反卷积进行上采样、通道点乘进行背景滤波,最后在抑制背景噪声、提取疑似目标特征的基础上,通过transformer提取全局特征,提高神经网络检测器对小目标的感知能力,以实现高准确度,高召回率的空域小目标检测。
2、本公开的其他特性和优点将通过下面的详细描述变得显然,或部分地通过本公开的实践而习得。
3、根据本公开实例的第一方面,提供了一种基于深度学习语义特征分离的空域小目标检测方法,包括图片预处理、语义和纹理特征提取、概率滤波、全局预测框生成、动态预测框匹配五个步骤:
4、步骤一:对输入的空域图片进行预处理,首先采用高斯滤波消除噪声干扰,突出图片边缘,之后采用尺寸变换、小目标扩充方法提高对空域小目标的学习能力;
5、步骤二:采用resnet18与resnet34分别对步骤一处理后的目标图片进行语义信息与纹理信息的提取,之后通过反卷积操作分别进行上采样,提高特征的分辨率与信息丰富度;
6、步骤三:首先利用检测器生成空间内表征目标存在的概率图,之后对目标语义特征和纹理特征进行特征之间的转换拼接,采用概率图滤波处理拼接后的特征,消除背景特征干扰,保留目标前景特征,通过降低背景所在区域的数字特征值,稀疏化目标特征表征空间;
7、步骤四:采用transformer结构网络,利用编码器encoder和解码器decoder分别对特征空间进行编码与解码操作,提取目标特征间的关联性,通过关联性抑制背景噪声并且强化与目标相关的区域特征,最后通过线性网络生成多个目标预测框集合;
8、步骤五:采用匈牙利算法,将预测问题视为线性规划问题,在不依赖先验信息的基础上,通过最小化类别损失、预测框回归损失和交并比损失,实现预测框信息与真实框信息之间多对少的最优动态匹配机制,并且调整网络相关参数。
9、进一步地,所述图片预处理中,利用固定数值的长宽皆为奇数的高斯核对图片进行卷积操作,消除噪声干扰,突出目标特征;之后利用图片归一化将像素值进行高斯分布转换,转化为[0,1]之间的数值,消除数值分布引起的误差并便于输入深度神经网络;
10、高斯滤波算法中高斯核大小为u×u,在卷积运算时将高斯核水平滑动,并计算滤波后图片在高斯核中心处的数值,计算过程如公式(1)所示:
11、
12、其中yij是输出图片在ij处的数值,α为超参数,αhw是高斯核在hw处的数值,y(i-h)(j-w)是输入图片在(i-h)(j-w)处的数值,且
13、图片归一化过程中对rgb三个通道分别进行归一化;首先将每一个像素分别除以255,将值限制在[0,1],之后对每一个通道的值进行高斯归一化,在高维空间中将所有像素的数学分布转化为均值为0,方差为1的高斯分布,消除像素分布不均匀带来的误差,归一化公式如公式(2)所示:
14、
15、其中c代表了通道数,c∈{r,g,b},ycij为c通道ij处归一化后的输出值,ycij为c通道ij处归一化前的输入值,μc为c通道的均值,σc为c通道的均方误差。
16、进一步地,所述图片预处理中,小目标扩充方法将图片中的小目标区域的像素通过随机分配在图片中进行复制,在深度神经网络训练过程中增强了深度神经网络对小目标的关注与学习能力;小目标扩充公式如公式(3)所示:
17、
18、其中表示区域的像素值,ch,cw为小目标区域的中心点,a,b为小目标区域的高和宽,ch′,w′为通过随机算法产生的扩充区域的中心点,s为输入图片的尺寸。
19、进一步地,所述步骤二中,采用resnet18与resnet34分别对步骤一处理后的目标图片进行语义信息与纹理信息的提取;
20、resnet18与resnet34网络输入均为大小为s×s,通道为3的图片,首先通过卷积层,批归一化层,激活层组成的基础层basiclayer将输入图片转化为通道为64的特征图;
21、resnet18与resnet34网络主要由残差模块basicblock构成,由两部分构成,一部分为主干网络,将输入图片不经过任何处理直接输入至输出层,另一部分将输入图片经过多层basiclayer提取目标特征,作为小量,最后将两个部分的输出值进行数值相加;basicblock的公式如公式(4)所示:
22、y=x+basiclayer(x)*n且basiclayer(x)=relu(bachnorm(conv(x))) (4)
23、其中y为basicblock的输出,x为basicblock的输入,n代表了basicblock中含有basiclayer的层数,conv为卷积函数,bachnorm为批归一化函数,relu为relu激活函数;
24、公式(4)中在确保分支basiclayer(x)*n的输出相比x为小量的前提下,确保y与x的大小维持相对稳定,在网络训练过程中保证了basicblock的输出y与输入x保持接近的数据分布,使得深层神经网络的训练成为可能。
25、进一步地,所述步骤二中,将resnet提取的特征进行反卷积,扩大卷积提取特征的尺寸,缩小提取特征的通道数;反卷积操作可以被视为对特征进行上采样操作,扩大特征的空间尺寸。
26、进一步地,所述步骤三中,利用检测器生成空间内表征目标存在的概率图,之后对目标语义特征和纹理特征进行特征之间的转换拼接,包括:
27、为了更好地检测小目标,在经过resnet18进行特征提取并且上采样处理后,网络将图像8×8的区域视为一个检测单元,检测器通过概率图相应点的值的大小表征相应区域是否存在目标的概率;
28、在概率图上设置表示预测效果的损失函数lk,如公式(5)所示:
29、
30、其中为概率图在xy处存在目标中心的概率预测,α,β为超参数值,yxyc为预设的概率图的真实值;预测值越接近预设值yxyc,相应位置损失越小;
31、预设值yxyc表征相应区域是否存在目标;当区域内不存在目标时,预设值yxyc为0;当相应区域内存在目标中心时,预设值yxyc为1;当相应区域内不存在目标中心但是区域在目标范围内时,使用高斯分布表示区域内存在目标的概率以及区域距离目标中心的距离;yxyc如公式(6)所示:
32、
33、其中px,px为目标中心点的x,y坐标;σ为与目标物体尺寸相关的方差值,具体地,σ与目标检测框的大小和长宽比例有关,如公式(7)所示:
34、
35、其中γ为超参数,hb,wb为目标检测框的高和宽;
36、在生成概率图后,将语义信息与纹理信息进行通道的拼接,如公式(8)所示:
37、
38、其中f1,f2分别为两通道提取的语义特征与纹理特征,c1,c2分别为两个特征的通道数,yc为拼接后的特征,拼接后的通道数c=c1+c2。
39、进一步地,所述步骤三中,采用概率图滤波处理拼接后的特征,消除背景特征干扰,保留目标前景特征,通过降低背景所在区域的数字特征值,稀疏化目标特征表征空间,包括:
40、resnet18与resnet34网络提取的场景语义信息与纹理信息包含背景信息与目标信息,因此通过抑制背景能够增强深度神经网络对目标的注意力,消除背景的影响;步骤三中生成的概率图正确反应了目标的分布,在存在目标的区域概率图数值更大,接近1,而在背景区域概率图数值接近0;在通过概率图与拼接特征进行点乘操作后,背景区域更加接近0,稀疏化特征张量,滤除背景信息,目标区域信息得到保留,达到抑制背景,增强前景的目的;
41、将概率图看作滤波器,通过点乘操作能够消除背景信息影响,突出目标信息区域,如公式(9)所示:
42、ycij=pij·xcij (9)
43、其中pij为步骤三中生成的概率图在ij处的值,xcij为语义信息与纹理信息拼接后的特征在ij处c个通道的向量,ycij为滤波操作后的输出在ij处c个通道的向量。
44、进一步地,所述步骤四包括:
45、多层encoder和decoder都由transformer结构构成,transformer结构主要由线性层和多头注意力机制模块multihead构成;
46、首先对步骤三得到的稀疏化后的语义信息与纹理信息拼接后的特征,使用卷积层进行下采样操作,缩小特征的通道维度,减小后续的transformer结构的输入的维度;
47、对每一个输入transformer的数据首先通过multihead的线性层生成三个数据k(key),q(query),v(value),k,q,v分别为一维向量数据,维度为d;multihead将每一个k,q,v分成多个小规模的向量,每一个维度为dh=d/nh,dh为multihead所含有的head的数量;之后通过k,q的乘积计算每一个数据之间的关联性矩阵,之后由关联性矩阵与v相乘生成输出;
48、multihead中每个head的输出attention(q,k,v)计算如公式(10)所示:
49、
50、之后将所有head的输出结果进行连接,具体过程如公式(11)所示:
51、
52、其中为nh个注意力头的输出结果,wo为转换矩阵,用于将拼接后的多头注意力结果在特征空间上进行投影;
53、由于特征空间上数值的位置与整体语义相关,因此加入位置编码表征特征空间的位置;在特征空间(i,2j),(i,2j+1处位置编码如公式(12)所示:
54、
55、
56、通过多个encoder和decoder处理将步骤四得到的特征转换为包含了全局信息与关联性信息的特征向量,达到抑制背景噪声并且强化与目标相关的区域特征的效果;
57、得到的特征向量通过三个检测器进行检测,生成nb个预测框;三个检测器分别生成目标种类、目标中心点、预测框大小,通过整合三个检测器的输出信息即可得到nb个预测框。
58、进一步地,所述步骤五包括:
59、在训练阶段,利用匈牙利算法进行二分图匹配,将预测框集合与真实框集合进行二分图匹配,选择匹配度最高的预测框作为最佳预测框,使得总体的损失最小,并且通过梯度下降算法降低损失;
60、在预测阶段,直接选择预测类别置信度高于阈值的预测框作为最终预测框。
61、根据本公开实施例的第二方面,提供了一种基于深度学习语义特征分离的空域小目标检测装置,包括存储器和一个或多个处理器,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,用于实现如第一方面所述的基于深度学习语义特征分离的空域小目标检测方法。
62、本发明的有益效果在于:
63、1.针对神经网络检测器在空域小目标检测上性能不好的问题,设计了语义、纹理特征提取分离的网络实现语义识别与框坐标回归任务分离,避免了任务引起的结构耦合。
64、2.通过检测器对语义信息进行处理得到反应目标与背景存在的概率图,使用概率图对语义信息和纹理信息拼接的特征进行点乘滤波以此稀疏化特征空间,抑制背景噪声。
65、3.设计一种基于transformer的网络,对特征进行处理获得全局相关性特征。之后通过检测器预测得到一定数量的预测框。在训练阶段由匈牙利算法对预测框和真实框进行最佳的动态匹配,并且通过反向传播算法训练网络;在预测阶段,直接选择预测类别置信度高于阈值的预测框作为最终预测框。
66、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。
- 还没有人留言评论。精彩留言会获得点赞!