基于MapReduce的大数据处理方法及系统
基于mapreduce的大数据处理方法及系统
技术领域
1.本发明涉及一种基于mapreduce的大数据处理方法,属于计算机领域。
背景技术:
2.mapreduce是一种用于大规模数据集并行计算的编程模型,借助于函数式程序设计语言思想,用map和reduce两个函数编程实现并行计算任务,具有多种高效的实现方式。所有这些实现都向开发人员公开了应用程序编程接口(api),虽然具体语法在不同的api之间略有不同,但它们都需要理解已有代码功能并能重写map和reduce函数计算,以实现mapreduce框架的优化。对于不熟悉mapreduce程序的开发人员来说,亟需学习不同api并且在保证无误的条件下重写代码和算法重构,这无疑具有不小的难度。
3.(1)现有的大数据处理框架(例如hadoop,spark),都是要求程序员首先了解其api,然后利用这些api编写mapreduce代码,这对于刚刚上手的程序员需要学习的时间很长,往往在工作时没有这么长的时间周期。
4.(2)现有的大数据处理框架对于迭代逻辑的实现效果很差,常见的大数据处理框架例如hadoop不支持迭代,spark为了相对减少一些处理迭代时候的i/o读取,根据数据库建立弹性数据集rdd(可以理解为一个小数据库,只能读,一般建立在内存中),rdd的建立是需要经验的,要人为的去判断哪些数据可能会频繁读取,依靠人为经验建立的rdd有些时候会显著提升效率,但是有些时候,如果rdd中的数据没有频繁被调用,反而对最后的效果没有太大帮助,并且,rdd需要定期更新,因为建立rdd所依赖的数据库是中的数据是会变化的,所以rdd只是较为特殊的情况下才能很高的提升迭代效率,以上导致目前基于mapreduce的迭代逻辑几乎不能进行处理,因为迭代逻辑本身的特性是有很多数据会进行重复的利用,势必要造成i/o读写次数极多,十分耗费时间,效率很低,即使有像spark针对于i/o进行了优化,但是不保证效果一定很好,甚至有些时候利用spark处理迭代,效果还不如利用hadoop手动编排mapper和reducer实现迭代的效果好。
技术实现要素:
5.针对现有大数据处理框架对于迭代逻辑的实现效果差的问题,本发明提供一种基于mapreduce的大数据处理方法及系统。
6.本发明提供一种基于mapreduce的大数据处理方法,包括
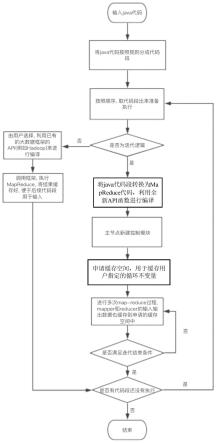
7.s1、输入java代码,将java代码分成java代码段;
8.s2、按照java代码段的执行顺序,取出java代码段,判断取出的每个java代码段是否为迭代逻辑,所述java代码段若是迭代逻辑,将java代码段转换为mapreduce代码,利用全新api函数进行编译,得到执行结果,所述全新api函数为:
9.主节点新建一个job控制模块,该job控制模块不断的启用map-reduce过程来实现mapreduce代码的迭代逻辑,用户定义循环不变量,主节点申请缓存空间,用来存储用户定义的循环不变量及每次mapper和reducer的输入输出缓存,并建立索引,job控制模块进行
多个map-reduce过程中,根据索引从缓存空间中取出需要的数据;
10.当迭代满足终止条件,结束迭代,获得mapreduce代码的执行结果,作为下一个代码段的输入;
11.所述java代码段若不是迭代逻辑,将java代码段转换为mapreduce代码,利用已有大数据框架的api进行编译该mapreduce代码,获得的执行结果作为下一个代码段的输入。
12.作为优选,将java代码段转换为mapreduce代码的方法,包括:
13.将java代码段转换为中间代码,并将中间代码进行摘要,搜索与摘要相类似表述的api函数,利用api函数将摘要转换成mapreduce码。
14.作为优选,将java代码段转换为mapreduce代码的方法,还包括:
15.将java代码段和转换的mapreduce码进行编译获得结果,如果结果相同,证明mapreduce代码转换成功,否则,更换api函数,重新将摘要转换成mapreduce码。
16.作为优选,已有大数据框架包括hadoop和spark。
17.作为优选,迭代终止条件为两次迭代结果相等,或者当前迭代次数达到最大迭代次数。
18.本发明还提供一种基于mapreduce的大数据处理系统,包括:
19.拆分模块,用于输入java代码,将java代码分成java代码段,按照java代码段的执行顺序,取出java代码段;
20.处理模块,用于判断取出的每个java代码段是否为迭代逻辑,所述java代码段若是迭代逻辑,将java代码段转换为mapreduce代码,利用全新应用程序编程接口模块进行编译,得到执行结果,当迭代满足终止条件,结束迭代,获得mapreduce代码的执行结果,作为下一个代码段的输入;所述java代码段若不是迭代逻辑,将java代码段转换为mapreduce代码,利用已有mapreduce模块进行编译该mapreduce代码,获得的执行结果作为下一个代码段的输入;
21.全新应用程序编程接口模块包括job控制模块和缓存模块;
22.job控制模块,用于不断的启用map-reduce过程来实现mapreduce代码的迭代逻辑,获得执行结果;
23.缓存模块,与job控制模块连接,用于存储用户定义的循环不变量及每次mapper和reducer的输入输出缓存,并建立索引;job控制模块在进行多个map-reduce过程中,根据索引从缓存空间中取出需要的数据。
24.作为优选,所述处理模块采用编译器将java代码段转换为mapreduce代码,所述编译器用于将java代码段转换为中间代码,并将中间代码进行摘要,搜索与摘要相类似表述的应用程序编程接口模块,利用该应用程序编程接口模块将摘要转换成mapreduce码。
25.作为优选,所述编译器,还用于将java代码段和转换的mapreduce码进行编译获得结果,如果结果相同,证明mapreduce代码转换成功,否则,更换应用程序编程接口模块,重新将摘要转换成mapreduce码。
26.作为优选,所述mapreduce模块为基于hadoop的mapreduce模块或基于spark的mapreduce模块。
27.本发明的有益效果,本发明适用于处理需要迭代计算的mapreduce程序编译,通过添加缓存功能,缓存中间结果及循环不变量,减少了i/o次数,节省了时间,避免了在多次迭
代中处理相同数据造成的资源浪费的问题。同时,本框架重新规定了迭代逻辑的执行方法,执行效率更高。同时,该框架不需要程序员熟悉mapreduce相关的api,只需要编写java代码即可,方便入门。
附图说明
28.图1为本发明的流程示意图。
具体实施方式
29.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
30.需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
31.下面结合附图和具体实施例对本发明作进一步说明,但不作为本发明的限定。
32.本实施方式的基于mapreduce的大数据处理方法,包括:
33.步骤1、输入java代码,将java代码分成java代码段;
34.(1)代码第一行为一个代码段的首代码;
35.(2)紧跟在条件跳转语句的后一句为代码段的首代码;
36.例如:
37.if(
…
)
38.{a}
39.else
40.{b}
41.这里a和b的第一行代码就是代码段的首代码;
42.(3)跳转语句的目标语句为代码段的首代码,例如:
43.int a=0;
44.string m=
“”
;
45.label:int size=m.length();
46.char x=
‘
a’;
47.for(a;a《10;++a){
48.m+=a.tostring();
49.continue label;
50.}
51.这里label就是一个首代码;
52.然后每个代码段对应的代码就是从首代码开始,到下一条首代码之前一句代码为止之间的所有代码;
53.这样,将java代码分为一个个代码段;
54.步骤2、按照java代码段的执行顺序,取出java代码段,判断取出的每个java代码
段是否为迭代逻辑,所述java代码段若是迭代逻辑,将java代码段转换为mapreduce代码,利用全新api函数进行编译,得到执行结果,
55.全新api函数至少包括以下功能:申请新的缓存空间,建立新的控制模块,缓存中间结果、缓存循环不变量、新的控制模块重启;
56.所述全新api函数为:
57.主节点新建一个job控制模块,该job控制模块不断的启用map-reduce过程来实现mapreduce代码的迭代逻辑;这样,相当于一个job控制模块中有多个map-reduce对,十分高效,传统方法是建立多个job控制模块,每个job控制模块对应一个map-reduce对,job控制模块之间进行数据通讯,i/o多,效率低;
58.用户定义循环不变量,用户指定哪些数据是不变的,哪些数据是会发生变化的,主节点申请缓存空间,用来存储用户定义的循环不变量及每次mapper和reducer的输入输出缓存,并建立索引,便于重复使用数据;job控制模块进行多个map-reduce过程中,根据索引从缓存空间中取出需要的数据;这里相比较于spark来说,可缓存的数据更灵活,不用像rdd一样只能读,并且对于每一轮迭代mapper之间的数据通信在一个job中,根本上解决i/o多的问题。进行map-reduce过程,一个job控制模块中可以进行多个map-reduce过程,其中需要访问的数据都是从缓存中读取的,可以是缓存的之前reducer的输出,也可以是循环不变量等等,这样减少i/o,效率更高,中间数据的比较也更方便。
59.当迭代满足终止条件,结束迭代,获得mapreduce代码的执行结果,作为下一个代码段的输入;
60.所述java代码段若不是迭代逻辑,将java代码段转换为mapreduce代码,利用已有大数据框架的api进行编译该mapreduce代码,获得的执行结果作为下一个代码段的输入。
61.和现有的大数据处理框架不同的是,本实施方式可以直接以java代码为输入,而不用编写mapreduce代码,本实施方式可以将java代码转化为同逻辑的mapreduce代码,后续用现有的大数据处理框架(以mapreduce代码为输入)进行处理。本实施方式针对于迭代逻辑,进行了特殊优化,设计了一套新的api,专门用于处理迭代逻辑,减少i/o次数,效率更高效。
62.本实施方式中,迭代终止情况的判断,可以是比较两次迭代是否相等,如果相等,自动结束迭代,如果用户有输入最大迭代次数,那么就按照最大迭代次数来判断终止条件。
63.本实施方式中,将java代码段转换为mapreduce代码的方法,包括:
64.将java代码段转换为中间代码,并将中间代码进行摘要,这里摘要就是指将中间代码进行进一步概括提取,搜索与摘要相类似表述的api函数,利用api函数将摘要转换成mapreduce码。
65.本实施方式在每一步转换完,设置检查程序,也就是设置输入,java代码编译一遍,再调用转换后的mapreduce代码编译一遍,获得结果,如果结果相同,证明mapreduce代码转换成功,否则,更换api函数,一个摘要对应的api函数可能有很多种,一种不对,那么就试另一种,重新将摘要转换成mapreduce码。
66.针对java代码段若不是迭代逻辑,可以采用不同的框架来进行处理,例如hadoop,spark等,只要获取到输出作为执行后续代码段的输入即可。
67.本实施方式还包括一种基于mapreduce的大数据处理系统,包括:
68.拆分模块,用于输入java代码,将java代码分成java代码段,按照java代码段的执行顺序,取出java代码段;
69.处理模块,用于判断取出的每个java代码段是否为迭代逻辑,所述java代码段若是迭代逻辑,将java代码段转换为mapreduce代码,利用全新应用程序编程接口模块进行编译,得到执行结果,当迭代满足终止条件,结束迭代,获得mapreduce代码的执行结果,作为下一个代码段的输入;所述java代码段若不是迭代逻辑,将java代码段转换为mapreduce代码,利用已有mapreduce模块进行编译该mapreduce代码,获得的执行结果作为下一个代码段的输入;
70.全新应用程序编程接口模块包括job控制模块和缓存模块;
71.job控制模块,用于不断的启用map-reduce过程来实现mapreduce代码的迭代逻辑,获得执行结果;
72.缓存模块,与job控制模块连接,用于存储用户定义的循环不变量及每次mapper和reducer的输入输出缓存,并建立索引;job控制模块在进行多个map-reduce过程中,根据索引从缓存空间中取出需要的数据。
73.本实施方式中,处理模块采用编译器将java代码段转换为mapreduce代码,所述编译器用于将java代码段转换为中间代码,并将中间代码进行摘要,搜索与摘要相类似表述的应用程序编程接口模块,利用该应用程序编程接口模块将摘要转换成mapreduce码。
74.本实施方式中,编译器,还用于将java代码段和转换的mapreduce码进行编译获得结果,如果结果相同,证明mapreduce代码转换成功,否则,更换应用程序编程接口模块,重新将摘要转换成mapreduce码。
75.本实施方式中,所述mapreduce模块为基于hadoop的mapreduce模块或基于spark的mapreduce模块。
76.虽然在本文中参照了特定的实施方式来描述本发明,但是应该理解的是,这些实施例仅仅是本发明的原理和应用的示例。因此应该理解的是,可以对示例性的实施例进行许多修改,并且可以设计出其他的布置,只要不偏离所附权利要求所限定的本发明的精神和范围。应该理解的是,可以通过不同于原始权利要求所描述的方式来结合不同的从属权利要求和本文中所述的特征。还可以理解的是,结合单独实施例所描述的特征可以使用在其他所述实施例中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1