一种基于存内计算的稀疏矩阵稠密乘法加速器
本发明涉及存内计算领域,具体来说,涉及一种基于存内计算的稀疏矩阵稠密乘法加速器。
背景技术:
1、稀疏矩阵稠密向量乘法(sparse matrix-dense vector multiplication,spmv)是一个基本的线性代数内核,也是一个重要的计算原语。它在多种应用中被使用,例如科学计算和图形处理。由于较差的数据局部性和不规则的内存访问,传统spmv加速器的性能通常受到内存的限制。存内计算(in-memory computing,imc)被视为缓解内存瓶颈的一种很有前途的技术。然而现存的基于存内计算的spmv加速器存在一些缺陷,使得他们难以很好地支持对spmv的加速。
2、现有的基于存内计算技术的稀疏矩阵稠密向量乘法加速器主要包括以下两种:
3、方案一:以参考文献[1]为代表的方案则是使用基于电阻式随机存取存储器(resistive random-access memory,reram)的内存存储参与乘法计算的稀疏矩阵数据。随后使用内存可寻址存储器(content addressable memory,cam)阵列完成索引匹配,将匹配的稀疏矩阵数据从内存中读出然后使用靠近内存的浮点乘法器来完成spmv计算[1]。
4、方案二:以参考文献[2]为代表的方案则是使用基于reram的乘加(multiply-addcomputation,mac)阵列存储稀疏矩阵数据,根据稀疏矩阵数据的指数范围决定使用的mac阵列的尺寸,将稠密向量输入到mac阵列中与存储的稀疏矩阵数据进行spmv运算。
5、对于第一种方案,其使用的reram阵列不支持浮点表示和计算,乘法计算是使用浮点乘法器完成的,而不是使用具有高并行度的mac阵列。这样需要执行额外的数据读取,不能充分利用存内计算技术的优势,难以取得较好的性能和能量利用效率,此外浮点乘法器的使用会带来额外的面积和功耗。对于第二种方案,其使用的基于reram的mac阵列完成spmv运算,采用的定点乘法运算,且其阵列使用稠密格式存储数据,不支持使用稀疏格式存储,因此会存储许多零元数据,带来额外的内存面积开销。此外,其方案根据指数范围选择使用的mac阵列的尺寸,在局部稀疏矩阵数据指数范围变化大时,无法选择合适尺寸的mac阵列存储数据,这些无法存储和计算的数据需要交给gpu处理,会显著降低该加速器的加速效果。因此,现有技术中存在不支持存内浮点计算和不支持稀疏存储格式的缺陷,导致加速器存在计算效率低且内存面积开销大的问题。
6、参考文献:
7、[1]l.yavits and r.ginosar,“sparse matrix multiplication on cam basedaccelerator,”arxiv preprint arxiv:1705.09937,2017.
8、[2]b.feinberg,u.k.r.vengalam,n.whitehair,s.wang,and e.ipek,“enablingscientific computing on memristive accelerators,”in 2018acm/ieee 45th annualinternational symposium on computer architecture(isca),2018,pp.367-382.
技术实现思路
1、因此,本发明的目的在于克服上述现有技术的缺陷,提供一种基于存内计算的稀疏矩阵稠密乘法加速器。
2、本发明的目的是通过以下技术方案实现的:
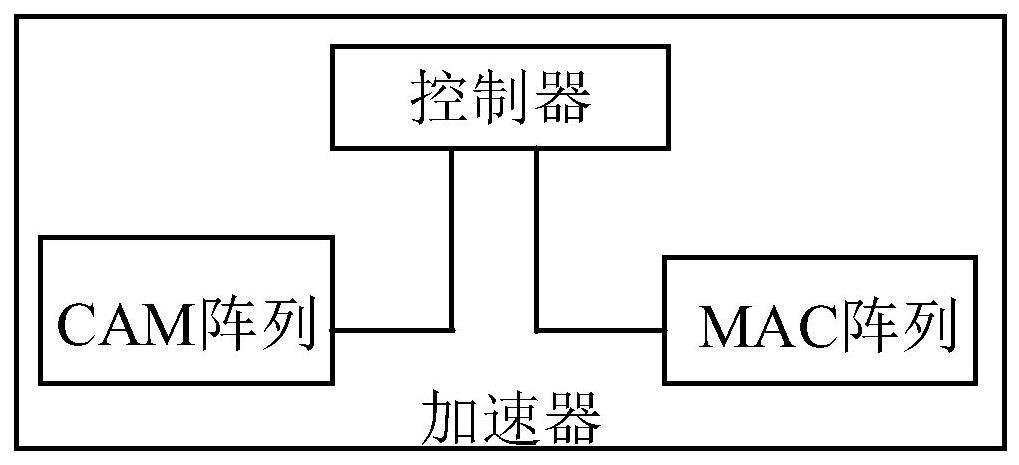
3、在本发明的第一方面,提供一种基于存内计算的稀疏矩阵稠密乘法加速器,所述加速器包括:控制器,用于根据当前的计算任务,确定其中稀疏矩阵的所有非零数值、稠密向量的所有非零数值、稀疏矩阵和稠密向量的每个非零数值对应的行索引值和列索引值,且非零数值为浮点数值;cam阵列,用于存储稀疏矩阵的每个非零数值对应的行索引值和列索引值,根据稠密向量的每个非零数值的行索引值匹配需与之进行计算的稀疏矩阵的每个非零数值的列索引值和行索引值,得到匹配结果;mac阵列,用于根据cam阵列的匹配结果关联存储稀疏矩阵的每个非零数值和稠密向量的每个非零数值,并执行关联存储的稀疏矩阵的每个非零数值与稠密向量对应的非零数值间的浮点乘法计算,得到计算结果。
4、在本发明的一些实施例中,所述匹配结果包括与稠密向量对应行的非零数值进行计算的稀疏矩阵对应列的所有非零数值的第一匹配结果,mac阵列按以下方式执行浮点乘法计算:根据cam阵列的第一匹配结果在mac阵列的每行中关联存储稀疏矩阵的一个非零数值和与该数值进行计算的稠密向量对应的一个非零数值;按预设规则将mac阵列的每行中关联存储的稀疏矩阵的非零数值与稠密向量对应的非零数值进行浮点乘法计算,得到mac阵列的每行的计算结果。
5、在本发明的一些实施例中,所述稀疏矩阵和稠密向量的每个非零数值包括指数和尾数,所述mac阵列的每行中包括多个fefet晶体管,每个fefet晶体管存储稀疏矩阵的非零数值的尾数的一位二进制数值,其中,按以下方式得到每行的计算结果:将每行中关联存储的稀疏矩阵的非零数值的指数与稠密向量对应的非零数值的指数相加,得到总指数值;将对应行关联存储的稠密向量的非零数值的尾数的每位二进制数值按位将对应位的二进制数值输入到该行的每个fefet晶体管中,每个fefet晶体管执行输入二进制数值与其存储的二进制数值间的乘法计算,以得到该行的尾数计算结果;根据每行的总指数值和尾数计算结果得到每行的计算结果。
6、在本发明的一些实施例中,所述每个fefet晶体管按以下方式执行输入二进制数值与其存储的二进制数值间的乘法计算:每个fefet晶体管根据输入为零的二进制数值与其存储的二进制数值间的乘法计算得到尾数计算结果的相应位为零,根据输入为一的二进制数值与其存储的二进制数值间的乘法计算得到尾数计算结果的相应位为其存储的二进制数值。
7、在本发明的一些实施例中,所述mac阵列包括由多个寄存器构成的寄存器堆和第一交叉开关矩阵,第一交叉开关矩阵的每行对应一个寄存器,通过第一交叉开关矩阵的每行和其对应的寄存器关联存储稀疏矩阵的非零数值和与该数值进行计算的稠密向量对应的非零数值,其中,按照以下方式进行关联存储:通过第一交叉开关矩阵在所述矩阵的每行中存储稀疏矩阵的非零数值的尾数,其中,mac阵列每行中的多个fefet晶体管设置在第一交叉开关矩阵的每行中用于存储尾数的相应位的二进制数值;通过寄存器堆在稀疏矩阵的非零数值的尾数所在的行对应的寄存器中存储该稀疏矩阵的非零数值的指数、与该稀疏矩阵的非零数值进行计算的稠密向量的非零数值的指数和尾数。
8、在本发明的一些实施例中,所述mac阵列按以下方式得到最终计算结果:按确定搜索的行索引值从小到大的顺序依次匹配cam阵列中存储的与之相等的行索引值,得到与稀疏矩阵对应行的所有非零数值进行计算的稠密向量对应的非零数值的第二匹配结果;根据第二匹配结果将稀疏矩阵的对应行中所有非零数值与对应非零数值关联存储的稠密向量的非零数值进行乘法计算,得到稀疏矩阵的对应行对应的乘法结果;根据稀疏矩阵的对应行中所有非零数值的指数和与对应非零数值进行浮点乘法计算的稠密向量的非零数值的指数,对稀疏矩阵的对应行中对应的乘法结果进行浮点乘加,得到稀疏矩阵的对应行的乘加结果;根据稀疏矩阵的所有行对应的乘加结果得到最终计算结果。
9、在本发明的一些实施例中,所述mac阵列包括寻找最大值电路、延迟电路、数模转换器、采样保持电路、模数转换器和移位累加电路,其中,寻找最大值电路对每个寄存器存储的稀疏矩阵的非零数值的指数和稠密向量的非零数值的指数进行求和,得到每个寄存器对应的总指数值,并按照以下方式得到稀疏矩阵的对应行的乘加结果:通过寻找最大值电路根据稀疏矩阵的对应行中的所有非零数值以及每个非零数值对应的总指数值,得到最大的总指数值,计算所述对应行中的每个非零数值对应的总指数值与最大的总指数值间的差值;通过延迟电路根据稀疏矩阵的对应行中的每个非零数值对应的差值,得到稀疏矩阵的对应行中的每个非零数值延迟计算的时钟周期;通过数模转换器将与稀疏矩阵的对应行中的每个非零数值关联存储的稠密向量的对应非零数值的尾数延迟对应时钟周期输入第二交叉开关矩阵中,以与稀疏矩阵的对应行中的对应非零数值进行乘法计算,得到对应时钟周期的计算结果;通过采样保持电路获取并保存每个时钟周期的计算结果;通过模数转换器将每个时钟周期的计算结果转换为数字信号;通过移位累加电路将每个时钟周期的数字信号进行移位累加,并结合最大的总指数值,得到稀疏矩阵的对应行的乘加结果。
10、在本发明的一些实施例中,所述第一交叉开关矩阵包括第一存储器阵列、与第一存储器阵列连接的第一驱动电路,第一存储器阵列每行包括多个第一存储器,mac阵列每行中的每个fefet晶体管设置在该行对应的第一存储器中,所述第一存储器还包括存取晶体管,存取晶体管漏极与fefet晶体管的源极连接,所述第一驱动电路包括与存取晶体管的源极和栅极分别连接的位线驱动电路和第一字线驱动电路,其中,第一交叉开关矩阵按照以下方式存储非零数值的尾数:打开与相应行的存取晶体管的栅极连接的第一字线驱动电路,使存取晶体管的栅极和源极形成电压差后,利用源极连接的位线驱动电路输送的稀疏矩阵的非零数值的尾数的相应位的二进制数值到该行存取晶体管;存取晶体管通过其漏极将接收的二进制数值输入与该存取晶体管连接的fefet晶体管中,以存储非零数值的尾数的一位二进制数值。
11、在本发明的一些实施例中,所述第一交叉开关矩阵包括与第一存储器阵列连接的感应电路,所述第一驱动电路包括第一数据线驱动电路,fefet晶体管的栅极和漏极分别连接第一数据线驱动电路和感应电路,其中,第一交叉开关矩阵按照以下方式存执行乘法计算:fefet晶体管接收其栅极连接的第一数据线驱动电路输送的与稀疏矩阵的非零数值关联存储的稠密向量的非零数值尾数的二进制数值,将接收的二进制数值与其存储的二进制数值进行乘法计算,得到尾数计算结果的相应位的二进制数值并通过该fefet晶体管漏极连接的感应电路输出。
12、在本发明的一些实施例中,所述cam阵列按以下方式得到匹配结果:根据稠密向量的每个非零数值的行索引值匹配与之相等的稀疏矩阵的每个非零数值的列索引值,得到需与稠密向量对应行的非零数值进行计算的稀疏矩阵对应列的所有非零数值的第一匹配结果,以根据第一匹配结果关联存储稀疏矩阵的每个非零数值和稠密向量的每个非零数值;根据确定搜索的行索引值匹配与之相等的稀疏矩阵的每个非零数值的行索引值,得到与稀疏矩阵对应行的所有非零数值进行计算的稠密向量对应的非零数值的第二匹配结果,以根据第二匹配结果执行关联存储的稀疏矩阵的每个非零数值与稠密向量对应的非零数值间的浮点乘法计算。
13、在本发明的一些实施例中,所述cam阵列包括第二交叉开关矩阵,第二交叉开关矩阵包括第二存储器阵列、与该阵列连接的第二驱动电路,第二存储器阵列每行包括多个第二存储器,每个第二存储器包括两个存储单元,其中,cam阵列按以下方式存储稀疏矩阵的每个非零数值的行索引值和列索引值:按行索引值从小到大的顺序,通过第二驱动电路将稀疏矩阵的非零数值的行索引值、该行索引值的取反值、列索引值和该列索引值的取反值写入第二存储器阵列的相应行中;其中,第二存储器阵列的每行存储一个非零数值的行索引值、该行索引值的取反值、列索引值和该列索引值的取反值,每个第二存储器的两个存储单元分别用于存储行索引值或列索引值的相应位对应的二进制数值和该二进制数值的取反值。
14、在本发明的一些实施例中,所述第二交叉开关矩阵还包括与第二存储器阵列连接的cam灵敏放大器电路,每个存储单元包括用于存储行索引值或列索引值的相应位的二进制数值或存储该二进制数值的取反值的fefet晶体管以及与第二驱动电路连接的存取晶体管,存取晶体管漏极与fefet晶体管栅极连接,fefet晶体管的源极连接cam灵敏放大器电路,其中,第二交叉开关矩阵按以下方式匹配与之相等的稀疏矩阵的非零数值的列索引值包括:以稠密向量的每个非零数值的行索引值为搜索键值,通过第二驱动电路将对应搜索键值及该搜索键值的取反值输入第二存储器阵列的存取晶体管中;利用第二存储器阵列中的fefet晶体管根据该搜索键值及其取反值与其存储的每个列索引值及其取反值进行同或运算,得到同或运算结果;通过cam灵敏放大器电路根据同或运算结果确定搜索键值与cam阵列中存储的列索引值是否相等,以得到与该搜索键值相等的稀疏矩阵的非零数值的列索引值。
15、在本发明的第二方面,提供一种基于在本发明的第一方面所述加速器的spmv计算方法,包括:s1、通过控制器根据当前的计算任务,确定其中稀疏矩阵的所有非零数值、稠密向量的所有非零数值、稀疏矩阵和稠密向量的每个非零数值对应的行索引值和列索引值,且非零数值为浮点数值;s2、通过cam阵列存储稀疏矩阵的每个非零数值对应的行索引值和列索引值,根据稠密向量的每个非零数值的行索引值匹配需与之进行计算的稀疏矩阵的每个非零数值的列索引值和行索引值,得到匹配结果;s3、通过mac阵列根据cam阵列的匹配结果关联存储稀疏矩阵的每个非零数值和稠密向量的每个非零数值,并执行关联存储的稀疏矩阵的每个非零数值与稠密向量对应的非零数值间的浮点乘法计算,得到计算结果
16、与现有技术相比,本发明的优点在于:
17、本发明的加速器首先只存储稀疏矩阵和稠密向量的非零数值以及非零数值对应的行索引值和列索引值,不存储值为零的数值,极大地减少了内存面积开销,其次,加速器中设置的mac阵列根据cam阵列的匹配结果关联存储稀疏矩阵的每个非零数值和稠密向量的每个非零数值,使稠密向量的每个非零数值和与之进行计算的稀疏矩阵的非零数据关联对齐,提高后续稀疏矩阵和稠密向量间的计算效率,最后,在进行浮点乘法计算时,可支持存内浮点计算,即直接在mac阵列内执行稀疏矩阵与稠密向量间的浮点计算,进一步提高加速器的计算效率。且本发明不需要gpu或是其他处理器的协助,可以独立的完成浮点计算,提高加速器的性能。
- 还没有人留言评论。精彩留言会获得点赞!