一种基于目标损失函数的检索引擎排序系统及方法与流程
1.本发明涉及互联网检索领域,具体涉及一种基于目标损失函数的检索引擎排序系统及方法。
背景技术:
2.通过在全国企业工商信息检索系统中进行企业相关信息的查询检索,用以帮助用户快速掌握所需的企业公开信息从而满足用户的商业需求,但是,现有的全国企业工商信息检索系统中存在的问题在于,用户在输入待检索数据后产生的检索结果数量较多,其中所述检索结果虽然与用户输入的待检索数据的相似度较高,但是与用户输入的待检索数据的一致性较差,从而导致用户无法从大量的相似词条中找到自己真正需要的数据信息,同时由于词条与词条之间的相似度较高,反而加重了用户的查询分析任务,降低了用户的检索效率。
3.公开号为cn106446013a的中国专利,提供了一种应用于海量数据全文检索系统的测试工具及测试方法,此发明中通过建立多种性能测试方式,用以进行非结构化的数据查询。但是此发明中所述全文检索的方式为遍历检索的方式,虽测试方式不同可适用于不同的非结构数据,但是整体的检索方式不变从而导致检索效率交底,无法真正适用与海量数据的查询。公开号为cn106021276a的专利发明,提供了一种基于分布式全文检索系统的卡口车辆检索的方法及系统,此发明也建立了基于分布式检索下的倒排索引方式进行卡车图片的识别,但是此发明与本发明的不同之处在于,此发明中所述卡车图片识别不存在为点对点识别,不存在数据识别中的相似度与一致性识别的问题,因此在识别过程中无需再次进行检索数据的筛选与检索数据的精细化处理,因此无法解决本发明中的所述技术问题。
4.因此,针对现有的数据检索系统中存在的问题,本发明中提供了一种基于目标损失函数的检索引擎排序系统及方法。
技术实现要素:
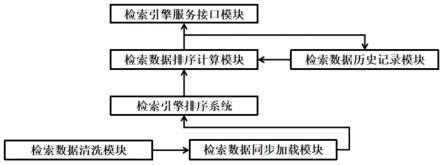
5.针对上述存在的问题,本发明中提供了一种基于目标损失函数的检索引擎排序系统及方法,具体包括检索数据清洗模块,检索数据同步加载模块,检索数据排序计算模块,检索数据历史记录模块与检索引擎服务接口模块。
6.第一方面,本实施例中提供了一种基于目标损失函数的检索引擎排序系统,其中在所述检索数据清洗模块,检索数据同步加载模块中进行数据初筛,在所述检索数据排序计算模块,检索数据历史记录模块进行数据二次检索,并见最终检索数据通过检索引擎服务接口模块输出。
7.优选的,所述检索数据清洗模块,将待检索数据以及与待检索数据匹配的字段分别整理为结构化表单,其中所述待检索数据匹配的字段包括待检索数据属性特征匹配。
8.优选的,所述检索数据同步加载模块,将检索数据清洗模块中的待检索数据发送至总节点上,通过总节点将检索请求转发至各节点单元中,将各节点单元中的数据初筛结
果返回至总节点,由总节点将数据初筛结果传送至检索数据排序计算模块中进行数据二次检索。
9.优选的,所述各节点单元中,将各节点单元分为主节点与分节点,其中所述分节点用以进行主节点备份处理.
10.优选的,所述各节点单元中,采用模糊检索方式进行反向索引,并采用并行检索的结构进行各节点单元中不同数据分别检索。
11.优选的,所述检索引擎服务接口模块,建立了检索引擎排序系统查询用的微服务api接口。
12.第二方面,本实施例中提供了一种基于目标损失函数的检索引擎排序方法,其具体流程为:
13.s1、所述检索数据清洗模块将待检索数据传送至检索数据同步加载模块中,并使用elasticsearch检索引擎对待检索数据进行数据初筛;
14.s2、待数据初筛后在检索数据排序计算模块中进行数据二次检索;
15.s3、待数据二次检索后在检索数据历史记录模块使用检索历史记录数据对二次检索数据进行循环筛选;
16.s4、将循环筛选后的最终检索数据传送至检索引擎服务接口模块中作为检索结果输出。
17.优选的,所述检索数据排序计算模块中,建立了基于损失函数计算的自定义检索相似度评分计算,用以对数据初筛结果进行相似度排序计算。
18.优选的,所述检索数据历史记录模块中,在所述相似度排序计算的基础上,使用用户历史检索记录作为数据初筛结果的一致性评估因素,用以在用户多次检索过程中完善待检索数据检索精确度。
19.与现有技术相比,本发明的有益效果在于:
20.(1)本发明中所述基于目标损失函数的检索引擎排序系统,通过对待检索数据进行多次检索筛查,用以提升待检索数据的检索精确度,在进行其企业工商信息检索过程中,进一步提高用户在进行企业公开信息查询过程中的查询匹配精度,同时在检索数据清洗模块与检索数据同步加载模块中通过对待检索数据进行基于清洗与匹配的结构化处理,用以提高用户数据检索的效率。
21.(2)在(1)的基础上,本发现通过将检索数据排序计算模块与检索数据历史记录模块相互结合,用以将用户的真实检索需求作用评估标准进行待检索数据的筛选中,从而进一步提高数据检索的有效性与一致性,使得最终呈现的检索结果更加符合用户的检索预期,并利用用户的检索历史记录,对最终检索数据进行精准排序操作,用以进一步提升检索引擎排序系统的体验和易用度,在实际的应用中,本发明中所述检索引擎排序系统用以进一步促进用户的使用效果,做到90%以上的检索结果在top5范围内,另外通过改进检索引擎,对用户商务的转化率提升20%。
附图说明
22.图1为基于目标损失函数的检索引擎排序系统模块图。
具体实施方式
23.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
24.在本发明的描述中,需要说明的是,术语“上”、“下”、“内”、“外”“前端”、“后端”、“两端”、“一端”、“另一端”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性。
25.在本发明的描述中,需要说明的是,除非另有明确的规定和限定,术语“安装”、“设置有”、“连接”等,应做广义理解,例如“连接”,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以具体情况理解上述术语在本发明中的具体含义。
26.第一方面,本发明提供一种基于目标损失函数的检索引擎排序系统,如图1所示,具体包括检索数据清洗模块,检索数据同步加载模块,检索数据排序计算模块,检索数据历史记录模块与检索引擎服务接口模块;其中在所述检索数据清洗模块,检索数据同步加载模块中进行数据初筛,在所述检索数据排序计算模块,检索数据历史记录模块进行数据二次检索,并见最终检索数据通过检索引擎服务接口模块输出。
27.具体的,所述检索数据清洗模块,将待检索数据以及与待检索数据匹配的字段分别整理为结构化表单,其中所述待检索数据匹配的字段包括待检索数据属性特征匹配。
28.所述检索数据同步加载模块,将检索数据清洗模块中的待检索数据发送至总节点上,通过总节点将检索请求转发至各节点单元中,将各节点单元中的数据初筛结果返回至总节点,由总节点将数据初筛结果传送至检索数据排序计算模块中进行数据二次检索,所述各节点单元中,将各节点单元分为主节点与分节点,其中所述分节点用以进行主节点备份处理,所述各节点单元中,采用模糊检索方式进行反向索引,并采用并行检索的结构进行各节点单元中不同数据分别检索。
29.所述检索数据排序计算模块,建立了基于损失函数计算的自定义检索相似度评分计算,用以对数据初筛结果进行相似度排序计算。
30.其中,所述基于损失函数计算的自定义检索相似度评分计算中,所述损失函数计算公式为:
31.其中,l为数据初筛结果结构化表单,p为数据初筛结果以外筛选出的数据集合并将其定义为p集合,n为数据初筛结化表单中数据集合并将其定义为n集合,si与sj为两个检索数据样本,通过损失函数计算公式用以计算si与sj为两个检索数据样本之间的在数据具有相似性的基础上数据与数据之间的一致性判断。
32.所述检索数据历史记录模块,在所述相似度排序计算的基础上,使用用户历史检索记录作为数据初筛结果的一致性评估因素,用以在用户多次检索过程中完善待检索数据
检索精确度。
33.所述检索引擎服务接口模块,所述检索引擎服务接口模块,建立了检索引擎排序系统查询用的微服务api接口。
34.其中,所述待检索数据包括但是不限制于企业名称、社会统一信用代码、股票简称、股票代码、产品名称、企业状态、企业类型、企业成立时间、企业注册资金、企业行业分类、企业注册省份、点击数量、数据更新时间的检索字段。
35.第二方面,本发明提供一种基于目标损失函数的检索引擎排序方法。
36.在一种实施方式中,所述基于目标损失函数的检索引擎排序方法的具体流程为:
37.s1、所述检索数据清洗模块将待检索数据传送至检索数据同步加载模块中,并使用elasticsearch检索引擎对待检索数据进行数据初筛;
38.s2、待数据初筛后在检索数据排序计算模块中进行数据二次检索;其中所述数据二次检索中,根据p集合与n集合共同在数据排序计算模块中组成数据列表,在所述数据列表中对p集合与n集合进行排序并将p集合排列于n集合之前构建目标损失函数模型,并对目标损失函数模型进行最大值函数近似处理得到:当时,可将目标损失函数模型简化为以此通过拉大样本之间的差异值进行检索数据的排序计算,在进行数据的排序计算的过程中,通过剔除出当前样本si外的所有样本数据;
39.s3、待数据二次检索后在检索数据历史记录模块使用检索历史记录数据对二次检索数据进行循环筛选;其中,所述检索数据历史记录模块中,根据用户的历史检索记录分析用户的实际需求,根据用户的实际需求确定对应的数据初筛结果的动态权重,所述用户的历史检索记录包括但是不限制于用户检索历史、点击历史、用户所在区域,在符合检索结构的条件中,如果用户曾经检索过、点击过数据词条其排名将更高。
40.s4、将循环筛选后的最终检索数据传送至检索引擎服务接口模块中作为检索结果输出;其中,在所述检索数据排序计算模块中通过分析用户检索意图,将数据初筛结果中的企业名称、企业类型、企业状态、企业成立时间、企业注册资金、检索用户的自身评价数据进行权重排名,所述自身评价属性包括但是不限制于企业所在省份,检索时间,以及指定检索时间下的相关政策变化,并根据权重排名计算数据初筛结果中检索数据的相似度排序计算,所述企业类型包括但是不限制于企业与个人,所述企业状态包括但是不限制于在营、注销、吊销状态。
41.以上所述,仅是本发明的较佳实施例而已,并非是对发明作其他形式的限制,任何熟悉本专业的技术人员可能利用上述揭示的技术内容加以变更或更改为等同变化的等效实施例,但是凡是未脱离本发明技术方案内容,依据本发明的技术实质对以上实施例所作的任何简单修改,等同变化与改型,仍属于本发明技术方案的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1