一种自然语言转换为SQL语句的方法及系统与流程
一种自然语言转换为sql语句的方法及系统
技术领域
1.本发明属于自然语言处理的技术领域,特别涉及一种自然语言转换为sql语句的方法及系统。
背景技术:
2.在大数据时代,每天都有大量的数据产生,对数据查询的需求量也水涨船高。由于数据库对数据存储的要求,使得大量存储在数据库中的数据,必须使用sql语句才能进行查询。
3.然而,大众对sql语句的了解并没有被广范围的普及,因此对数据库中的数据查询需要专业的技术人员来执行这一操作,导致一般用户存在使用上的障碍。
技术实现要素:
4.发明目的:提出一种自然语言转换为sql语句的方法及系统,以解决现有技术存在的上述问题。通过将自然语言转换为数据库可识别的sql语句,可以大大简化用户的使用难度,降低数据使用门槛。
5.技术方案:第一方面,提出一种自然语言转换为sql语句的方法,该方法具体包括两个过程:文本数据的分类和文本语义流的形成。
6.在文本数据的分类过程中,首先对自然语言描述的文本数据进行分词,并根据词性划分实词和虚词;随后,根据分类需求,将实词分类为数据库中数据表对应的标签类;将虚词分类为对应的关系类;将未被分为标签类和关系类的词,分类为数值类。
7.在文本语义流的形成过程中,针对文本语义流的生成流程,基于文本数据分类过程中获得的分类结果,将文本数据梳理成关系流程后,基于关系流程构建sql语句。
8.在第一方面的一些可实现方式中,执行分类的过程中,通过构建标签判断模型、关系判断模型和数值判断模型对分词结果进行标签类、关系类和数值类的划分。
9.由于实词与便签之间的联系为词义联系,与上下文关联不密切,因此标签判断模型采用bert模型进行分析,将两个词组合,并对结合结果进行判断,获得词语与标签是否关联的结果。
10.由于sql语句中存在的关系是固定的,因此关系判断模型采用线性分类网络,将经过向量化的虚词输入线性神经网络,实现关系的分类。
11.在完成标签类和关系类分类后,将剩余词设为值,由于sql语句具备统一的数据形式,因此需要将值转换为标准形式,将值进一步采用划分为时间、字符串、数字等等。当前的分类过程中,数值判断模型采用与分类二相类似的结构,进行分类。分类完成后,通过预设规则进行转化,如字符串和数字可以直接取值,时间转化为对应的日期格式等。
12.在第一方面的一些可实现方式中,执行文本语义流形成的过程中,基于文本数据分类过程中获得的分类结果,得到由标签、关系和值三个元素构成的三元组,并采用箭头描述元素之间的关系。随后,构建判别模型,通过遍历的方式读取所有三元组中的数据,并对
三元组与文本的拼接结果进行筛选分析,获得贴合实际的三元组。最后,对获取到的各个三元组执行关联关系进行确认,获取各个三元组在sql语句中的对应位置,以及逻辑关系,基于确认的结果构建sql语句。
13.其中,筛选三元组的过程中,判别模型采用双向gru模型进行筛选分析,具体的包括以下步骤:
14.s1、针对三元组中的各个元素,采用箭头的方式进行关系描述;
15.s2、将文本数据中的整个句子与标签、关系、值相结合;
16.s3、利用双向gru模型对结合后的数据进行分析,输出对标签,关系与值的预测分数;
17.s4、将预测分数最高的作为当前关系的代表,并将此时的三元组作为被正确筛选出的三元组。
18.在完成对标签与关系的连接之后,还需要区分三元组中哪些是约束类型,哪些是选择类型,同时分析两个三元组之间是否存在逻辑关系。具体的,将两个向量化的标签结合句子语义向量,输入bert后再经过线性神经网络,进行分类,得出a约束b,b约束a,或无关三种结果之一。然后进行并列关系判断,并在完成后,合并“与”、“或”关系,生成sql语句。
19.第二方面,提出一种自然语言转换为sql语句的系统,用于实现自然语言转换为sql语句的方法,该系统包括:用于读取待分析自然语言文本数据的数据读取模块;用于执行文本分词和词性判断的分词模块;用于构建符合分析需求的模型构建模块;用于执行分词结果分类的分类模块;用于对数据进行分词获得sql组成元素的数据分析模块;用于构建sql语句的sql语句构建模块。
20.在第二方面的一些可实现方式中,模型构建模块构建的模型包括:标签判断模型、关系判断模型、数值判断模型、判别模型。
21.分词模块包括分词模型,用于对读取到的文本数据进行分词,同时执行实词与虚词的词性判断,并将词性判断结果送入分类模型中。分类模块利用模型构建模块构建的模型对分词结果进行分类,将实词送入标签判断模型中,判断是否是标签类;将虚词送入关系判断模型中,判断是否是关系类;将不属于实词或虚词的词送入数值判断模型中,判断是否是数值类。数据分析模块根据分类模型的分类结果,从标签类、关系类、数值类中各取一个进行拼接,获得三元组,并通过排列组合的方式,得到所有的三元组。将三元组与文本进行拼接,输入判别模型中,进而通过筛选获得贴合实际的三元组。随后,通过遍历的方式,继续从分类结果中读取分类数据,进行拼接、筛选,当所有正确三元组被筛选出时,结果当前的分析过程。sql语句构建模块对数据分析模块输出的三元组进行位置判断,通过结合文本语句的方式,判断各个三元组在sql语句中的对应位置,以及逻辑关系,并根据判断结果,构建符合数据库识别的sql语句。
22.有益效果:本发明提出了一种自然语言转换为sql语句的方法及系统,通过将文本分词与分类等算法结合三元组关系映射的方式,将自然语言转换为数据库可识别的sql语句,在提高转化准确的同时,大大简化用户的使用难度,降低数据使用门槛。
23.同时,本发明在整个分词过程中,总共执行了标签分类,关系分类,词语关系判断,标签关系判断,同级标签关系判断,共5个过程,并且用了5个相关的深度学习模型。其中,使用的bert模型,有较高准确率,可以基本保证准确率不会因为过多模型的联接而下降。
24.另外,由于大量使用通用模型,且任务存在共通性,所以在经过大量各领域数据训练后,可以做到轻易迁移,若存在生僻数据,也仅需压重新训练bert模型后拼接的线性层,算力需求低,容易进行迁移。
附图说明
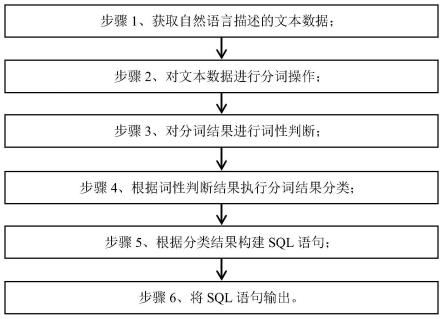
25.图1为本发明的数据处理流程图。
26.图2为本发明文本分类示意图。
27.图3为本发明构建sql语句流程图。
具体实施方式
28.在下文的描述中,给出了大量具体的细节以便提供对本发明更为彻底的理解。然而,对于本领域技术人员而言显而易见的是,本发明可以无需一个或多个这些细节而得以实施。在其他的例子中,为了避免与本发明发生混淆,对于本领域公知的一些技术特征未进行描述。
29.实施例一
30.在一个实施例中,针对用户对数据库中数据读取更加便捷的需求,提出一种自然语言转换为sql语句的方法,通过将自然语言转换为数据库可识别的sql语句,降低用户的使用难度,降低数据使用门槛。如图1所示,该方法具体包括以下步骤:
31.步骤1、获取自然语言描述的文本数据;该文本数据描述了一个从表格中筛选数据并进行简单分析的过程。
32.步骤2、利用分词模型对文本数据进行分词操作;
33.步骤3、对分词结果进行实词和虚词判断;
34.具体的,完成文本分词后,利用分词模型对分词结果进行词性的判断,初步划分为实词和虚词,将句子中的名词归类为实词,句子中的剩余部分归类为虚词。
35.步骤4、根据词性判断结果执行分词结果分类;
36.具体的,如图2所示,分类过程中根据分类需求,将分词结果划分为标签类、关系类和数值类。根据分词结果的词性判断结果,将实词分类为数据表对应的标签类,将虚词分类为对应的关系类,标签则对应具体的数值类。其中数据表是数据库中的基本单位,用于代表和存储数据对象之间的关系。
37.步骤5、根据分类结果构建sql语句;
38.具体的,在完成对分词后的词语性质分析后,实现sql语句的构建还需要明确词与词之间的关系。由于sql语句的构成包括标签、关系和值组成的三元组,因此,通过与文本内容进行对照,获取正确的三元组。
39.获取词与词之间关系的过程包括以下步骤:
40.步骤5.1、将获得的分类结果构成三元组;
41.步骤5.2、通过筛选获取正确的三元组;
42.步骤5.3、对各个三元组的关联关系进行确认;
43.步骤5.4、根据确认的关联关系获取sql语句的顺序关系;
44.步骤5.4、根据三元组中的元素和顺序关系,构建sql语句。
45.优选实施例中,从标签类、关系类和数值类中各读取一个进行拼接,并通过排列组合,形成各种可能的三元组。随后,将最开始读取的文本数据与三元组进行拼接,得到文本+[seq]+三元组的输入数据后,输入构建的判别模型,执行三元组的筛选,获得具备合理性的三元组。通过遍历的方式完成对所有三元组的筛选。将筛选后的三元组与语句结合,并判断各个三元组在sql语句中的对应位置,以及逻辑关系;最后根据判断结果构建sql语句。
[0046]
步骤6、将sql语句输出。
[0047]
实施例二
[0048]
在实施例一基础上的进一步实施例中,根据词性判断结果执行分词结果分类的过程中,根据词性划分结果,构建标签判断模型、关系判断模型和数值判断模型,将分词结果划分为标签类、关系类和数值类。
[0049]
由于实词与标签之间的联系为词义联系,与上下文关联不密切,所以本实施例利用bert模型,将两个词组合,判断是词语与标签是否关联。具体的,针对划分完的实词,将其与所查表的所有表头依次用分隔符拼接,得到“[cls]+文本+[sep]+实词+[sep]+表头”的数据,并输入训练好的bert模型中,随后,将[cls]标签的输出,输入到线性层中,利用二分类线性模型判断实词与表头之间是否关联,每个名词取关联性最大的表头为结果,进而获得每个名词对应的具体标签。
[0050]
在进一步的实施例中,有时也存在直接使用表内数值作为描述方式的情况,例如三元组的呈现形式为“(,关系,值)”,此时可根据表内容直接关联表头,且同时添加等于关系的判断。
[0051]
由于sql数据库中存在的关系是固定的,即》、《、=、或者特定函数,max、count等。因此本实施例利用线性分类网络,将经过向量化的虚词输入线性分类网络,从而实现关系的分类。优选实施例中,虚词作为sql语句中的关系判别词,由于sql语句的关系和函数有限,所以将判断过程转化为一个有限类别的分类问题。具体的,将词语输入bert模型中,随后bert模型的输出结果输入至一个更大线性分类模型,分类结果包括:等于,小于,小于等于,大于,大于等于,介于,选择,最大值,最小值,计数,求和,平均,非关系词一共13类,每个类别各自对应不同的运算符号和函数。其中,拼接的更大线性分类模型用于实现13种类别的分类。
[0052]
针对前序分类步骤后剩余的词,普遍为量词或时间等,例如五个、12:00等,本实施例将其认为是各个标签筛选需要的值,即将其设为值。由于需要将值转化为可以被sql数据库读取的标准形式,所以需要将值分类为时间,字符串,数字等格式。本实施例中数值判断模型采用与分类二相类似的结构,进行分类。优选实施例中,在分类完成后,可以通过规则进行转化,如字符串和数字可以直接取值,时间转化为对应的日期格式等。优选实施例中,在获取到值后,通过值的形式将其转化为数据表中格式,如五个转化为5;12:00转化为yyyy-mm-dd hh:mm:ss的格式等,方便以后续处理。
[0053]
在进一步的实施例中,在接受到文本进行分词时,会自动将双引号内容提出作为字符串标签的筛选值,不会将其放入标签判断模型和关系判断模型中进行分类。
[0054]
在进一步的实施例中,由于中文存在省略情况,存在有值但是文中没有出现对应标签的情况,在这种情况下,可以根据值的分类,直接对应到相应的标签下。若数据格式存在重复,则认定为存在歧义,进行反馈。
[0055]
实施例三
[0056]
在实施例一基础上的进一步实施例中,在完成文本数据的分类后,针对文本语义流的生成,将文本梳理成关系流程,利用流程构建sql语句。
[0057]
具体的,如图3所示,在完成标签、关系和数值的三种分类后,将语义划分为三类语义,用箭头的方式描述各分类单元间之间的关系。该过程使用双向gru模型,将整个句子与句中标签,关系,值相结合,作为输入,输出对该标签,关系与值的预测分数。针对每个关系,取包含该关系最大的预测分数作为该关系所代表。
[0058]
完成对标签与关系的链接之后,需要区分三元组哪些是约束类型,哪些是选择类型,同时分析两个三元组之间是否存在逻辑关系。将两个向量化的标签结合句子语义向量,输入bert模型后再经过线性神经网络,进行分类,得出a约束b,b约束a,或无关三种结果之一。然后进行并列关系判断,完成后合并“与”,“或”关系,生成sql语句。
[0059]
在进一步的实施例中,在完成文本数据的分类后,当前文本则被分为三类,由于sql语句中的各个部分,均是由已经分好的三类,标签、关系、值,各取其一构成的。因此通过将分类完成部分与待分析内容进行配对,获取正确的(标签,关系,值)三元组。由于该过程离不开对文本本身的理解,需要融合文本内容判断。因此,构造一个双向的gru模型,源文本在前,标签、关系、值组成的三元组再后,利用近似于语义相似度判断的方式,判断原文是否表达了于该三元组相同的含义。上述直接使用表内词语作为描述方式的,则不纳入三元组考量的范围中。
[0060]
在进一步的实施例中,由于选择关系是查询类sql语句中必须存在的函数,且可以同时选择多个标签,所以针对选择标签不采用上述利用近似于语义相似度判断的方式,判断原文是否表达了于该三元组相同含义的规则。若出现(标签,选择,)类三元组且该标签在其他三元组中可能性较低时,则设定为选择目标且从后续分类中移除。
[0061]
在进一步的实施例中,考虑到在语义表达中,可能省略标签,同时也存在一个值有多个关系分可能性,因此,以关系为(标签,关系,值)三元组的核心,同时创造空标签与空值,使标签,关系,值的数量相同。在分类完成后,可以存在(,关系,值)或(标签,关系,)的三元组,其中,后者中的关系多为sql中的函数表达,属于选择的目标。
[0062]
在进一步的实施例中,对于(,关系,值)的表达,多是由于中文文本省略某些词语造成的。例如,当查询“一周内xx发生的次数”时,无法直接判断“一周”所关联的表头,可以通过对这个词格式的判断,寻找格式同为“时间”的表头作为筛选项。如若表中存在“发生时间”这一标签,则可将该标签直接填入确实缺失位置。若出现标签格式内容重复,则认为原语句可能存在歧义,提示用户修改。
[0063]
在进一步的实施例中,在完成了语句将三元组关系的组合后,还要确定各个三元组的关联关系来确定sql语句的顺序,即哪些是where语句约束,哪些是需要select选取的部分。针对一个sql语句,可以描绘成一个或多个where约束条件,指向若干被select的元组的有向图。箭头的起点是约束条件,终点是被约束的标签。所以,需要判断元组两两之间是否存在约束与被约束关系,以及谁约束谁。在判断三元组间关系时,将问题组织成阅读理解问题的格式,以原文本为文本部分,问题是以下哪个三元组为筛选目标,而后拼接三个选项:三元组1,三元组2,无关系。将拼接后文本输入bert模型进行选择,选出哪个元组作为被约束对象,进而确认sql语句的顺序关系。
[0064]
由于三元组之间的关系除了存在约束与被约束的关系外,同一层级间,还有“与”和“或”的关系。针对约束与被约束形成的关系图,在组织成树状图结构后,针对每个层级进行“与或”分类。通过将文本拼接三元组1标签与三元组2标签的方式,输入bert模型分类,确认数值关系。然后合并“与”,“或”关系组成完整语句。
[0065]
根据形成的完整语句,被指向节点或被判定为选择函数包含的标签置于select语句中,后续拼接from表名,where条件语句。条件中若包含被指向节点,则用括号包含select语句递归,形成完整的sql语句。
[0066]
在进一步的实施例中,当需要应用于多张表格时,先对表名称进行筛选,根据文本于数据库中表名,判断某张表是否被选中。在选中的表格中,需要对文本中提及的实词进行判断,将实词划分到不同的表格下,然后再输入本文描述的模型进行判断。同时,若出现了省略标签的值,则根据文本判断值所属的表格,进行补全。
[0067]
实施例四
[0068]
在一个实施例中,提出一种自然语言转换为sql语句的系统,用于实现自然语言转换为sql语句的方法,该系统具体包括以下模块:数据读取模块、分词模块、模型构建模块、分类模块、数据分析模块和sql语句构建模块。
[0069]
具体的,数据读取模块用于根据需求读取待分析的自然语言文本数据;分词模块用于对读取到的文本数据执行分词操作,以及词性判断;模型构建模块用于根据数据分析需求构建所需的模型;数据分析模块用于根据分析需求,调用构建好的模型执行数据分析;sql语句构建模块用于根据数据分析结果构建数据库可识别的sql语句。其中,模型构建模块构建的模型包括:标签判断模型、关系判断模型、数值判断模型、判别模型。
[0070]
分词模块包括分词模型,用于对读取到的文本数据进行分词,同时执行实词与虚词的词性判断,并将词性判断结果送入分类模型中。
[0071]
分类模块利用模型构建模块构建的模型对分词结果进行分类,将实词送入标签判断模型中,判断是否是标签类;将虚词送入关系判断模型中,判断是否是关系类;将不属于实词或虚词的词送入数值判断模型中,判断是否是数值类。
[0072]
数据分析模块根据分类模型的分类结果,从标签类、关系类、数值类中各取一个进行拼接,获得三元组,并通过排列组合的方式,得到所有的三元组。将三元组与文本进行拼接,输入判别模型中,进而通过筛选获得贴合实际的三元组。随后,通过遍历的方式,继续从分类结果中读取分类数据,进行拼接、筛选,当所有正确三元组被筛选出时,结果当前的分析过程。
[0073]
sql语句构建模块对数据分析模块输出的三元组进行位置判断,通过结合文本语句的方式,判断各个三元组在sql语句中的对应位置,以及逻辑关系,并根据判断结果,构建符合数据库识别的sql语句。
[0074]
如上所述,尽管参照特定的优选实施例已经表示和表述了本发明,但其不得解释为对本发明自身的限制。在不脱离所附权利要求定义的本发明的精神和范围前提下,可对其在形式上和细节上做出各种变化。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1