一种用于医疗问诊的对话摘要生成方法
本发明涉及自然语言处理,具体为一种用于医疗问诊的对话摘要生成方法。
背景技术:
1、近年来随着电脑和智能手机的广泛普及,网民数量日益增多,导致网络中数据呈爆炸式方式增长,在线医疗服务是近几年流行起来的一种网络服务,庞大的网民数量为在线医疗服务的发展提供了广大的市场,如今越来越多的人开始享受在线医疗服务,足不出户就可以与医生面对面交流,解决健康困扰。医疗问诊对话摘要已成为一个迫切需要,是一个非常有研究价值的问题。而自动生成对话摘要则提供了一个高效的解决方案。但现有技术中,由于句子中包含了无效信息,导致了生成的医患对话摘要事实出入大,准确率低的问题。
技术实现思路
1、本发明的目的是:针对现有技术中由于句子中包含了无效信息,导致了生成的医患对话摘要事实出入大,准确率低的问题,提出一种用于医疗问诊的对话摘要生成方法。
2、本发明为了解决上述技术问题采取的技术方案是:
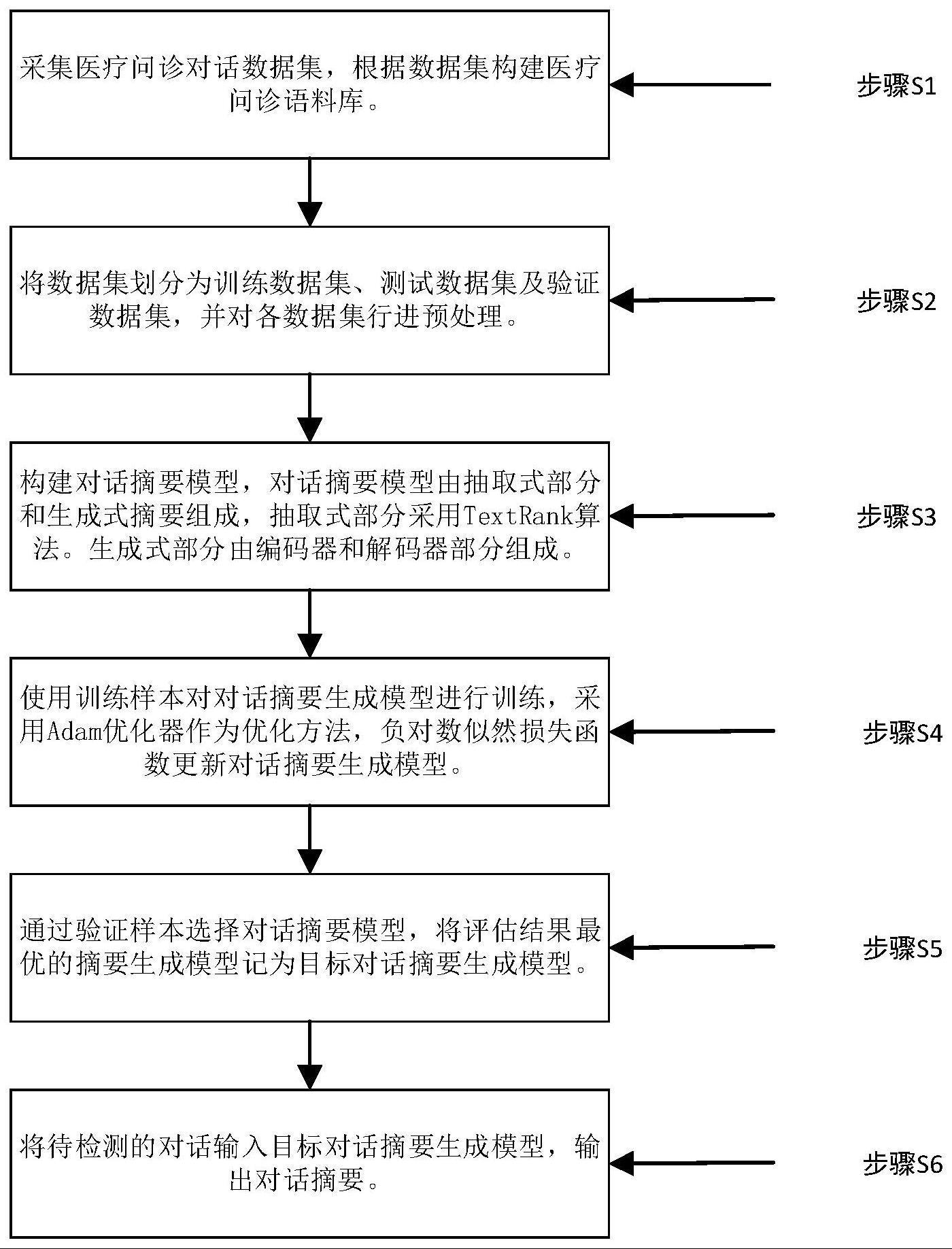
3、一种用于医疗问诊的对话摘要生成方法,包括以下步骤:
4、步骤一:获取原始医疗问诊对话数据,并且同步获取已经由医生或医生助手总结的对话内容摘要,以此构建文本数据;
5、步骤二:将文本数据中医生与患者之间的对话作为特征、医生或医生助手总结的对话内容摘要作为标签,得到标记后的数据;
6、所述文本数据中医生与患者之间的对话包括病史、病情说明、症状、医生咨询建议以及医生给出诊断和合理治疗方案;
7、步骤三:利用标记后的数据训练bilstm神经网络,所述bilstm神经网络包括抽取式摘要、生成式摘要和指针生成器网络,所述生成式摘要包括编码器和解码器;
8、所述神经网络首先将标记后的数据进行分词,并将分词结果分别进行编码,得到多个词向量,然后抽取式摘要对词向量进行信息过滤,保留包含了事实的有效信息的词向量;
9、所述编码器用于将抽取式摘要保留的句子进行特征提取,并将提取到的特征进行拼接,得到最终特征表达;
10、所述解码器用于对最终特征表达进行解码,得到概率分布;
11、所述指针生成器网络用于结合复制机制和覆盖机制对概率分布进行处理,得到最终分布;
12、步骤四:将待识别医疗问诊对话数据输入训练好的bilstm神经网络,根据最终分布,保留概率最高的医疗问诊对话摘要。
13、进一步的,所述步骤一中原始医患对话数据通过urllib的request库从互联网上爬取得到。
14、进一步的,所述神经网络首先将标记后的数据进行分词,并将分词结果分别进行编码的具体步骤为:
15、针对标记后的数据,以[cls]为句子开头,[sep]为句子结尾,对每个句子进行处理,并将处理后的句子利用分词词典进行id转换,设置输入模型的长度为512,对于大于输入长度的句子,保留前512个id,对于小于输入长度的句子,使用[pad]补全,最后将转换后的id输入到预训练模型中,得到编码信息,即词向量。
16、进一步的,所述抽取式摘要对词向量进行信息过滤通过textrank算法进行,所述textrank算法表示为:
17、
18、其中,ws(vi)表示语句vi的最终得分,d表示阻尼系数,初始值为0.85,wji表示j和i这两个句子之间的相似度值,wjk表示j和k这两个句子之间的相似度值,vk表示除句子vi外的所有句子,ws(vj)表示语句vj的最终得分。
19、进一步的,所述编码器由一个双向长短期记忆网络构成,所述双向长短期记忆网络的隐藏层中包括三个门控结构和一个隐藏状态at,所述一个隐藏状态包括遗忘门ft、输入门it和输出门ot;
20、双向长短期记忆网络的隐藏层表示为:
21、ft=σ(wf·[ht-1,xt]+bf)
22、it=σ(wi·[ht-1,xt]+bi)
23、at=tanh(wa·[ht-1,xt]+ba)
24、ot=σ(wo·[ht-1,xt]+bo)
25、其中,xt表示t时刻的输入,ht-1表示t-1时刻的隐藏状态值;wf、wi、wo、wa分别为遗忘门、输入门、输出门和特征提取过程中ht-1的权重系数;bf、bi、bo、ba分别为遗忘门、输入门、输出门和特征提取过程中的偏置值;tanh表示正切双曲函数,tanh表示为:
26、
27、σ表示sigmoid激活函数,σ表示为:
28、
29、遗忘门和输入门用于计算t时刻的状态c(t),c(t)表示为:
30、c(t)=c(t-1)⊙f(t)+i(t)⊙a(t)
31、其中⊙为handamard积;
32、t时刻的隐藏状态h(t)由输出门ot和当前时刻的状态ct求出,表示为:
33、h(t)=o(t)⊙tanh(c(t))。
34、进一步的,所述解码器采用注意力机制,通过对每个解码步骤中的输入状态st,隐藏状态hi进行加权和得到输入的贡献值at,输入的贡献值at表示为:
35、at=softmax(vttanh(whhi+wsst))
36、其中,v、wh和ws是可以学习参数;
37、根据输入的贡献值at和隐藏状态hi计算加权的输出向量表示为:
38、
39、其中,为第i句的贡献值;
40、利用加权的输出向量和输入状态st得到t时刻输出词汇的概率分布,其公式为:
41、
42、其中,v'和v为可以学习参数,yt为第t时刻解码器输出。
43、进一步的,所述指针生成器网络结合复制机制和覆盖机制对概率分布进行处理,得到最终分布的具体步骤为:
44、指针生成器网络在第t时刻解码时计算生成概率pgen,表示为:
45、
46、其中,yt-1表示第t-1时刻解码器输出,、ws和wy为可学习参数;
47、复制单词的贡献分布表示为:
48、
49、其中,pvocab(yt)表示生成词的概率分布;
50、解码器过往时间步骤的注意力分布的和,得到覆盖向量ct,表示为:
51、
52、其中,ct表示到第t时刻为止这些单词从注意力机制接受到的覆盖程度;
53、覆盖向量用于注意力机制,将输入的贡献值at公式改进为:
54、
55、其中,wc和battn为可以学习参数。
56、进一步的,所述bilstm神经网络的训练过程中采用集束搜索方式进行解码,每次只保留5个候选结果,生成医疗问诊对话摘要,再和输入摘要进行对比,计算负对数似然损失函数,通过反向传播更新模型中所有参数,基于损失最小化作为训练目标,采用adam优化器重复训练过程,保存整个训练过程中所得的模型及其对应的模型参数,同时设置超参数:
57、所述超参数设置为:训练轮次设置为30,容忍度设置为50,训练批次大小设置为4,学习率为1e-5,bilstm隐藏层维度设置为150。
58、本发明的有益效果是:
59、本技术设置了抽取式摘要部分和生成式摘要,首先从文本之中选取出重要的含有有效信息的多个句子,再将其输入到生成式摘要的模型,通过生成式摘要模型,将抽取式摘要部分抽取的句子融合成更简短的包含了更多信息的句子。这样既保留了原文中包含了事实的有效信息,又生成了流畅简短的句子,并且提高了生成医患对话摘要的准确率。
60、能够解决现有的摘要生成方法中存在的摘要结果与问诊对话事实出入大,可读性不强的问题,同时有助于辅助医生完成病例总结。
- 还没有人留言评论。精彩留言会获得点赞!