一种基于动作检测机制的CGF行为建模方法及系统
本发明涉及计算机生成兵力行为建模,特别是涉及一种基于强化学习和动作检测机制的计算机生成兵力行为建模方法和系统。
背景技术:
1、计算机生成兵力(computer generated force,cgf)是作战仿真领域的重点研究内容之一,其思想是通过仿真的方式模拟战场环境中的坦克、士兵和作战飞机等军事单位,主要用于战术推演、模拟训练和辅助决策等,以达到降低成本、扩大规模的目的。传统的cgf建模方法有有限状态机、行为树、动态脚本等知识工程方法,主要针对具体的作战任务,收集作战条令、行动规程等领域专家知识直接描述行为输出,一是通常需要耗费大量的时间和重复性迭代工作;二是cgf行为能力通常仅限于确定的理论和规则,产生的行为缺乏适应性。
2、强化学习(reinforcement learning,rl)是机器学习的一个重要分支,是一种以环境反馈作为输入并能通过人为定义的奖励回报逐步适应环境的学习方法。强化学习智能体(agent)通过不断地与环境交互获取经验并学习到相应的策略。近年来,由于强化学习算法和计算机硬件能力的提升,该领域取得了长足进步,强化学习控制的智能体能够适应日益复杂的环境并用于解决相关问题,开始逐步往模拟训练、兵棋推演、红蓝双方对抗等应用中拓展。然而,由于强化学习算法训练所需样本数量大、超参数影响和算法收敛的稳定性等方面问题,想要训练得到稳定和可靠的强化学习智能体仍然是比较困难的,并且针对不同的应用领域目前还没有相对统一的体系框架和通用的解决方案。目前,在强化学习算法及算法改进的领域可以查到大量的相关文献,但针对特定领域的相对通用化的强化学习算法集成框架的文献资料较少,相关算法的开发、训练和应用流程框架也非常有限。
3、cgf行为建模是具有以下几大特点,一是cgf在与环境的交互过程中需要尽可能多地试错,因此需要探索大量的未知动作;二是cgf与环境有实时的交互,并且在交互的过程中会改变环境的状态;三是cgf与环境的交互关注的是长线回报,即不以完成某个具体的动作如开火或隐蔽等为目的,而是以完成某个特定任务为最终目标。这三点决定了采用dl进行cgf建模是非常自然的且有优势的。另一方面,深度学习(deep learning,dl)近年来发展迅速,在众多领域都取得了好的应用效果。深度强化学习(deep reinforcement learning,drl)是dl与rl的结合,是在rl的基础上引入了深度神经网络的概念,借助神经网络强大的表征能力拟合q函数或直接拟合策略以解决状态-动作空间过大或连续状态-动作空间问题,实现了从感知到动作的端到端的学习。因此,基于drl的cgf行为建模能够获得泛化能力强的任务策略,同时能够自动提取战术特征,在建模效率、建模的客观性和探索更大的动作空间方面具有更大的优势,能够克服上述所提迭代性工作和缺乏适应性的问题。
4、但是,即使目前最新的端到端的drl算法仍然需要巨大的样本量,而cgf行为建模可供使用的数据通常是有限的,因为战斗数据的获取通常非常困难且代价极大,所以drl算法训练到收敛的过程极为艰难。
技术实现思路
1、为了解决上述背景技术的不足之处,本发明提出一种基于动作检测机制的强化学习驱动的cgf行为建模方法及系统,在动作和奖励两方面引入交互引导式干预,用于训练cgf行为模型使之可以在特定的任务环境中完成指定的任务。
2、为实现上述目的,本发明所设计的一种基于动作检测机制的cgf行为建模方法,其特殊之处在于,所述方法包括如下步骤:
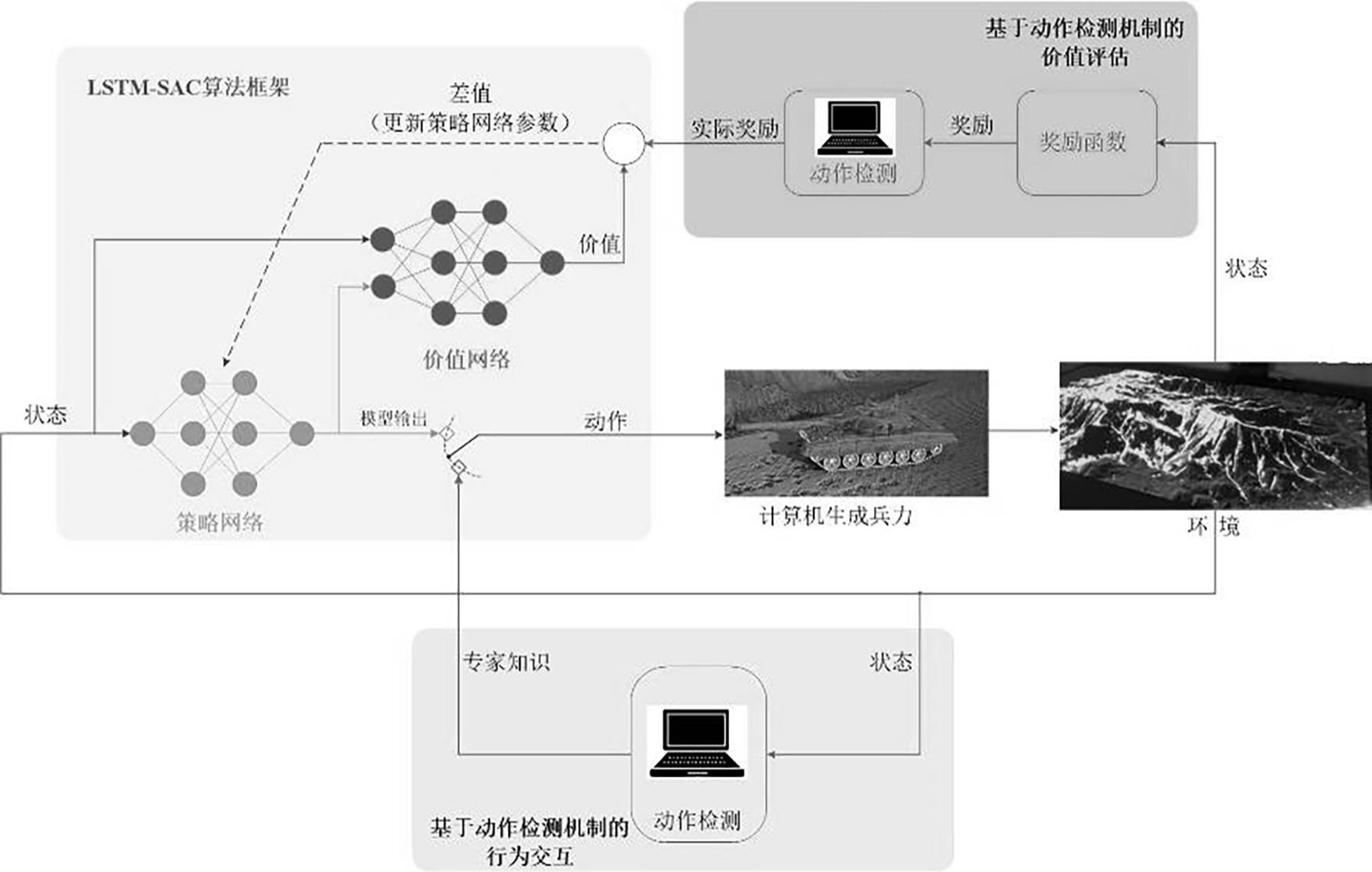
3、s1基于lstm-sac算法框架构建cgf行为预测模型;
4、s2对所述cgf行为预测模型进行训练;
5、s3将环境信息和状态信息输入至所述cgf行为预测模型进行预测,所述cgf行为预测模型依据环境和状态输出预测的动作;
6、其中,步骤s2中所述cgf行为预测模型的训练过程包括:
7、s21所述cgf行为预测模型与输入的环境信息交互后输出下一步动作;
8、s22采用动作检测机制对所述cgf行为预测模型输出的动作进行判断,当输出的动作正确则被赋予负反馈,当输入的动作不正确则被赋予正反馈,所有反馈信息与动作信息一同被记录至经验回放池;
9、s23基于所述经验回放池更新所述cgf行为预测模型的参数;
10、s24循环步骤s21~s23直至达到设定的循环次数。
11、优选地,步骤s1)中,所述基于lstm-sac算法框架的cgf行为预测模型的最佳策略 π*满足:
12、
13、式中, s、 a为状态和动作,e( st, at)~ π表示cgf在策略 π、动作 a t和状态 s t下获得奖励的期望,下标 t表示时刻,r( s t, a t)为 t时刻的奖励, h( π(·| s t))为 t时刻的状态熵, α表示温度调整参数;
14、优化目标函数为:
15、
16、其中, e π表示cgf在策略 π下获得奖励的期望。
17、优选地,步骤s23中,更新所述cgf行为预测模型参数的方法为:
18、初始化两个soft-q函数网络参数 θ和策略网络参数 φ,初始化经验回放池;在每一次循环迭代中,根据接收的观察量 o t策略网络选出动作 a t,并将训练过程放入经验回放池r;从所述经验回放池r中选取n个片段,训练lstm网络,更新两个soft-q函数网络参数 θ,更新策略网络参数 φ,更新温度调整参数 α,更新网络目标参数 θi直至循环停止。
19、优选地,更新soft-q网络参数 θ的方法为将 θ- λ q▽ θ j q ( θ)更新为 θ:
20、
21、式中,▽表示微分, j表示优化目标, q表示值函数网络, θ表示 q网络参数, λ q表示soft-q网络参数学习率, r表示奖励值,γ表示调节因子, h表示网络输出,表示更新后的 q网络参数。
22、优选地,更新策略网络参数 φ的方法为将 φ-λ π▽ φ j π( φ)更新为 φ:
23、
24、式中, λ π表示策略网络参数学习率, f表示动作 a t的重参数化表示, ε表示输入的噪声信号。
25、优选地,更新目标网络参数 θi的方法为将τ θi+(1-τ) θi更新为,τ是模型超参数,需要手动进行调节。
26、优选地,步骤s22中所述cgf行为预测模型在状态 s t执行动作 a t,得到奖励 r t和下一个状态 s t+1,四元组数据( s t, a t, r t, s t+1)被存入经验回放池r,所述奖励 r t为根据动作检测机制输出的正反馈或负反馈。
27、优选地,根据动作检测机制输出的正反馈或负反馈通过动作捕捉系统采集得到或者通过与计算机通信的设备输入获得。
28、本发明还提出一种基于动作检测机制的cgf行为预测系统,其特殊之处在于,包括智能体、cgf行为预测模型和动作检测模块;
29、所述智能体:用于将环境和状态输入至cgf行为预测模型和动作检测模块,将所述cgf行为预测模型输出的动作传输至动作检测机制,接收所述动作检测模块输出的正反馈或负反馈传输至cgf行为预测模型;
30、所述cgf行为预测模型:用于根据环境和状态输出动作,并根据正反馈或负反馈完成模型训练;
31、所述动作检测模块:用于根据环境和状态和所述cgf行为预测模型输出的动作,输出正反馈或负反馈。
32、本发明另外提出一种计算机可读存储介质,存储有计算机程序,所述计算机程序被处理器执行时实现上述一种基于动作检测机制的cgf行为建模方法。
33、本发明的目的是为了克服上述背景的不足,设计基于动作检测机制的强化学习驱动的cgf行为建模方法及系统,在动作和奖励两方面引入检测式干预,用于训练cgf行为模型使之可以在特定的任务环境中完成指定的任务,具体为:一是在模型输出的动作基础上增加检测判断机制或直接采集输入动作代替模型动作;二是cgf与环境交互结果的奖励值经过检测判断后再输入至dr算法中。相比于直接采取不基于模型的drl算法直接开展cgf行为模型运算,可以在cgf行为模型中融入更准确的动作经验值,加速深度强化学习算法的收敛过程。本发明提供了一套较为完整的模型训练流程和方法,可以为cgf行为建模提供参考,可以广泛应用于军事建模与仿真领域。
34、本发明主要可以实现如下功能:
35、1. 开发了一种基于动作检测机制的drl算法框架,在训练阶段对智能体的动作输出具有检测作用,训练完成后则不再需要。框架采用actor-critic体系架构和改进的价值和策略网络,可以用于训练cgf行为模型,用于模拟训练和军事辅助决策领域。
36、2. 通过设计的行为模型建模框架,在模型训练的过程中设计了动作检测机制,可以在必要的时候进行实时干预并纠正智能体的不合理行为,从而进一步提高drl的收敛速度和建模效率。
37、3. 有了完整的模型训练方法和框架后,cgf的应用场景和强化学习算法实现可以独立设计,适用于不同的cgf智能体训练和不同的强化学习算法以模块化的方式进行替换。
38、4. 因为强化学习关注的是长线奖励,即以与环境交互的最终结果为判定胜负的依据,这使得稀疏奖励的问题成为制约强化学习推广应用的重要因素之一。稀疏奖励是指智能体在与环境交互的过程中可能很长时间都不能得到正向奖励,从而导致智能体的训练非常困难。本发明设计的基于动作检测机制的方法可以在一定程度上缓解稀疏奖励的问题,因为回路中的指导者可以及时地将智能体与环境交互的结果反馈给智能体,也因此能够提高智能体训练的速度。
- 还没有人留言评论。精彩留言会获得点赞!