一种基于肢体方向线索解码网络的学习者正面姿态估计方法
本发明涉及计算机视觉姿态检测及评估领域,具体的,涉及一种基于热图回归网络的课堂学习回答问题意图的检测,以可见光摄像头获取到的学习者课堂上的连续视频帧作为输入数据,通过所训练的姿态检测神经网络进行人体姿态提取,再与标签训练设定的阈值进行对比,判断学习者是否有回答问题的意图,并告知课堂教学者,以此作为课堂教学的指导依据。
背景技术:
1、当前,基于人工智能的姿态识别技术在很多领域中都得到了广泛的应用。在体育赛事、运动健身和舞蹈学习训练指导方面,人工智能因其便利的技术而发挥着十分重要的作用。在校园课堂教学中,教学者的精力和时间都是有限的,通常无法对每个学习者每一个时刻的状态和行为全部都洞悉,人工智能技术特别是人体姿态识别技术可以辅助教学者用更多的“眼睛”来洞察更多的学生,了解学习者在课堂上的状态,判断学习者是否有意图进行课堂互动等意图,能够更好的因材施教,促进课堂教学积极健康的发展。
2、本发明利用教室内的多个种类的摄像头,对学习者姿态进行检测,从而判断学习者是否有回答问题的意图。具体地,本发明将以人体姿态识别模块进行详细的流程讲述。本发明利用摄像头得到学习者的视频序列和3d结构信息,对图片数据进行简单的预处理后即可输入到网络模型中进行训练,最终结合3d结构信息输出学习者的动作姿态数据并判断其是否有回答问题的意图,反馈给教学者,进而提升课堂教学的效率与质量。目前,面向课堂教学的人体姿态识别方法面对课堂上的复杂背景,学习者的肢体重叠,以及区分课堂教学中多媒体图片上的人物和实际的学习者还存在着一定的挑战。
技术实现思路
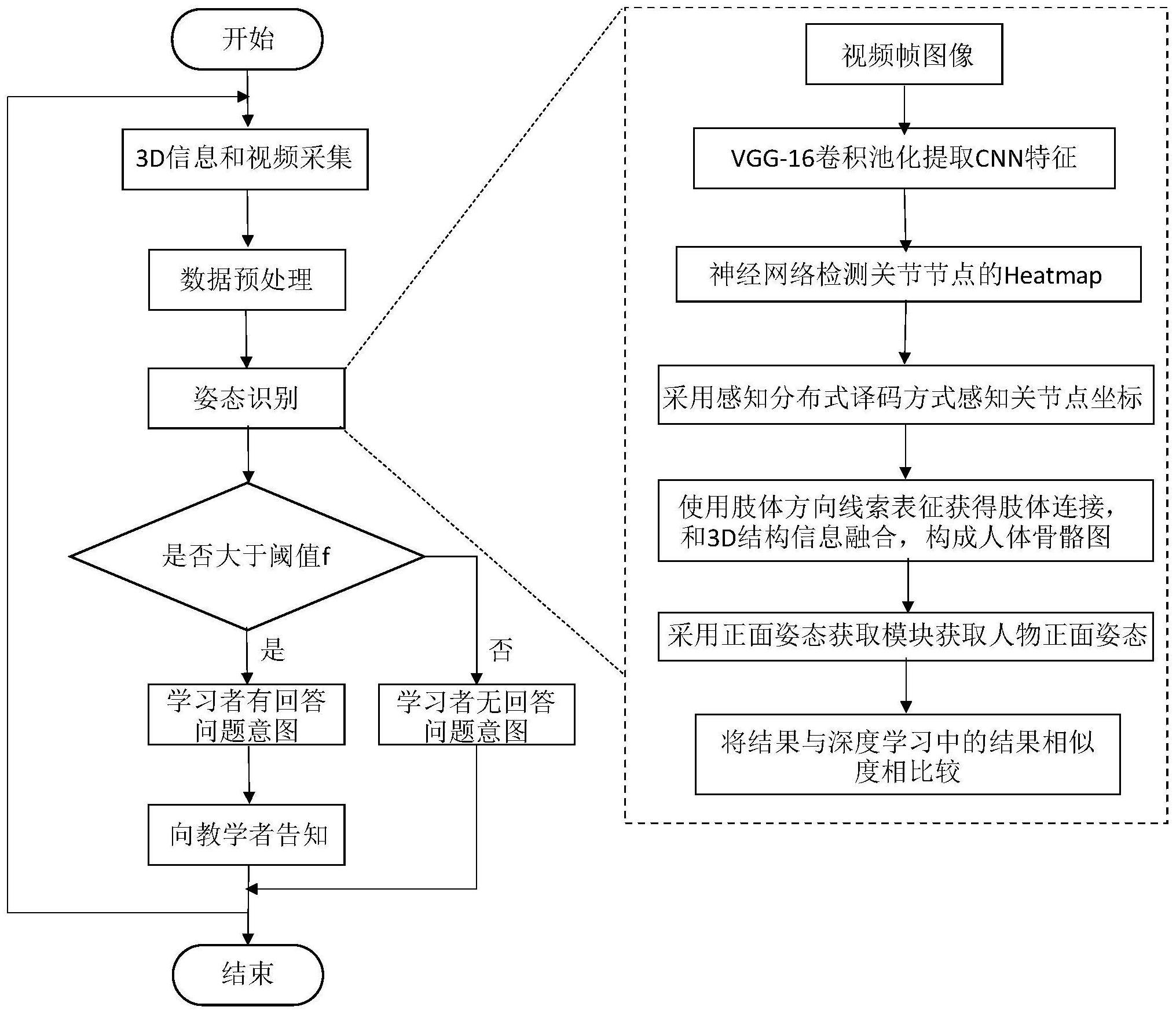
1、针对现有技术的改进需求,本发明公开了一种基于肢体方向线索解码网络的学习者正面姿态估计方法。该方法包括如下步骤:1)分别获取远程课堂教学监控系统中全彩摄像头和结构光摄像头下学习者的视频资源和3d位深度结构信息,并将视频资源按时间顺序分为多帧图像;2)分别对远程课堂教学监控系统中所述的学习者多帧图像进行预处理;3)将预处理后的学习者多帧图像和3d深度信息输入到训练好的基于热图回归的姿态检测神经网络中获取不同学习者在课堂中的姿态识别结果;4)根据不同时刻学习者的姿态识别结果对学习者的行为进行判断,判断其不同的姿态对应回答问题意图强烈度;5)根据所述的意图判断结果向教学者告知其回答问题意图以便于后续更好的课堂教学。
2、优选的,一种基于肢体方向线索解码网络的学习者正面姿态估计方法,其特征在于,包括步骤:
3、分别获取远程考试系统中摄像头下学习者的视频资源和3d结构信息,并将视频资源按时间顺序分为多帧图像;
4、分别对课堂监控系统中所述的学习者多帧图像和3d信息进行预处理;
5、将预处理后的学习者多帧图像输入到训练好的人体姿态识别模型中融合结构光信息获取不同学习者在课堂中的姿态检测结果;
6、根据不同时刻学习者的姿态识别结果对比深度学习中标注的不同状态相似度综合判断是否大于阈值f,从而对学习者是否有回答问题的意图进行判断;
7、根据所述的意图判断结果向教学者提示学习者回答问题的意图或者行为。
8、优选的,所述的姿态检测模型包括图像收集处理模块、姿态识别模块、数据标签训练模块、行为判别模块组成。
9、所述图像收集处理模块将课堂中监控的视频数据流所有帧提取出来作为数据集输入。所述姿态识别模块采用的是一种将姿态检测以及3d结构光信息融合的自底向上的算法,用于将学习者的每一帧图像作为输入提取学习者的人体姿态特征融合3d深度信息来构成骨骼结构图;所述数据标签训练模块来生成判别特征表示;所述行为判别模块用于判别最终的课堂回答问题意图的结果。
10、优选的,上述基于肢体方向线索解码网络的学习者正面姿态估计方法中,所述姿态识别模块采用vgg-16卷积池化提取cnn特征,检测关节节点的heatmap,包括以下步骤:
11、步骤1.1,首先是图像收集处理模块,其中包括了课堂上的全彩摄像头和结构光摄像头,收集并将数据发送到姿态识别模块,将数据分析处理后,通过与数据标签训练模块所得到的对比模型的对比,将结果发送至行为判别模块对学习者的行为及回答问题的意图做出一个准确的判断。
12、步骤1.2,将输入的全彩图像进行特征提取及特征融合。输入一幅图像,经过vgg-16卷积网络提取特征,得到一组特征图,然后分成两个岔路branch1&2,分别使用cnn网络提取置信度和ldr(limb direction cue representation)关联度。采用多级cnn的架构。第一组阶段预测ldrs lt,而最后一组预测置信图st。将每个阶段的预测及其相应的图像特征连接到每个后续阶段。原始方法中的内核大小为7的卷积被替换为内核3的3层卷积,这些卷积在其末端串联,迭代地预测编码部分到部分关联的肢体方向线索表征和检测置信度图。遵循的迭代预测架构改进了连续阶段的预测,t∈{1,...,t},每个阶段都有中间监督。步骤1.3,同时检测和关联,图像由cnn分析(由vgg-16的前8层初始化并微调),生成一组特征图q输入到第一阶段。在这个阶段,网络产生一组局部肢体方向线索表征(ldr)l1=φ1(q)。在每个后续阶段,来自前一阶段的预测和原始图像特征q被连接并用于产生精确的预测,其中,φt是指用于在阶段t进行推理的cnn,而tp是指总ldr阶段的数量。在tp次迭代之后,对置信图检测重复该过程,从最新的ldr预测开始,
13、
14、
15、其中,ρt是指用于在阶段t进行推理的cnn,而tc是指总置信度图阶段的数量。这种方法的ldr和置信度图分支都在每个阶段进行了细化。因此,每个阶段的计算量减少了一半。
16、步骤1.4,置信图结果是在最新和最精细的ldr预测之上预测的,导致置信图阶段之间几乎没有明显差异。为了引导网络迭代地预测第一个分支中身体部位的ldr和第二个分支中的置信度图,在每个阶段的末尾应用了一个损失函数。接下来估计的预测与真实地图和字段之间使用l2损失。在空间上对损失函数进行加权,以解决一些数据集不能完全标记所有人的实际问题。ldr分支在ti阶段的损失函数和置信度图分支在tk阶段的损失函数分别为:
17、
18、
19、其中,是实际的ldr,是实际的部分置信度图,w是当像素p处缺少注释时w(p)=0的二进制掩码。掩码用于避免在训练期间惩罚真正的正预测。每个阶段的中间监督通过定期补充梯度来解决梯度消失问题。总体目标是:
20、
21、步骤1.5在方程式中评估fs。本发明从带注释的2d关键点生成实际的置信度图s*。每个置信度图都是对特定身体部位可以位于任何给定像素中的信念的2d表示。理想情况下,如果图像中出现了一个学习者,如果对应部分可见,则每个置信度图中应该存在一个峰值;如果图像中有多个学习者,则每个学习者i的每个可见部分j应该有一个峰值对应。首先为每个学习者i生成个人置信图令为图像中学习者i的身体部位j的真实位置。中位置处的值定义为:
22、
23、其中,σ控制峰的扩散。网络预测的实际的置信度图是单个置信度图通过最大算子的聚合,取置信度图的最大值而不是平均值,以便附近峰值的精度保持不同,如右图所示。预测置信度图通过执行非极大值抑制获得身体部位的候选。
24、优选的,上述基于肢体方向线索解码网络的学习者正面姿态估计方法中,所述姿态识别模块采用可感知的分布式译码方法感知关节点坐标,包括以下步骤:
25、步骤2.1,常用的标准坐标解码方法是给定一个预测结果:heatmap(h)。其激活的最大位置和第二大位置分别为(m),(s)。那么关节位置是:这种方法将heatmap中的最大激活位置最为最后的预测位置,同时由于下采样输入的高分辨率图像,这样会导致量化误差。所以本专利采用一种可感知的分布式译码方法,以更准确的联合定位在亚像素精度。具体来说,预测的heatmap服从二维高斯分布。所以预测的热图表示为:
26、
27、其中,x是预测heatmap的像素位置,μ是将要被估计的关节坐标位置,k是混合模型中子高斯模型的数量,αk是观测数据属于第k个子模型的概率,φ(x|θk)是第k个子模型的高斯分布密度函数,之后再进行对数转换:
28、
29、步骤2.2,首先要估计的是μ,是极值点,他的一阶导数在x=μ处等于0。采用泰勒定理,在最大激活处m,展开。选择m来近似μ的直觉是,因为他是一个好的大概的关键点预测位置。
30、
31、其中,d″(m)=d″(x)/x=m=-σ-1,表示p在m处的二阶导数。最后得出关节点坐标:
32、μ=m-(d″(m))-1d′(m), (10)
33、优选的,上述基于肢体方向线索解码网络的学习者正面姿态估计方法中,所述姿态识别模块采用使用肢体方向线索表征获得肢体连接,构成人体骨骼图,包括以下步骤:
34、步骤3.1,将视频图像点μ处的实际的ldr,定义为:
35、
36、其中,是肢体方向上的单位向量。μ为线段距离阈值内的点满足:和
37、实际的局部肢体方向线索表征平均图像中所有学习者的表征,
38、
39、其中,nc(μ)是所有i个学习者在点μ处的非零向量的数量。
40、步骤3.2,测量预测的ldr与通过连接检测到的身体部位形成的候选肢体的对齐情况。具体来说,对于两个候选部位位置和沿线段对预测的部位肢体方向线索表征lc进行采样,以测量它们关联的置信度:
41、
42、其中,μ(u)对两个身体部位和的位置进行插值,接下来再对u的均匀间隔值进行采样和求和来近似积分。
43、
44、步骤3.3,肢体方向线索表征模块使用ldr的多人解析,对检测置信度图执行非极大值抑制以获得一组离散的零件候选位置。对于每个部分,由于图像中有多个学习者或误报,可能有多个候选者。这些候选部件定义了大量可能的肢体。本发明使用等式中定义的ldr上的线积分计算对每个候选肢体进行评分。寻找最优解析的问题对应于一个已知为k维匹配问题,并且存在许多relaxation。本发明为优化添加了两个relaxation。首先,选择最少数量的边来获得人体姿态的生成骨架,而不是使用完整的图。其次,进一步将匹配问题分解为一组二分匹配子问题,并独立确定相邻树节点中的匹配,有了这两个relaxation,优化被简单地分解为:最后在获得所有肢体后,将相同关节连接的肢体看作同一人的肢体。
45、步骤3.4,结构光摄像头采集到3d信息具有空间坐标准确性,不易被噪声遮挡等因素影响,具有后验性,采用结构光摄像头能够提取课堂内的空间信息,面对课堂上的复杂背景,学习者的肢体重叠,以及区分课堂教学中多媒体图片上的人物和实际的学习者,结构光摄像头能够很好的克服这些问题,有着显著的优势。最后我们将连接好的肢体结构图与3d结构位深度信息进行对比融合,就得到了学习者的学习姿态,并得到了骨骼结构图。
46、优选的,上述基于肢体方向线索解码网络的学习者正面姿态估计方法中,所述姿态识别模块采用人物正面姿态获取模块的算法,包括以下步骤:
47、步骤4.1,不同于已有的二维姿态估计方法,我们提取的是非正面角度人体图像的正面姿态,进而推进学习者正面图像生成,所以要将多人图像依据连接的人体骨骼图进行拆分,本发明采用yolo进行拆分。
48、步骤4.2,采用姿态锚定的回归模块,基于两阶段目标检测方法r-cnn中锚定的思想,采用了基于姿态锚定回归的策略.r-cnn采用聚类的方法得到一些固定比例(长、宽)的框作为锚点,引入锚点让模型对物体的大小和形状有一定的先验认知,辅助模型进行训练。聚类得到多个姿态的锚定姿态。
49、步骤4.3,采用特征融合,因为二维人体图像缺少深度信息,使从单一二维人体图像得到正面姿态变得困难;而三维姿态是包含深度信息的人体三维拓扑结构,因此引入三维姿态数据作为输入会给模型带来一定的深度信息.本专利采用基于单幅图像提取人体三维姿态数据的算法将图像的表观特征和三维姿态特征做拼接融合,得到学习者图像的正面姿态。
50、优选的,上述基于肢体方向线索解码网络的学习者正面姿态估计方法中,所述数据标签训练模块包括以下步骤:
51、步骤5.1,从网络上下载大量不同光照、角度、背景环境下的学习者在课堂上有意图举手回答问题和无意图回答问题的体态姿势图片。
52、步骤5.2,使用网络上下载大量不同光照、角度、背景环境下的学习者在课堂上有意图举手回答问题和无意图回答问题的体态姿势图片样本作为训练数据集。
53、步骤5.3,增广数据集,由于训练模型需要大量的参数,但网络上相关资源较少,所以需要对已有的数据进行翻转、平移或旋转等操作。创造出更多的数据,增加模型训练的数据量,提高模型的泛化能力,增加噪声数据,提升模型的鲁棒性。
54、步骤5.4,在模型架构上选择,深度学习框架pytorch为后端,将以上数据进行深度训练,最后建立模型。通过视频图像内容进行标准化、统一化的标记,建立对比数据库。
55、优选的,上述基于肢体方向线索解码网络的学习者正面姿态估计方法中,所述行为判别模块包括以下步骤:
56、步骤6.1,将经过预处理的数据传输到行为判别模块,与数据训练模块得到的对比数据库进行对比,与经过深度训练的模型进行比较其相似度,分成四部分,根据手掌举起与头部之间的位置关系分别对应四种意图:没有回答问题意图;意图不明显;有回答问题意图;有强烈回答问题意图。并于头部的位置设定一个阀值f,超过阀值则可以认为学习者有回答问题的意图,反之则没有。
57、步骤6.2,根据学习者在课堂教学中的整个过程中的具体情况,将预测的学习者是否有回答问题的意图的结果反馈给课堂教学者。
58、现有技术相比,本发明的优势在于:提供的一种基于肢体方向线索解码网络的学习者正面姿态估计方法,使得课堂教学流程得到明显优化;本发明提出的四种模块进行流程化全局处理避免了复杂的全局统一网络,具有良好的层次性、结构性和可扩展性等优点。采用各种算法融合的姿态分析和图像处理的模块,大幅提升了对学习者姿态的识别效果,同时减少了后台运算的时间,对智慧课堂教学有着良好的促进作用。
- 还没有人留言评论。精彩留言会获得点赞!