查询方法、查询装置、处理器和查询系统与流程
本技术涉及检索查询领域,具体而言,涉及一种查询方法、查询装置、计算机可读存储介质、处理器和查询系统。
背景技术:
1、在当今大数据时代,数据可能会在不同的渠道以不同的形式被存储在不同的数据源内,考虑到查询数据量与视图的局限性,分页技术便在很早之前就产生了。对于单一数据源来讲,分页只不过是计算好起始条数与终止条数,然后按条件查询数据库即可返回正确的查询结果,但是对于多数据源来讲,怎么查,查多少,如何确定数据的全局顺序,如何在前后翻页时高效的返回正确的结果,与此同时还要保证系统的稳定,避免深度分页问题的加剧。
2、例如,由于新旧系统并行,数据分布存储,各系统不同业务交易等多方面场景与原因,最终会将各种数据存储到不同的数据源中,形成数据孤岛。客户无法进行完整与全面的查看当前数据,只能按照划分规则去不同的系统上进行单独查询,然后再根据单独查询的结果自行拼凑,这极大的影响了系统功能完整性与客户体验。
3、如何打破这种信息孤岛,将信息数据完整的进行整合与对外输出,总体而言有两种思路与方案,即数据层入手与应用层入手。数据层即利用大数据的实时数据流技术将各系统的数据实时进行同步与整合,应用层则从客户的实际查询交易入手,在实际发起查询交易时再通过查询接口进行数据处理和聚合。考虑到各业务系统的数据源、内部处理逻辑、数据结构完全不一致,而且对数据实时性、可靠性、稳定性要求较高,以及当大量数据实时传输时的风险与成本。应用层的多数据源聚合分页技术便成为了首选。
4、在所有数据源聚合分页的技术方案中,为保证翻页数据的准确性,最为容易设计与实现的便是每次查询拉取之前的所有数据。以三个数据源db1,db2,db3,每页10条为例,查第一页时从每个数据源抓取前10条数据,然后从30条数据中截取前10条;查第二页时从每个数据源抓取前20条数据,然后从60条数据中截取第10至第20条;查第n页时从每个数据源抓取前10n条,然后从30n条数据中截取第10n-10至第10n条,如图1所示。
5、每次查询第1-n条数据,上述查询方法普遍存在以下问题:
6、1、每次查询都会将上次数据重复查出,且会出现大量无效数据,命中率低下。
7、2、深度分页问题无法解决,当页数足够大时,如第一万页时,需从每个数据源抓取十万条数据,作为联机查询实时返回结果,这已经超出了响应报文的承载度。
8、3、大量数据被抓取到聚合方的应用服务器内存中处理,会占用服务大量内存,尤其是并发到一定程度后会使得系统资源完全被占用,严重影响其他的正常交易,导致系统的不稳定或不可用。
9、4、对于每次需要大量数据的查询系统,一般而言缓存是必不可少的。但是使用缓存的前提是缓存部分的数据被使用的重复率与命中率要高,如机构信息,参数信息,数据字典等,这部分数据变动较少且重复使用率高,作为缓存数据是最为合适的。但是对于每次不同的客户在不同地点通过不同渠道使用不同条件查询出的这部分业务数据,它只在某种特定的场景下才能发挥一部分作用,用作缓存的价值与意义显然不大,而且在并发上来后会消耗掉大量的缓存资源。
技术实现思路
1、本技术的主要目的在于提供一种查询方法、查询装置、计算机可读存储介质、处理器和查询系统,以至少解决现有技术中查询方法的数据处理量过大的问题。
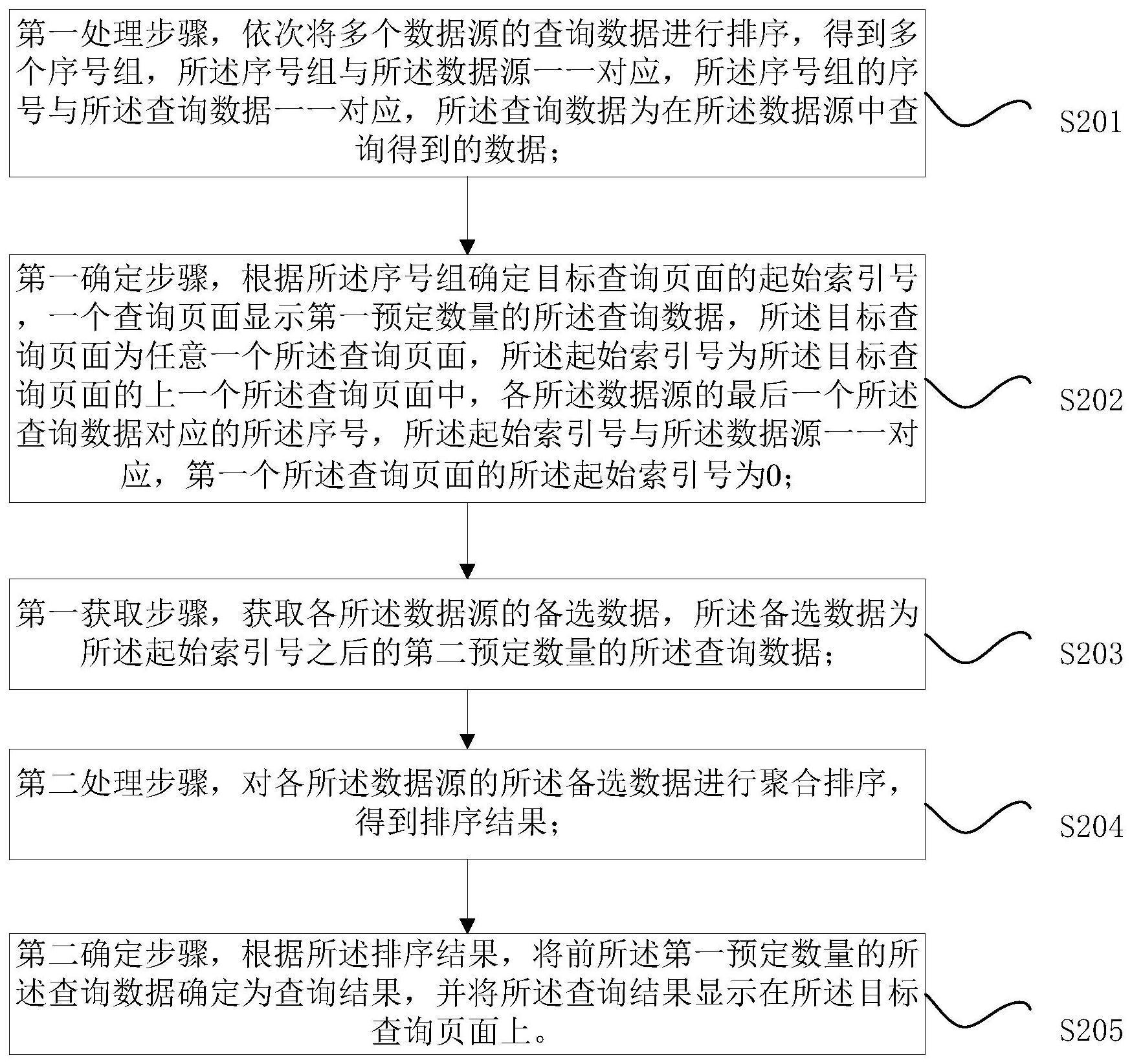
2、为了实现上述目的,根据本技术的一个方面,提供了一种多数据源聚合分页的查询方法。所述方法包括:第一处理步骤,依次将多个数据源的查询数据进行排序,得到多个序号组,所述序号组与所述数据源一一对应,所述序号组的序号与所述查询数据一一对应,所述查询数据为在所述数据源中查询得到的数据;第一确定步骤,根据所述序号组确定目标查询页面的起始索引号,一个查询页面显示第一预定数量的所述查询数据,所述目标查询页面为任意一个所述查询页面,所述起始索引号为所述目标查询页面的上一个所述查询页面中,各所述数据源的最后一个所述查询数据对应的所述序号,所述起始索引号与所述数据源一一对应,第一个所述查询页面的所述起始索引号为0;第一获取步骤,获取各所述数据源的备选数据,所述备选数据为所述起始索引号之后的第二预定数量的所述查询数据;第二处理步骤,对各所述数据源的所述备选数据进行聚合排序,得到排序结果;第二确定步骤,根据所述排序结果,将前所述第一预定数量的所述查询数据确定为查询结果,并将所述查询结果显示在所述目标查询页面上。
3、可选地,根据所述序号组确定目标查询页面的起始索引号,所述方法包括:第二获取步骤,获取当前查询结果,所述当前查询结果为当前的所述查询页面显示的所述查询结果;第三确定步骤,在所述当前查询结果中,将各所述数据源的最后一个所述查询数据对应的所述序号确定为当前的所述查询页面显示的所述起始索引号;替换步骤,将当前的所述查询页面的下一个所述查询页面作为所述目标查询页面,并依次重复所述第一确定步骤、所述获取步骤、所述第二处理步骤和所述第二确定步骤,使得下一个所述查询页面替换当前的所述查询页面;依次重复所述第二获取步骤、所述第三确定步骤和所述替换步骤至少一次,直至当前的所述查询页面的序号为所述目标查询页面的序号的上一个所述查询页面。
4、可选地,获取各所述数据源的备选数据,所述方法包括:第三获取步骤,获取目标起始索引号,所述目标起始索引号为目标数据源对应的所述起始索引号且为m,所述目标数据源为任意一个所述数据源;第四确定步骤,所述目标数据源的所述序号组中,将序号m+1至序号m+n的所述查询数据确定为所述目标数据源的所述备选数据,所述第二预定数量为n;依次重复所述第三获取步骤和所述第四确定步骤至少一次,直至得到所有的所述数据源的所述备选数据。。
5、可选地,在将所述查询结果显示在所述目标查询页面上之后,所述方法包括:记录所述目标查询页面的序号和下一个所述查询页面的所述起始索引号。
6、可选地,所述第二预定数量大于或者等于所述第一预定数量。
7、根据本技术的另一方面,提供了一种多数据源聚合分页的查询装置,所述装置包括:第一处理单元,用于执行第一处理步骤,依次将多个数据源的查询数据进行排序,得到多个序号组,所述序号组与所述数据源一一对应,所述序号组的序号与所述查询数据一一对应,所述查询数据为在所述数据源中查询得到的数据;第一确定单元,用于执行第一确定步骤,根据所述序号组确定目标查询页面的起始索引号,一个查询页面显示第一预定数量的所述查询数据,所述目标查询页面为任意一个所述查询页面,所述起始索引号为所述目标查询页面的上一个所述查询页面中,各所述数据源的最后一个所述查询数据对应的所述序号,所述起始索引号与所述数据源一一对应,第一个所述查询页面的所述起始索引号为0;获取单元,用于执行第一获取步骤,获取各所述数据源的备选数据,所述备选数据为所述起始索引号之后的第二预定数量的所述查询数据;第二处理单元,用于执行第二处理步骤,对各所述数据源的所述备选数据进行聚合排序,得到排序结果;第二确定单元,用于执行第二确定步骤,根据所述排序结果,将前所述第一预定数量的所述查询数据确定为查询结果,并将所述查询结果显示在所述目标查询页面上。
8、根据本技术的再一方面,提供了一种计算机可读存储介质,所述计算机可读存储介质包括存储的程序,其中,在所述程序运行时控制所述计算机可读存储介质所在设备执行任意一种所述方法。
9、根据本技术的再一方面,提供了一种处理器,所述处理器用于运行程序,其中,所述程序运行时执行任意一种所述的方法。
10、根据本技术的又一方面,提供了一种多数据源聚合分页的查询系统,所述系统包括:一个或多个处理器,存储器,以及一个或多个程序,其中,所述一个或多个程序被存储在所述存储器中,并且被配置为由所述一个或多个处理器执行,所述一个或多个程序包括用于执行任意一种所述的方法。
11、在本发明的实施例,上述多数据源聚合分页的查询方法中,首先,执行第一处理步骤,依次将多个数据源的查询数据进行排序,得到多个序号组,所述序号组与所述数据源一一对应,所述序号组的序号与所述查询数据一一对应,所述查询数据为在所述数据源中查询得到的数据;然后,执行第一确定步骤,根据所述序号组确定目标查询页面的起始索引号,一个查询页面显示第一预定数量的所述查询数据,所述目标查询页面为任意一个所述查询页面,所述起始索引号为所述目标查询页面的上一个所述查询页面中,各所述数据源的最后一个所述查询数据对应的所述序号,所述起始索引号与所述数据源一一对应,第一个所述查询页面的所述起始索引号为0;之后,执行第一获取步骤,获取各所述数据源的备选数据,所述备选数据为所述起始索引号之后的第二预定数量的所述查询数据;之后,执行第二处理步骤,对各所述数据源的所述备选数据进行聚合排序,得到排序结果;最后,执行第二确定步骤,根据所述排序结果,将前所述第一预定数量的所述查询数据确定为查询结果,并将所述查询结果显示在所述目标查询页面上。该查询方法将多个数据源的查询数据进行排序,在显示查询页面的查询结果时,抓取上一个查询页面中各数据源的最后一个查询数据之后的查询数据,一个数据源抓取第二预定数量,数据无需从第一个开始抓取且随页数增加抓取数量也增加,即使目标查询页面为第10000页,只需对固定数量的查询数据进行聚合排序,大大减少了数据处理量,解决了现有技术中查询方法的数据处理量过大的问题,另外,该查询方法不会造成查询数据与上一个查询页面的查询数据重复,重发下去所有的查询页面均不会重复,提高了查询的准确性。
- 还没有人留言评论。精彩留言会获得点赞!