一种文献的共性分析方法及装置与流程
本发明涉及文献分析,具体而言,涉及一种文献的共性分析方法及装置。
背景技术:
1、随着科学技术和经济建设的快速发展,技术文献,尤其是专利文献作为最系统、最全面、最迅速的技术信息源,越来越受到重视,是了解相关领域内应用研究前沿发展的重要文献载体。
2、目前,文献一般是基于基础应用研究的产品,实现基础应用研究的产业化,能够带动产业或多个产业及其企业的发展,具有大的经济和社会效益。以化妆品领域为例,利用特色植物资源的国内化妆品相关的专利文献申请量呈现快速增长态势,专利申请量远高于国外,但专利质量有待提升,技术集中度较低,比较分散地掌握在各创新主体中。因而,若通过全部浏览专利文献的方式,对分散的专利文献进行逐一分析,了解该化妆品领域内应用研究的前沿发展,为基础研究产业化提供技术参考,文献分析效率较低。
技术实现思路
1、有鉴于此,本发明的目的在于提供文献的共性分析方法及装置,以提升文献分析效率。
2、第一方面,本发明实施例提供了文献的共性分析方法,包括:
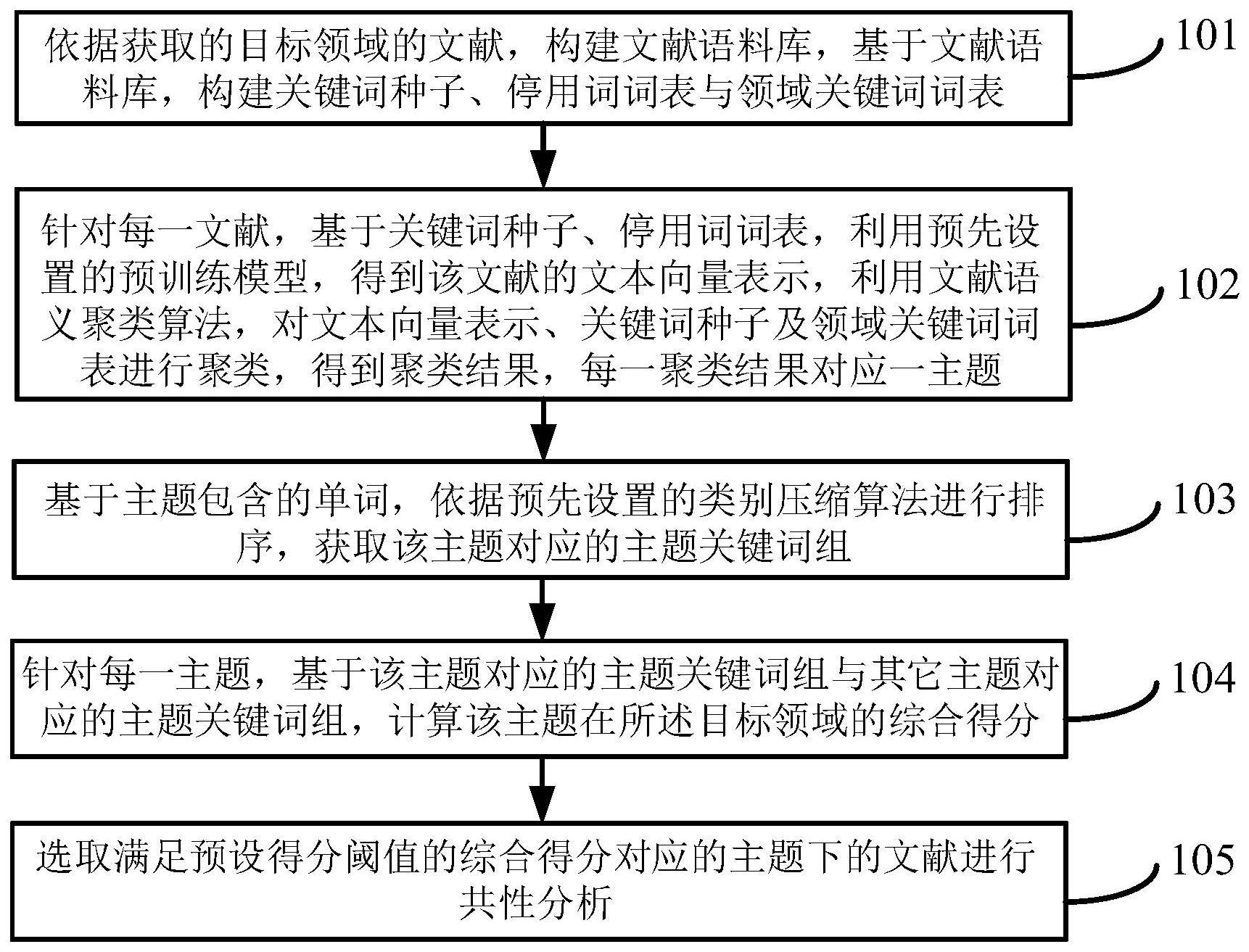
3、依据获取的目标领域的文献,构建文献语料库,基于文献语料库,构建关键词种子、停用词词表与领域关键词词表;
4、针对每一文献,基于关键词种子、停用词词表,利用预先设置的预训练模型,得到该文献的文本向量表示,利用文献语义聚类算法,对文本向量表示、关键词种子及领域关键词词表进行聚类,得到聚类结果,每一聚类结果对应一主题;
5、基于主题包含的单词,依据预先设置的类别压缩算法进行排序,获取该主题对应的主题关键词组;
6、针对每一主题,基于该主题对应的主题关键词组与其它主题对应的主题关键词组,计算该主题在所述目标领域的综合得分;
7、选取满足预设得分阈值的综合得分对应的主题下的文献进行共性分析。
8、结合第一方面,本发明实施例提供了第一方面的第一种可能的实施方式,其中,所述基于主题包含的单词,依据预先设置的类别压缩算法进行排序,获取该主题对应的主题关键词组,包括:
9、针对聚类得到的每一主题,获取该主题包含的主题候选单词,去除主题候选单词中包含的停用词词表中的停用词,得到主题单词;
10、基于主题包含的主题单词以及所有主题包含的主题单词,获取该主题的主题单词的基于类的文档-逆文档频率,基于主题单词的基于类的文档-逆文档频率,获取该主题的主题关键词组。
11、结合第一方面,本发明实施例提供了第一方面的第二种可能的实施方式,其中,所述基于主题包含的主题单词以及所有主题包含的主题单词,获取该主题的主题单词的基于类的文档-逆文档频率,包括:
12、针对主题包含的每一主题单词,获取该主题单词在该主题包括的文献中出现的频率;
13、统计各主题包括的文献中的主题单词总数,基于主题单词总数以及主题数,计算主题平均单词数;
14、基于主题单词在主题包括的文献中出现的频率以及主题平均单词数,获取该主题单词的基于类的文档-逆文档频率。
15、结合第一方面、第一方面的第一种可能的实施方式或第一方面的第二种可能的实施方式,本发明实施例提供了第一方面的第三种可能的实施方式,其中,所述基于该主题对应的主题关键词组与其它主题对应的主题关键词组,计算该主题在所述目标领域的综合得分,包括:
16、获取第一主题的第一主题关键词组以及第二主题的第二主题关键词组;
17、利用基于变换的双向编码器预训练语言模型,分别获得第一主题关键词组中各主题关键词对应的第一词向量编码,以及,第二主题关键词组中各主题关键词对应的第二词向量编码;
18、利用预先设置的语义相似度算法,计算第一词向量编码与第二词向量编码的语义加权相似度值;
19、针对每一主题,基于该主题分别与其他主题的语义加权相似度值,计算该主题在所述目标领域的综合得分。
20、结合第一方面的第三种可能的实施方式,本发明实施例提供了第一方面的第四种可能的实施方式,其中,所述利用预先设置的语义相似度算法,计算第一词向量编码与第二词向量编码的语义加权相似度值,包括:
21、获取第一主题关键词组以及第二主题关键词组分别与领域关键词词表的第一词集和第二词集;
22、针对第一词集的每一主题关键词,获取该主题关键词在对应主题中的第一词频,以及,针对第二词集的每一主题关键词,获取该主题关键词在对应主题中的第二词频;
23、获取第一词集中各主题关键词在对应主题中的词频的第一词频总数,以及,第二词集中各主题关键词在对应主题中的词频的第二词频总数;
24、计算主题关键词在对应主题中的词频与对应该主题的词频总数的商值,得到该主题关键词的权重,所述词频包括第一词频以及第二词频;
25、针对每一主题关键词,计算该主题关键词的权重与该主题关键词对应的词向量编码的乘积,得到该主题关键词的权重分值;
26、计算第一词集中各主题关键词的权重分值的第一权重分值和值和权重的第一权重和值,以及第二词集中各主题关键词的权重分值的第二权重分值和值和权重的第二权重和值;
27、计算第一权重分值和值与第二权重分值和值的乘积,得到分值乘积,以及,第一权重和值与第二权重和值的乘积,得到权重乘积;
28、计算分值乘积与权重乘积的商值,得到第一词向量编码与第二词向量编码的语义加权相似度值。
29、结合第一方面的第三种可能的实施方式,本发明实施例提供了第一方面的第五种可能的实施方式,其中,所述基于该主题分别与其他主题的语义加权相似度值,计算该主题在所述目标领域的综合得分,包括:
30、计算该主题分别与其他主题的语义加权相似度值的语义加权平均相似度值,以及,该主题分别与其他主题的语义加权相似度值的方差;
31、基于语义加权平均相似度值以及方差,获取该主题在所述目标领域的综合得分。
32、结合第一方面、第一方面的第一种可能的实施方式或第一方面的第二种可能的实施方式,本发明实施例提供了第一方面的第六种可能的实施方式,其中,所述利用预先设置的预训练模型,得到该文献的文本向量表示,包括:
33、从文献对应的语料中,剔除停用词词表对应的语料后,利用预先构建的句子转换器预训练模型,对剔除停用词词表对应的语料后的文献进行编码,获得该文献的文本向量表示。
34、第二方面,本发明实施例提供了文献的共性分析装置,包括:
35、语料构建模块,用于依据获取的目标领域的文献,构建文献语料库,基于文献语料库,构建关键词种子、停用词词表与领域关键词词表;
36、主题聚类模块,用于针对每一文献,基于关键词种子、停用词词表,利用预先设置的预训练模型,得到该文献的文本向量表示,利用文献语义聚类算法,对文本向量表示、关键词种子及领域关键词词表进行聚类,得到聚类结果,每一聚类结果对应一主题;
37、词组获取模块,用于基于主题包含的单词,依据预先设置的类别压缩算法进行排序,获取该主题对应的主题关键词组;
38、综合评价模块,用于针对每一主题,基于该主题对应的主题关键词组与其它主题对应的主题关键词组,计算该主题在所述目标领域的综合得分;
39、文献分析模块,用于选取满足预设得分阈值的综合得分对应的主题下的文献进行共性分析。
40、第三方面,本发明实施例提供了计算机设备,包括:处理器、存储器和总线,所述存储器存储有所述处理器可执行的机器可读指令,当计算机设备运行时,所述处理器与所述存储器之间通过总线通信,所述机器可读指令被所述处理器执行时执行上述的文献的共性分析方法的步骤。
41、第四方面,本发明实施例提供了计算机可读存储介质,该计算机可读存储介质上存储有计算机程序,该计算机程序被处理器运行时执行上述的识别文献的共性分析方法的步骤。
42、本发明实施例提供的文献的共性分析方法及装置,包括:依据获取的目标领域的文献,构建文献语料库,基于文献语料库,构建关键词种子、停用词词表与领域关键词词表;针对每一文献,基于关键词种子、停用词词表,利用预先设置的预训练模型,得到该文献的文本向量表示,利用文献语义聚类算法,对文本向量表示、关键词种子及领域关键词词表进行聚类,得到聚类结果,每一聚类结果对应一主题;基于主题包含的单词,依据预先设置的类别压缩算法进行排序,获取该主题对应的主题关键词组;针对每一主题,基于该主题对应的主题关键词组与其它主题对应的主题关键词组,计算该主题在所述目标领域的综合得分;选取满足预设得分阈值的综合得分对应的主题下的文献进行共性分析。这样,通过对文献进行聚类,依据聚类得到的各主题以及主题对应的主题关键词,获取主题在目标领域的综合得分,基于综合得分选取表征目标领域共性的主题对应的文献进行分析,可以有效提升文献分析效率;同时,基于关键词种子及领域关键词词表进行聚类,并利用类别压缩算法优化聚类的主题及主题关键词,以获取领域内最具有共性的文献,从而提高了主题共性提取的准确率。
43、为使本发明的上述目的、特征和优点能更明显易懂,下文特举较佳实施例,并配合所附附图,作详细说明如下。
- 还没有人留言评论。精彩留言会获得点赞!