训练翻译模型的方法、训练判别模型的方法和装置与流程
本公开涉及数据处理领域,特别涉及一种训练翻译模型的方法、训练判别模型的方法、查询改写方法、搜索方法、装置、存储介质、电子设备。
背景技术:
1、在搜索场景中,在搜索初期总会由于搜索资源不足存在供给不足问题,这种情况下对于用户的某些query(搜索文本),库中没有能完全满足用户需求的内容,如果这时不展示结果或者展示不相关的结果,对用户的留存以及用户的搜索体验都是巨大的损伤。同时由于query和doc(文章)表述不一致的问题,且搜索召回很依赖文章全匹配,所以也会有很多query召回不了理想结果。
2、因此,会出现因为资源不足而导致的搜索无少结果问题,或者由于query和doc表述不一致而导致的搜索无少结果问题。
3、对此,目前的搜索场景中,近义词改写是搜索系统中常见的为了缓解query和doc表述不一致所导致的漏招问题而采用的优化方案,通过将query改写为跟它语义一致但表述不一致的改写query,再去召回匹配的doc。最常见的方法是基于同义词替换的方法,另外还有基于query的改写方法。
4、基于term的同义词改写方法基本上是基于同义词等知识库和先数据挖掘再人工标注的方法构建同义词表,同义词等知识库一般是一些通用的资源,对于特定领域的搜索场景覆盖率很低,而基于人工标注的方法又特别耗费人力资源。其次,基于term的同义词改写方法仅仅使用词替换,还需要后判别过程。
5、基于query的改写方法通常有用户行为挖掘、向量召回等方法。用户行为挖掘通常只能覆盖到一部分数据,对于低频query并不能产生效果。向量召回一方面需要巨大的存储空间,另一方面候选query库的选取也十分重要。
技术实现思路
1、本技术实施例提供了一种训练近义词改写模型的方法、近义词改写方法、装置、存储介质、电子设备以及计算机程序产品。
2、第一方面,本技术实施例提供了一种训练翻译模型的方法,用于电子设备,所述方法包括:
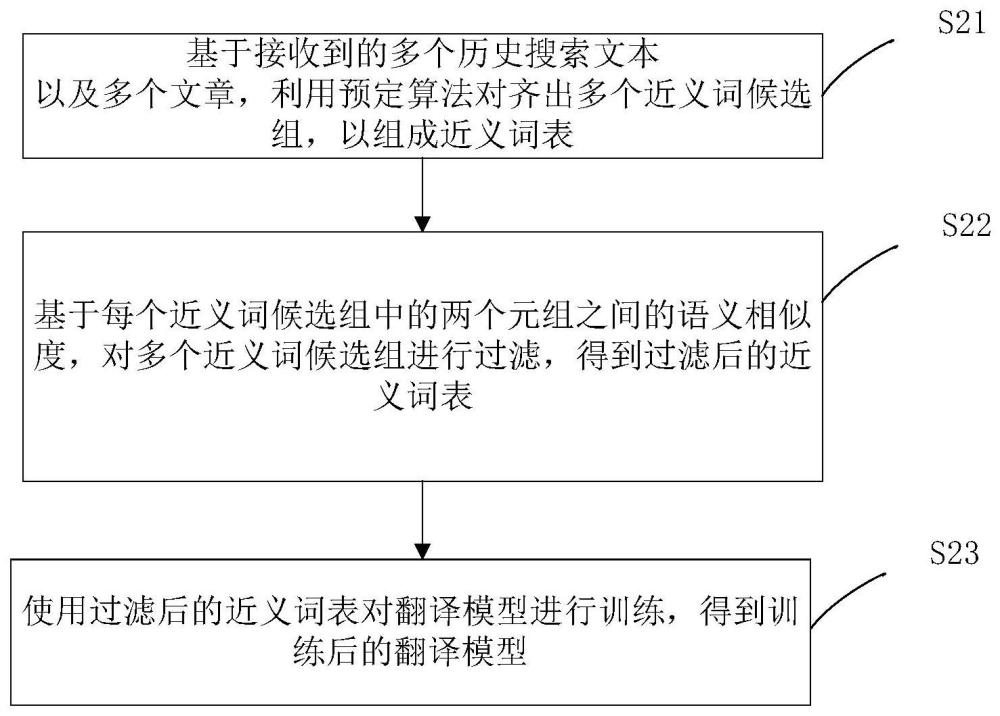
3、挖掘步骤,基于接收到的多个历史搜索文本以及多个文章,利用预定算法对齐出多个近义词候选组,以组成近义词表;
4、过滤步骤,基于每个近义词候选组中的两个元组之间的语义相似度,对所述多个近义词候选组进行过滤,得到过滤后的近义词表;
5、第一训练步骤,使用所述过滤后的近义词表对翻译模型进行训练,得到训练后的翻译模型。
6、在上述第一方面的一种可能的实现中,在所述挖掘步骤中,利用同义词挖掘算法,从所述多个历史搜索文本和所述多个文章挖掘出多个搜索文本对,并利用词对齐算法和上下文一致规则算法,从每个所述搜索文本对对齐出所述近义词候选组。
7、在上述第一方面的一种可能的实现中,在所述过滤步骤中,使用词向量模型来计算每个近义词候选组中的两个元组之间的所述语义相似度,并将所述语义相似度小于预定阈值的近义词候选组过滤掉。
8、在上述第一方面的一种可能的实现中,进一步包括:利用反义词表,将两个元组的语义相反的近义词候选组过滤掉。
9、在上述第一方面的一种可能的实现中,基于每个近义词候选组的频次来确定针对每个近义词候选组的所述预定阈值,
10、其中,所述频次是对齐出同一近义词候选组的所述历史搜索文本和所述文章的总数量。
11、第二方面,本技术实施例提供了一种训练判别模型的方法,用于电子设备,所述方法包括:
12、改写步骤,对原始搜索文本进行改写,得到多个改写候选;
13、计算步骤,计算所述原始搜索文本与每个改写候选之间的相似度得分,得到多个所述相似度得分;
14、第二训练步骤,使用多个所述相似度得分对构建的判别模型进行训练,得到训练后的判别模型。
15、在上述第二方面的一种可能的实现中,所述计算步骤包括:
16、对于每个所述改写候选,
17、使用所述改写候选,召回多个匹配文章;
18、计算所述原始搜索文本和每个所述匹配文章之间的相关性值,得到多个所述相关性值;
19、取多个所述相关性值的聚合值作为所述原始搜索文本和所述改写候选之间的所述相似度得分。
20、在上述第二方面的一种可能的实现中,所述计算步骤包括:
21、对于每个所述改写候选,
22、获取与所述原始搜索文本对应的多个历史点击文章;
23、统计所述改写候选中与所述原始搜索文本相同的词在所述多个历史点击文章中出现的第一频次,并统计所述改写候选中与所述原始搜索文本不同的词在所述多个历史点击文章中出现的第二频次;
24、基于所述第一频次和第二频次,计算得到所述原始搜索文本与所述改写候选之间的所述相似度得分。
25、在上述第二方面的一种可能的实现中,所述判别模型是决策树模型。
26、第三方面,本技术实施例提供了一种查询改写方法,用于电子设备,所述方法包括:
27、获取当前搜索文本;
28、将所述当前搜索文本输入根据第一方面所述的训练后的翻译模型,得到至少一个当前改写候选;
29、将所述当前搜索文本和多个所述当前改写候选输入根据第二方面所述的训练后的判别模型,从而将预定数量的所述当前改写候选作为所述当前搜索文本的改写搜索文本。
30、第四发明,本技术实施例提供了一种训练翻译模型的装置,所述装置包括:
31、挖掘单元,基于接收到的多个历史搜索文本以及多个文章,利用预定算法对齐出多个近义词候选组,以组成近义词表;
32、过滤单元,基于每个近义词候选组中的两个元组之间的语义相似度,对所述多个近义词候选组进行过滤,得到过滤后的近义词表;
33、第一训练单元,使用所述过滤后的近义词表对翻译模型进行训练,得到训练后的翻译模型。
34、第五发明,本技术实施例提供了一种训练判别模型的装置,所述装置包括:
35、改写单元,对原始搜索文本进行改写,得到多个改写候选;
36、计算单元,计算所述原始搜索文本与每个所述改写候选之间的相似度得分,得到多个所述相似度得分;
37、第二训练单元,使用多个所述相似度得分对构建的判别模型进行训练,得到训练后的判别模型。
38、第六方面,本技术实施例提供了一种查询改写装置,所述装置包括:
39、获取单元,获取当前搜索文本;
40、改写单元,将所述当前搜索文本输入根据第四方面所述的训练后的翻译模型,得到至少一个当前改写候选;
41、判别单元,将所述当前搜索文本和多个所述当前改写候选输入根据第五方面所述的训练后的判别模型,从而将预定数量的所述当前改写候选作为所述当前搜索文本的改写搜索文本。
42、第七方面,本技术实施例提供了一种搜索方法,用于电子设备,所述方法包括:
43、获取用户输入的搜索文本;
44、使用根据第三方面所述的查询改写方法,得到所述搜索文本的至少一个改写搜索文本;
45、使用至少一个改写搜索文本,获取匹配的搜索结果,并将搜索结果返回给所述用户。
46、第八方面,本技术实施例提供了一种计算机程序产品,包括计算机可执行指令,所述指令被处理器执行以实施第一方面所述的训练翻译模型的方法、或第二方面所述的训练判别模型的方法、或第三方面所述的查询改写方法、或第七方面所述的搜索方法。
47、第九方面,本技术实施例提供了一种计算机可读存储介质,所述存储介质上存储有指令,所述指令在计算机上执行时使所述计算机执行第一方面所述的训练翻译模型的方法、或第二方面所述的训练判别模型的方法、或第三方面所述的查询改写方法、或第七方面所述的搜索方法。
48、第十方面,本技术实施例提供了一种电子设备,包括:一个或多个处理器;一个或多个存储器;其中,所述一个或多个存储器存储有一个或多个程序,当所述一个或者多个程序被所述一个或多个处理器执行时,使得所述电子设备执行第一方面所述的训练翻译模型的方法、或第二方面所述的训练判别模型的方法、或第三方面所述的查询改写方法、或第七方面所述的搜索方法。
49、本发明中,使用如上所述的训练后的翻译模型,保证了长尾query的覆盖率,同时,通过使用轻量的训练后的判别模型来选择出最佳的改写搜索文本,解决了搜索无少结果的问题,并保证了搜索结果的准确性和线上的效率。另外,本发明中不依赖于人工标注,而是利用了语义相似度来过滤近义词表,因此提高了算法的实现效率。
- 还没有人留言评论。精彩留言会获得点赞!