考虑不确定状态的序列化决策智能体实现系统及方法
本发明涉及的是一种神经网络应用领域的技术,具体是一种考虑不确定状态的序列化决策智能体实现系统及方法。
背景技术:
1、在当前的大数据和信息化背景下,受限于海量数据和用户有限的手动调控能力,往往需要序列化决策智能体协助用户完成各种优化目标。如在工业自动化领域、互联网工业领域和自动驾驶领域,用户会利用序列化决策智能体进行实时调控达成工业参数调控、流量分配、自动驾驶等目标。序列化决策智能体的效率和优化问题非常重要。
2、构建序列化决策智能体的问题,其任务是在未来环境未知的前提下,根据观测到的反馈信息,实时调整策略来提升最终优化效果。近年来,很多基于该思想的序列化决策方法被提出。这些构建方法大都假设决策智能体能够实时观测到真实反馈,从而合理的调整实时决策策略。但是,现有的决策智能体,都忽略真实环境中的反馈延迟性带来的特征不确定性,不论这些策略调控方法的理论效果如何,若其无法获得真实的反馈,决策的效果便会大打折扣。
3、反馈特征不确定性,是线上真实环境区别于离线理想环境的一条重要性质。它是由真实环境反馈的复杂性和随机性所决定的。以互联网工业领域为例,独立运营者们使用自动决策智能体制定策略,从而竞争流量来达成转化效果。但是竞得的流量是否会发生转化行为,转化行为何时发生,都具有较大的不确定性。转化行为的延迟可长达几小时甚至几天,这对具有高反馈实时性要求的序列化决策智能体的决策效果有较大的影响,会带来优化效果的损失,并且增加超限风险。
4、所述的独立运营者是指互联网中具有流量需求的特殊用户,其会和其他独立运营者竞争流量,以达成引流效果,从而达成自己的转化目标。
5、所述的竞争过程是指平台接收到每位独立运营者的竞争策略后,会按一定的规律分配流量,并扣除胜者相应的费用。
6、所述的转化是指独立运营者引流的诉求,如“带货网红”类独立运营者定义的转化行为是流量发生购买行为。
7、所述的超限风险是指独立运营者会为决策智能体设置单位转化成本,即竞得一次转化所需的花费。而因为种种原因,序列化决策智能体的竞拍结果导致真实的单位转化成本超过独立运营者设置的预期值,则被称为超限现象。超限现象意味着序列化决策智能体没有很好的完成目标任务,是其设计中应当考虑的重点。
技术实现思路
1、本发明针对现有技术存在的上述不足,提出一种考虑不确定状态的序列化决策智能体实现系统及方法,在进行序列化决策时利用特征分布与强化学习方法,通过构建智能体,以较低的复杂度成本,显著的提高智能体序列化决策时的优化效果。
2、本发明是通过以下技术方案实现的:
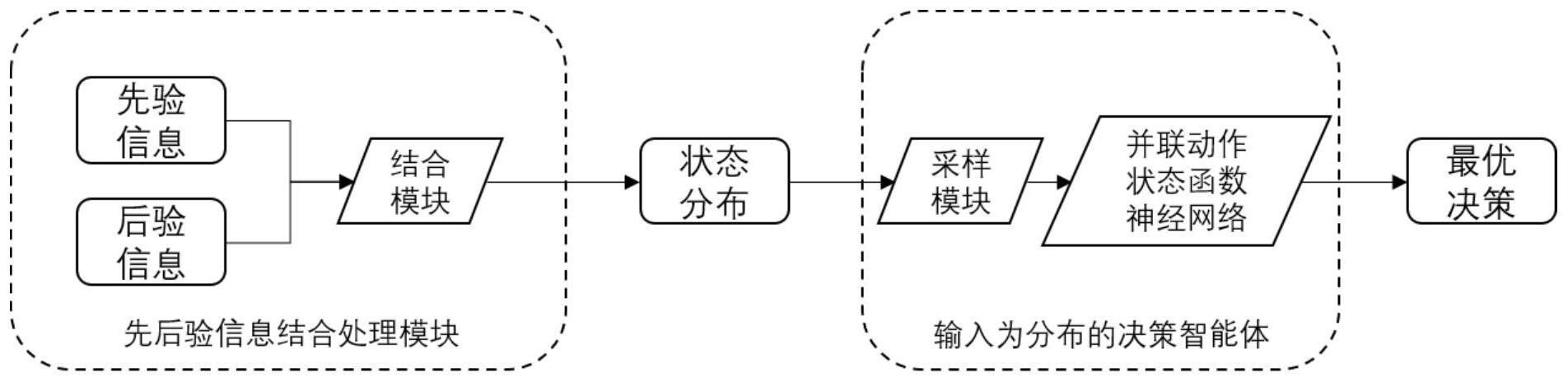
3、本发明涉及一种考虑不确定状态的序列化决策智能体实现系统,包括:前后验信息结合处理模块、输入为分布的决策智能体模块,其中前后验信息结合处理模块根据先验的预估信息和后验的真实反馈信息,进行两种信息的综合利用处理,得到转化量和单位转化成本参数的分布;输入为分布的决策智能体模块根据单位转化成本参数的分布信息,从其中进行采样获得对应的离散分布,并将分布输入并联的动作状态神经网络中,就得到参考不确定状态下的最优决策。
4、本发明涉及一种基于上述系统的考虑不确定状态的序列化决策智能体实现方法,包括:
5、步骤1、结合前链路传递的先验转化信息、智能体真实观测的后验转化信息和即时反馈信息,利用转化延迟分布模型得到当前智能体竞得流量的单位转化成本的分布。
6、所述的前链路传递的先验转化信息是指:互联网工业领域中,在智能体决策之前,平台会提供给其某一条流量i的预估转化率pcvri以供参考。
7、所述的真实观测的后验转化信息是指:在智能体竞得一条流量后,在某一时刻观测该流量转化结果,若可以观测到流量转化,称为正后验信息;尚未观测到该流量转化,称为负后验信息。
8、所述的即时反馈信息是指:智能体的实时花费,决策周期剩余的时间等信息,这些信息具有即时反馈性和确定性。
9、所述的转化延迟分布模型是指:在流量最终转化的前提下,流量转化延迟的分布,即当流量最终发生转化,其转化延迟小于τi的概率,具体为:ht(τi)=p(t≤τi),其中:ht(τi)为转化延迟函数,表示发生转化的流量中,其可能的转化延迟的分布;τi为从流量i点击到当前观测所经过的时间。
10、步骤2、对序列化决策问题进行形式化建模,并利用强化学习方式获得确定状态下的解。
11、所述的形式化建模指是指:在离线阶段将所有流量属性已知的决策问题建模成线性规划问题,在存在预算约束与单位转化成本约束的前提下,智能体尽量多的选取高性价比的流量,具体为:优化目标:限制条件:其中:n为竞争周期中的流量总数,xi为是否选择竞得某条流量i,vi为流量i的价值vi=pctri*pcvri,ci为竞得流量i的花销,b为独立运营者的预算,tcpa为独立运营者预设的目标单位转化成本。
12、所述的线性规划问题在离线环境中存在最优解,最优决策形式为其中λ1和λ2为线性规划问题对偶问题中,两个限制条件对应的对偶因子。
13、所述的所有流量属性已知是指利用往期数据构建的模拟环境,其中智能体能够获知全天内的所有流量的价值信息vi。
14、所述的强化学习方式是指:将形式化建模得到的线性规划问题进一步建模为马尔科夫决策过程(mdp)问题,再使用策略(policy)深度神经网络和动作状态函数(q value)深度神经网络近似拟合该决策过程,具体为:对于t+1时刻的状态st+1,其可能的分布仅与t时刻的状态st及智能体的决策动作at有关,与t时刻之前的所有状态或智能体决策动作均无关,t时刻的状态st是指智能体对于当前环境与自身性质的认知。
15、所述的策略深度神经网络根据智能体当前所处状态,得到智能体策略动作,当智能体获知当前的状态s时,其参考该深度神经网络确定决策动作。
16、所述的动作状态函数深度神经网络根据智能体当前所处状态与智能体的决策动作,得到动作状态函数值的深度神经网络,当智能体获得当前的状态s时,其可以获知每一种决策a所对应的剩余时间收益和,为q(s,a),其中q(s,a)即为对应状态s和决策动作a下的动作状态函数。
17、步骤3、考虑当前状态的不确定性,参考当前状态的离散分布,利用不确定状态理论,结合强化学习模型中的动作状态函数深度神经网络,构建序列化决策智能体用于协助独立流量运营者在平台开展的流量分配环境中进行资源分配决策。
18、所述的状态不确定性是指:在真实环境中,某些物理量的反馈存在延迟(如单位转化成本信息),决策智能体无法获取当前的准确状态。而决策智能体依赖实时状态进行决策。可以使用对应的分布信息表达该物理量的不确定性。
19、所述的离散分布是指:对于有限的n个可能的状态,智能体可以获知其当前所处特定状态si,的概率b(si),i∈{1,2,…,n}。
20、所述的不确定状态理论是指:其中:a*为当前最优的出决策,b(s)为可能状态的离散分布,该最优的决策对所有可能状态负责。
21、技术效果
22、本发明利用转化延迟联系前后验信息;输入为分布形式的能够处理不确定状态的决策模型。相比现有技术,本发明达成了对于相关参数的更准确估计,并构建出参数的可能分布;达成了更加稳定和高效的决策方式,独立运营者竞得流量的转化效果,并且可以减少独立运营者的超限现象。
- 还没有人留言评论。精彩留言会获得点赞!