数据匹配方法、装置、电子设备及计算机可读存储介质与流程
本技术涉及多媒体,具体而言,本技术涉及一种数据匹配方法、装置、电子设备及计算机可读存储介质。
背景技术:
1、多媒体技术是指通过计算机对文字、数据、图形、图像、动画、声音等多种媒体信息进行综合处理和管理,以便使用者通过多种感官与计算机进行实时信息交互的技术;互联网的发展给人们带来巨大的多媒体数据海洋,如何高效的管理和访问多媒体海量数据,是多媒体技术研究中的重点。
2、多媒体数据匹配广泛应用于多媒体检索和多媒体问答等领域,以视频配乐为例,可以通过多媒体数据检索为视频匹配适合的音频,以丰富视频的呈现效果、增强视频内容的表达能力和吸引力。
3、现有技术中,通常采用tf-idf(term frequency–inverse document frequency,基于词频和逆文本频率指数统计方法)算法,将视频标签映射到对应的音频上,以对音频打上视频标签,通过视频和音频的标签交集筛选出强相关的视频音频对,进而完成视频数据与视频数据的匹配。但是,上述基于标签的匹配方法中匹配粒度粗,可能会导致热门音频的重复匹配即大部分视频数据均匹配到相同的音频,无法保证数据匹配的多样化和精确度。
技术实现思路
1、本技术实施例提供了一种数据匹配方法、装置、电子设备及计算机可读存储介质,可以解决数据匹配精确度不高的问题。所述技术方案如下:
2、根据本技术实施例的一个方面,提供了一种数据匹配方法,该方法包括:
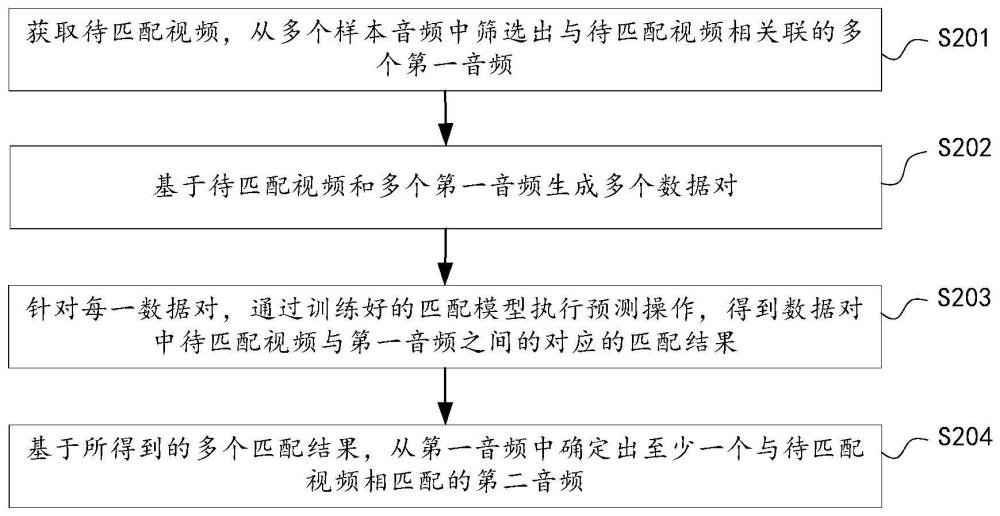
3、获取待匹配视频,从多个样本音频中筛选出与待匹配视频相关联的多个第一音频;
4、基于待匹配视频和多个第一音频生成多个数据对;其中,每一数据对包括待匹配视频和一个对应的第一音频;
5、针对每一数据对,通过训练好的匹配模型执行预测操作,得到数据对中待匹配视频与第一音频之间的对应的匹配结果;
6、基于所得到的多个匹配结果,从第一音频中确定出至少一个与待匹配视频相匹配的第二音频;
7、其中,预测操作包括:
8、提取待匹配视频的画面特征,并提取第一音频的音频特征和数据对的文本属性的文本特征;
9、将音频特征、画面特征中的至少一项与文本特征进行特征融合,得到至少一个融合特征;
10、根据至少一个融合特征计算音频特征和画面特征的相似度;
11、基于相似度确定待匹配视频与第一音频之间的匹配结果。
12、在一个可能的实现方式中,上述融合特征包括根据文本特征和音频特征生成的第一融合特征,和根据文本特征和画面特征生成的第二融合特征;
13、根据至少一个融合特征计算音频特征和画面特征的相似度,包括:
14、将第一特征与第二特征的特征差值信息,作为相似度;其中,当第一特征为第一融合特征时,第二特征为画面特征或者第二融合特征;当第一特征为音频特征时,第二特征为第二融合特征。
15、在一个可能的实现方式中,上述特征差值信息是基于如下方式计算得到的:
16、确定音频模态的第一中心向量,和视频模态的第二中心向量;
17、将第一特征映射到第一中心向量,得到音频映射向量;
18、将第二特征映射到第二中心向量,得到视频映射向量;
19、将音频映射向量和视频映射向量的乘积作为特征差值信息。
20、在一个可能的实现方式中,上述匹配模型是通过如下方式训练得到的:
21、获取多个第一样本数据对和第二样本数据对;其中,每一第一样本数据对或第二样本数据对包括一样本视频和一个样本视频对应的样本音频;第一样本数据对的标准匹配结果表征样本视频相对于样本音频的匹配度,第二样本数据对的标准匹配结果表征样本音频相对于样本视频的匹配度;
22、通过第一样本数据对和第二样本数据对对初始匹配模型进行至少一次优化操作,直至训练总损失符合预设条件,将训练总损失符合预设条件的初始匹配模型作为匹配模型;
23、其中,优化操作包括:
24、通过初始匹配模型分别预测针对第一样本数据对的第一预测匹配结果和针对第二样本数据对的第二预测匹配结果;
25、基于第一预测匹配结果和第一样本数据对的标准匹配结果的差异确定第一损失;
26、基于第二预测匹配结果和第二样本数据对的标准匹配结果的差异确定第二损失;
27、基于第一损失和第二损失确定训练总损失。
28、在一个可能的实现方式中,基于第一损失和第二损失确定训练总损失,包括:
29、针对第一样本数据对和第二样本数据对中的至少一项,获取对应样本视频的样本画面特征;
30、根据样本画面特征进行特征分类,得到样本视频的分类结果;
31、将分类结果和样本视频的标准分类结果的差值作为第三损失;
32、将第一损失、第二损失和第三损失的加和作为训练总损失。
33、在一个可能的实现方式中,上述标准匹配结果是基于如下方式确定的:
34、从特定应用程序的历史记录中,获取多个样本视频和样本音频;
35、获取与每一样本视频对应的多个样本音频作为第一样本数据对,获取与每一样本音频对应的多个样本视频作为第二样本数据对;
36、针对每一第一样本数据对,计算样本视频相对于对应样本音频的第一匹配率;基于预设对象针对特定应用程序的反馈操作信息计算样本视频的第一播放数据;基于第一匹配率和第一播放数据确定第一样本数据对的标准匹配结果;
37、针对每一第二样本数据对,计算样本音频相对于对应样本视频的第二匹配率;基于预设对象针对特定应用程序的反馈操作信息计算样本音频的第二播放数据;当第二匹配率和第二播放数据确定第二样本数据对的标准匹配结果。
38、在另一个可能的实现方式中,上述提取待匹配视频的画面特征,包括:
39、将待匹配视频划分为多个视频片段;
40、从每一视频片段中抽取一画面帧,分别提取每一画面帧的局部特征;
41、针对每一局部特征进行降维分解,得到多个局部分解特征;
42、将多个局部分解特征进行全局聚合,得到画面特征。
43、根据本技术实施例的另一个方面,提供了一种数据匹配装置,该装置包括:
44、筛选模块,用于获取待匹配视频,从多个样本音频中筛选出与待匹配视频相关联的多个第一音频;
45、生成模块,用于基于待匹配视频和多个第一音频生成多个数据对;其中,每一数据对包括待匹配视频和一个对应的第一音频;
46、预测模块,用于针对每一数据对,通过训练好的匹配模型执行预测操作,得到数据对中待匹配视频与第一音频之间的对应的匹配结果;
47、其中,预测操作包括:
48、提取待匹配视频的画面特征,并提取第一音频的音频特征和数据对的文本属性的文本特征;将音频特征、画面特征中的至少一项与文本特征进行特征融合,得到至少一个融合特征;根据至少一个融合特征计算音频特征和画面特征的相似度;基于相似度确定待匹配视频与第一音频之间的匹配结果;
49、确定模块,用于基于所得到的多个匹配结果,从第一音频中确定出至少一个与待匹配视频相匹配的第二音频。
50、在一个可能的实现方式中,上述融合特征包括根据文本特征和音频特征生成的第一融合特征,和根据文本特征和画面特征生成的第二融合特征;
51、上述预测模块在根据至少一个融合特征计算音频特征和画面特征的相似度时,用于:
52、将第一特征与第二特征的特征差值信息,作为相似度;其中,当第一特征为第一融合特征时,第二特征为画面特征或者第二融合特征;当第一特征为音频特征时,第二特征为第二融合特征。
53、在一个可能的实现方式中,上述特征差值信息是基于如下方式计算得到的:
54、确定音频模态的第一中心向量,和视频模态的第二中心向量;
55、将第一特征映射到第一中心向量,得到音频映射向量;
56、将第二特征映射到第二中心向量,得到视频映射向量;
57、将音频映射向量和视频映射向量的乘积作为特征差值信息。
58、在一个可能的实现方式中,上述匹配模型是通过如下方式训练得到的:
59、获取多个第一样本数据对和第二样本数据对;其中,每一第一样本数据对或第二样本数据对包括一样本视频和一个样本视频对应的样本音频;第一样本数据对的标准匹配结果表征样本视频相对于样本音频的匹配度,第二样本数据对的标准匹配结果表征样本音频相对于样本视频的匹配度;
60、通过第一样本数据对和第二样本数据对对初始匹配模型进行至少一次优化操作,直至训练总损失符合预设条件,将训练总损失符合预设条件的初始匹配模型作为匹配模型;
61、其中,优化操作包括:
62、通过初始匹配模型分别预测针对第一样本数据对的第一预测匹配结果和针对第二样本数据对的第二预测匹配结果;
63、基于第一预测匹配结果和第一样本数据对的标准匹配结果的差异确定第一损失;
64、基于第二预测匹配结果和第二样本数据对的标准匹配结果的差异确定第二损失;
65、基于第一损失和第二损失确定训练总损失。
66、在一个可能的实现方式中,上述预测模块在基于第一损失和第二损失确定训练总损失时,用于:
67、针对第一样本数据对和第二样本数据对中的至少一项,获取对应样本视频的样本画面特征;
68、根据样本画面特征进行特征分类,得到样本视频的分类结果;
69、将分类结果和样本视频的标准分类结果的差值作为第三损失;
70、将第一损失、第二损失和第三损失的加和作为训练总损失。
71、在一个可能的实现方式中,上述标准匹配结果是基于如下方式确定的:
72、从特定应用程序的历史记录中,获取多个样本视频和样本音频;
73、获取与每一样本视频对应的多个样本音频作为第一样本数据对,获取与每一样本音频对应的多个样本视频作为第二样本数据对;
74、针对每一第一样本数据对,计算样本视频相对于对应样本音频的第一匹配率;基于预设对象针对特定应用程序的反馈操作信息计算样本视频的第一播放数据;基于第一匹配率和第一播放数据确定第一样本数据对的标准匹配结果;
75、针对每一第二样本数据对,计算样本音频相对于对应样本视频的第二匹配率;基于预设对象针对特定应用程序的反馈操作信息计算样本音频的第二播放数据;当第二匹配率和第二播放数据确定第二样本数据对的标准匹配结果。
76、在另一个可能的实现方式中,上述预测模块在提取待匹配视频的画面特征时,用于:
77、将待匹配视频划分为多个视频片段;
78、从每一视频片段中抽取一画面帧,分别提取每一画面帧的局部特征;
79、针对每一局部特征进行降维分解,得到多个局部分解特征;
80、将多个局部分解特征进行全局聚合,得到画面特征。
81、根据本技术实施例的另一个方面,提供了一种电子设备,该电子设备包括:存储器、处理器及存储在存储器上的计算机程序,上述处理器执行计算机程序以实现本技术实施例第一方面所示方法的步骤。
82、根据本技术实施例的再一个方面,提供了一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现本技术实施例第一方面所示方法的步骤。
83、根据本技术实施例的一个方面,提供了一种计算机程序产品,其包括计算机程序,该计算机程序被处理器执行时实现本技术实施例第一方面所示方法的步骤。
84、本技术实施例提供的技术方案带来的有益效果是:
85、本技术实施例基于待匹配视频与多个第一音频生成多个数据对,通过训练好的匹配模型针对每一数据对执行预测操作,得到数据对中待匹配视频与第一音频之间的对应的匹配结果,并根据所得到的多个匹配结果,从第一音频中确定出至少一个与待匹配视频相匹配的第二音频。其中,在执行预测操作时,将从数据对中提取得到的音频特征、画面特征中的至少一项与文本特征进行特征融合,得到至少一个融合特征;并根据至少一个融合特征计算音频特征和画面特征的相似度;进而完成基于特征融合和特征相似度计算的音视频数据匹配。本技术实施例通过多模态特征信息的特征融合提升了匹配结果的可靠性,实现了从视频、音频和文本多维度进行数据匹配,提升了视频和音频的内容贴合度。
86、同时,区别于现有技术中通过历史匹配标签的粗粒度匹配所导致的热门音频的重复匹配,本技术中的第一音频是从多个样本音频中筛选出的与待匹配视频相关联的样本音频,可以基于音频的类型、歌词、曲风等多方面进行关联筛选,有效避免音频数据的长尾效应的加剧,增强了数据匹配的多样化和精细程度。
- 还没有人留言评论。精彩留言会获得点赞!