联邦学习预测阶段隐私保护方法及系统与流程
本发明涉及联邦学习领域,尤其涉及一种联邦学习预测阶段隐私保护方法及系统。
背景技术:
1、联邦学习federated learning-fl是一种分布式机器学习技术,核心思想是通过在多个拥有本地数据的数据源之间进行分布式模型训练,在不需要交换本地个体或样本数据前提下,仅通过交换模型参数或中间结果的方式,构建基于虚拟融合数据下的全局模型,实现数据隐私保护和数据共享计算的平衡,即“数据可用不可见”、“数据不动模型动”的应用新范式。根据训练数据在不同参与方之间的数据特征空间和样本id空间的分布情况,联邦学习可被分为横向联邦学习、纵向联邦学习、迁移联邦学习。
2、本发明解决的问题是:目前,现有纵向联邦学习技术侧重点在于实现模型训练阶段中数据集及模型相关敏感数据(如梯度、距离聚类中心的距离等)的隐私保护,却忽略了实际应用场景中使用最为频繁、体现联邦学习模型应用价值的联邦预测阶段敏感数据(如预测用户id、单侧模型预测值)的隐私和安全问题。一方面,由于纵向联邦学习模型训练阶段结束后,各参与方只能得到联邦学习模型的一部分,因此在后续的预测阶段仍然需要各参与方共同联合参与完成;另一方面,在实际应用场景中,提出联邦预测需求的参与方往往不希望其他参与方知晓其想要预测用户id,所以,有必要在联邦预测阶段考虑数据使用过程中的隐私问题。比如借贷机构和征信机构合作联邦预测某个借款人的信用,借贷机构并不想让对方知道该借款人有借款需求,否则征信机构可以将借款人的信息提供给其他借贷机构,同时,征信机构也不想让借贷机构知道其私有模型的预测值。
3、因此现有技术中联邦预测阶段敏感数据隐私性、安全性不足的问题就成为本领域技术人员亟待解决的一个问题。
技术实现思路
1、为解决上述问题,本发明提供联邦学习预测阶段隐私保护方法及系统,通过在预测阶段基于同态加密及盲签名算法对敏感数据进行加密等密码学处理,并实现了去中心化的计算服务,使数据服务方及数据使用方之间传输的敏感数据安全性及隐私性更高,以解决现有技术中联邦预测阶段敏感数据隐私性、安全性不足的问题。
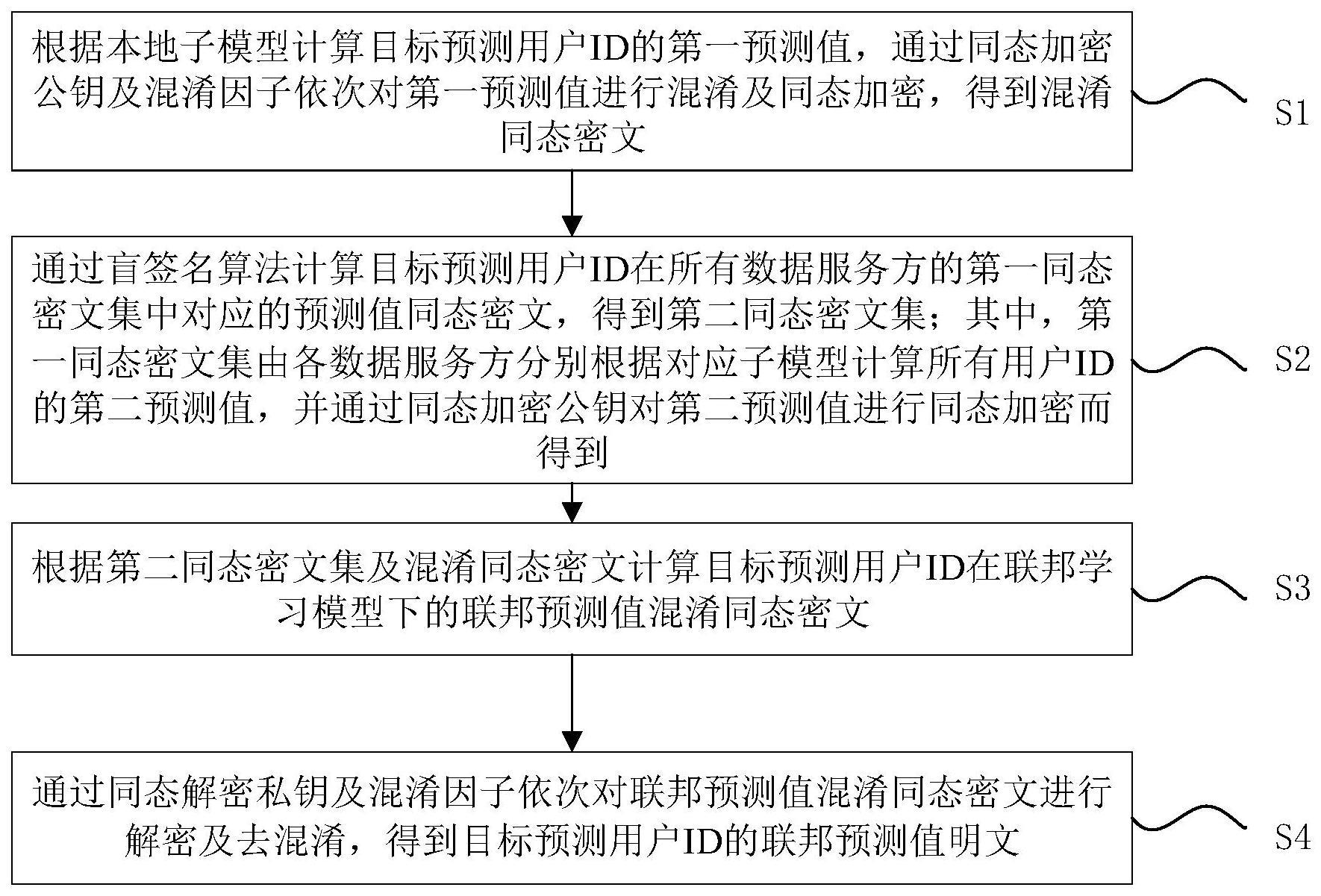
2、为达到上述目的,本发明实施例提供了一种联邦学习预测阶段隐私保护方法,包括:根据本地子模型计算目标预测用户id的第一预测值,通过同态加密公钥及混淆因子依次对所述第一预测值进行混淆及同态加密,得到混淆同态密文;通过盲签名算法计算目标预测用户id在所有数据服务方的第一同态密文集中对应的预测值同态密文,得到第二同态密文集;其中,所述第一同态密文集由各数据服务方分别根据对应子模型计算所有用户id的第二预测值,并通过所述同态加密公钥对所述第二预测值进行同态加密而得到;根据所述第二同态密文集及混淆同态密文计算目标预测用户id在联邦学习模型下的联邦预测值混淆同态密文;通过同态解密私钥及混淆因子依次对所述联邦预测值混淆同态密文进行解密及去混淆,得到目标预测用户id的联邦预测值明文。
3、进一步可选的,所述通过盲签名算法计算目标预测用户id在所有数据服务方的第一同态密文集中对应的预测值同态密文,包括:根据盲因子计算目标预测用户id的盲化值,并将所述盲化值发送至所述数据服务方;接收数据服务方发送的盲化值签名、第一同态密文集及被预测用户id签名集;其中,所述盲化值签名由所述数据服务方对所述盲化值进行签名得到;所述被预测用户id签名集由所述数据服务方预先对所有被预测用户id进行签名得到;根据所述盲因子对所述盲化值签名进行脱盲计算,得到待匹配签名值;将所述待匹配签名值与所述被预测用户id签名集中的预设签名值进行匹配,确定匹配成功的预设签名值对应的索引值;根据所述索引值在所述第一同态密文集中查询对应位置的预测值同态密文,将其作为所述目标预测用户id对应的预测值同态密文。
4、进一步可选的,所述根据所述第二同态密文集及混淆同态密文集计算目标每个被预测用户id在联邦学习模型下的联邦预测值混淆同态密文,包括:提取所述第二同态密文集中目标预测用户id对应的在所有数据服务方对应的预测值同态密文及其所述混淆同态密文;通过聚合函数根据目标预测用户id对应的预测值同态密文及混淆同态密文,计算得到目标预测用户id在联邦学习模型下的联邦预测值混淆同态密文;其中,所述聚合函数根据模型计算需求及同态加密算法类型确定。
5、进一步可选的,所述通过同态解密私钥及混淆因子依次对所述联邦预测值混淆同态密文进行解密及去混淆,得到目标预测用户id的联邦预测值明文,包括:将所述联邦预测值混淆同态密文发送至同态加密公钥所属数据服务方;接收所述同态加密公钥所属数据服务方发送的联邦预测值混淆明文;其中,所述联邦预测值混淆明文由所述同态加密公钥所属数据服务方通过所述同态解密私钥解密得到;通过所述混淆因子对所述联邦预测值混淆明文进行去混淆,得到目标预测用户id的联邦预测值明文。
6、进一步可选的,所述同态加密采用以下任一种算法类型实现:加法同态加密算法、乘法同态加密算法及全同态算法。
7、另一方面,本发明实施例还提供了一种联邦学习预测阶段隐私保护系统,包括:加密模块,用于根据子模型计算目标预测用户id的第一预测值,通过所述同态加密公钥及混淆因子对所述第一预测值进行混淆同态加密,得到混淆同态密文;同态密文获取模块,用于通过盲签名算法计算目标被预测用户id在所有数据服务方的第一同态密文集中对应的预测值同态密文,得到第二同态密文集;其中,所述第一同态密文集由各数据服务方分别根据对应子模型计算所有用户id的第二预测值,并通过同态加密公钥对所述第二预测值进行同态加密而得到;联邦混淆同态密文计算模块,用于根据所述第二同态密文集及混淆同态密文计算目标预测用户id在联邦学习模型下的联邦预测值混淆同态密文;预测值明文计算模块,用于通过同态解密私钥及混淆因子依次对所述联邦预测值混淆同态密文进行解密及去混淆,得到目标预测用户id的预测值明文。
8、进一步可选的,所述同态密文获取模块包括:盲化子模块,用于根据盲因子计算目标预测用户id的盲化值,并将所述盲化值发送至所述数据服务方;信息接收子模块,用于分别接收所有数据服务方发送的盲化值签名、第一同态密文集及用户id签名集;其中,所述盲化值签名由所述数据服务方对所述盲化值进行签名得到;所述用户id签名集由所述数据服务方预先对所有用户id进行签名得到;脱盲子模块,用于根据所述盲因子对所述盲化值签名进行脱盲计算,得到待匹配签名值;匹配子模块,用于将所述待匹配签名值与所述用户id签名集中的预设签名值进行匹配,确定匹配成功的预设签名值对应的索引值;索引子模块,用于根据所述索引值在所述第一同态密文集中查询对应位置的预测值同态密文,将其作为所述目标预测用户id对应的预测值同态密文。
9、进一步可选的,所述联邦混淆同态密文计算模块包括:数据提取子模块,用于提取所述第二同态密文集中目标预测用户id在所有数据服务方对应的预测值同态密文及其所述混淆同态密文;联邦混淆同态密文确定子模块,用于通过聚合函数根据目标预测用户id对应的所有预测值同态密文及混淆同态密文,计算得到目标预测用户id在联邦学习模型下的联邦预测值混淆同态密文;其中,所述聚合函数根据模型计算需求及同态加密算法类型确定。
10、进一步可选的,所述预测值明文计算模块,包括:数据发送子模块,用于将所述联邦预测值混淆同态密文发送至同态加密公钥所属数据服务方;解密子模块,用于接收所述同态加密公钥所属数据服务方发送的联邦预测值混淆明文;其中,所述联邦预测值混淆明文由所述同态加密公钥所属数据服务方通过所述同态解密私钥解密得到;去混淆子模块,用于通过所述混淆因子对所述联邦预测值混淆明文进行去混淆,得到目标预测用户id的联邦预测值明文。
11、另一方面,本发明实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,所述程序被处理器执行时实现上述的联邦学习预测阶段隐私保护方法。
12、上述技术方案具有如下有益效果:在联邦学习预测阶段,通过同态加密和盲签名技术进行交互,并在交互过程中对数据进行加密等密码学算法处理,提高了数据传输过程中的隐私性;另一方面,该方案是去中心化的不需要第三方提供计算服务,解决了联邦学习各参与方数据的安全与隐私问题,提高了安全性。
- 还没有人留言评论。精彩留言会获得点赞!