用于动态识别手术托盘和其上包含的物品的系统和方法与流程
本发明的实施例的方面涉及计算机视觉领域,并且包括被配置为自动地和准确地进行以下操作的系统和方法:当手术托盘和其中的内容移动通过手术室时,识别、确认和跟踪手术托盘和内容,并且如果托盘上的一个或多个物品缺失,则通知用户,例如医务人员。
背景技术:
1、手术需要特定的一组或多组物品来执行。一些物品包括执行手术所需的器械(例如,钻头、剪刀、解剖刀等),而其它物品是被设计成替代、支撑或增强现有生物结构的设备或植入物。在将物品移入手术室之前,必须对所有物品进行消毒并放置在特定的手术托盘上。在手术完成之后,将使用过的和未使用的物品以相同或不同的状态、配置从手术室中移除,或者在一些情况下,在与手术之前放置物品的托盘不同的托盘上将其移除。例如,某些物品可能在它们的表面上具有生物材料,例如血液。此外,手术团队的成员可能将使用过的物品彼此叠置在托盘上,从而部分地遮挡某些物品的视野。对于从手术室出来的托盘上的物品来说,通常看起来与进入手术室相比是不同的,并且不那么有序。无论如何,重要的是识别和跟踪进入手术室的所有必要物品和离开手术室的所有物品。
2、保持跟踪托盘上的物品是乏味的,并且需要大量的时间和工作人员集中精力来跟踪物品和托盘。医院使用规程和流程,其要求个人对进入和离开手术的所有手术器械进行计数。常规规程需要视觉确认和/或单独手动处理每个器械以便于计数。这种方法缓慢、易于出现人为错误并且效率低。
3、已经提出了成像技术来跟踪手术物品,该成像技术可以包括使用计算机视觉的人工智能(ai)系统。迄今为止,这种提议的支持ai的系统没有提供解决方案,因为这种系统没有被适当地训练以准确地识别托盘及其内容物。不存在用于训练大到足以使用计算机视觉系统来准确地识别托盘和托盘上的物品的数据集的解决方案,因为这样的数据集需要在各种照明条件下以不同角度呈现的和/或被其它物品部分地覆盖的真实世界物品的许多图像,以反映在真实世界使用中物品可能如何被看见。将需要大量的时间来仅仅创建必要的训练数据集,该训练数据集由在所有不同角度、光强度、遮挡水平等下的器械的数十万张真实世界图像填充。时间限制使得构建ai系统的训练数据集不切实际。因此,所提出的支持ai的系统没有解决用于识别和跟踪托盘上的手术物品的常规规程所固有的问题。
4、真实世界的时间限制显著阻碍了基于ai的系统的学习,并负面地影响了系统的回忆能力,即,系统需要多久一次猜测物品是什么,以及其精确性,即,系统多久一次正确猜测物品。迄今为止,创建支持ai的计算机视觉系统可以从中学习以识别手术托盘上的物品的可工作数据集还不可行。这种可工作数据库需要将每一个物品放置在托盘上的几十万张真实世界图像。需要一种用于训练支持ai的计算机视觉系统的更高效的解决方案。
5、一种所提出的解决可行性问题的捷径涉及使用托盘和器械标记。利用这种捷径,支持ai的系统必须仅学习标记,而不是物品本身。例如,美国专利10,357,325提出使用相机:(1)基于存在于托盘上的矩阵码(例如,条形码或qr码)识别托盘,以及(2)基于附着到器械的彩色标记(例如,色带、带或环)识别托盘上的器械。这种基于标记的方法的问题是必须被标记和编码的不同手术物品和制造商的数量,以及在手术室中缺乏足够的、可靠的可操作性。此外,手术在白天和夜晚的所有时间发生,这改变了当托盘上的物品进入和离开手术室时对它们的照明暴露的性质。照明变化可以使自动成像器(例如相机)在进入手术室时将颜色标记读取为一个色调,但是在离开时将其读取为不同的色调。因此,如果发生以下一种或多种情况,基于标记的方法将失败:(1)托盘缺少识别托盘的特定矩阵或矩阵被遮挡而无法看到,(2)器械未返回到(a)其在同一托盘上的原始槽,(b)其在同一托盘中的原始取向,或(c)同一托盘,或(3)物品上的颜色标记被遮掩而无法看到,在不同照明条件下呈现为不同色调,或甚至从物品掉落。
6、因此,目前需要一种系统和方法,用于训练人工智能(ai)使能的计算机视觉系统以自动地和准确地识别手术托盘上的物品:(1)不需要附着到托盘或托盘中的物品的独立标记或代码,(2)不管各种照明条件如何,以及(3)不受托盘上物品的位置、角度、状态或遮挡百分比的影响。还存在对使用训练过的ai使能的计算机视觉系统以高召回率(recall)和精确度准确地识别托盘上的物品的系统和方法的当前需求。
技术实现思路
1、本发明通过提供一种可用于识别手术托盘、器械和植入物的支持ai的、动态的计算机视觉系统来满足当前的需要。本发明的支持ai的系统被训练成满足系统管理员或管理员的雇员、承包人或代理人先前上传的最小召回率和精确度阈值。一旦被训练,支持ai的系统被配置成以允许用户利用移动计算机设备拍摄至少一个手术工具托盘的图片、视频或图像的方式部署以供使用,所述移动计算机设备包括成像器(例如,相机),然后系统通知用户:(1)(一个或多个)托盘的类型,(2)所述(一个或多个)托盘上的器械和植入物,和/或(3)从(一个或多个)托盘中缺失的任何器械和植入物。在实施例中,系统允许用户在手术之后拍摄(一个或多个)托盘的另一图片、视频或图像,并且然后系统将哪些器械和植入物存在于(一个或多个)托盘上通知给用户,并且记录到系统的数据库中。
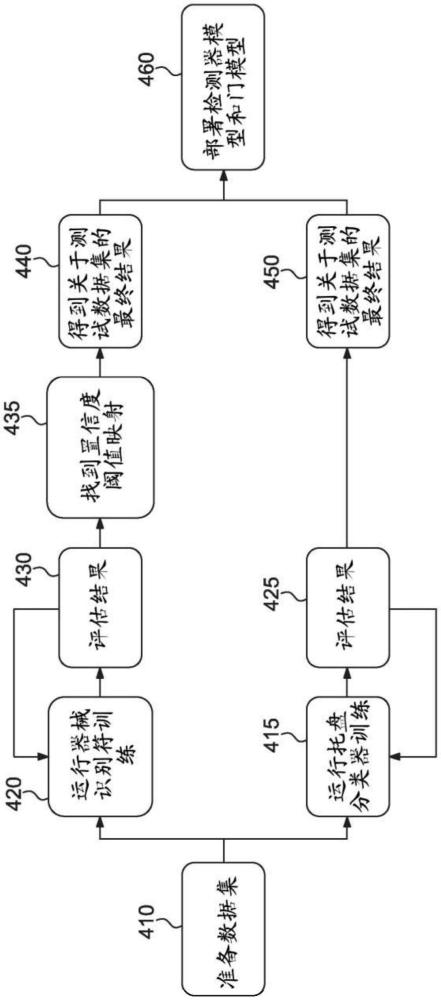
2、一般地,本发明的系统和方法通过以下步骤提供了对支持ai的计算机视觉系统的训练:(1)扫描手术器械或托盘至少两次以创建所述物品的初步3-d合成模型;(2)修改所述初步3-d合成模型以创建最终3-d合成物品,所述最终3-d合成物品完全存在于虚拟世界中,但其属性,例如反射率或形状,模拟所述物品的真实世界属性;(3)向最终3-d合成物品分配唯一识别(标识)(identification);(4)创建最终3-d合成物品的2维图像的无限训练集,计算机视觉辅助ai平台可通过改变以下各项来学习所述无限训练集:(a)虚拟物品的取向,(b)击中所述虚拟物品的虚拟光颜色/强度,(c)虚拟物品被遮挡多少不被看到,(d)虚拟物品在所识别的表面上方的高度,(e)用虚拟生物材料对虚拟物品的表面进行虚拟模糊等;(5)将训练集提供给系统,直到系统识别出训练集中的至少一个模式并且创建/修改归因于模式的至少一个识别模型;(6)创建唯一测试集,其中系统提供表示系统具有的物品识别是正确的置信度的数值置信度因子;(7)如果系统通过将用于识别物品的更新模型上传到服务器以供稍后使用,则确定系统是否正确地识别了测试集中的物品,以及置信度因子是否等于或大于期望的置信度因子,以及如果物品被错误识别或者置信度因子不在或高于期望的阈值,则重复步骤4-7,直到物品的识别并且满足置信阈值。
3、一般地,本发明的系统和方法通过以下步骤提供使用ai使能的计算机视觉系统:(1)接收手术托盘和其上包含的物品的图像;(2)启动包括张量的多个托盘分类模型,其中托盘分类模型已经如上所述在训练案例部分中被预先上传;(3)分析所述图像,并基于托盘分类模型对图像中的托盘类型进行分类;(4)在对托盘进行分类时,从数据库调出链接到托盘的分类的多个器械识别模型,其中,器械识别模型如上文在所述训练案例部分中概述的那样被上传;(5)分析所述图像并基于器械识别模型识别所述图像中的物品的类型;(6)将分类的物品与链接到所分类的托盘的物品列表进行比较以确定任何缺失的物品,以及(7)向软件应用通知所分类的物品和任何缺失的物品。
4、在本发明的示例性非限制性实施例中,提供了一种系统,其被配置为被训练以对手术托盘进行分类并识别其上包含的物品。该系统包括通过有线和/或无线通信网络与软件应用通信的处理器,以及成像器和服务器。成像器可以是能够拍摄图片或视频的相机。在实施例中,成像器使用像素和/或矢量创建真实世界场景的视觉描绘的文件。例如,相机能够产生以下文件格式中的任何一个或多个的图像:jpeg(或jpg)-联合图像专家组、png-便携式网络图形、gif-图形交换格式、tiff-标记的图像文件、psd-photoshop文档、pdf-便携式文档格式、eps-封装的postscript、ai-adobe图册文档、indd-adobe设计文档或raw-原始图像格式。
5、本发明的系统利用托盘和物品的合成图像来创建托盘或手术器械的初步3维模型。该方法使得能够创建合成图像的可工作的训练数据集。在非限制性实施例中,本发明的系统被配置成允许系统的管理者或管理者的雇员、承包人或代理人用成像器扫描托盘或手术器械、植入物、工具或紧固件至少两次以创建托盘或手术器械的初步3维模型,然后使用软件应用来修改托盘或手术器械、植入物、工具或紧固件的初步3维模型,以创建用于每个手术器械、植入物、工具或紧固件的最终3维合成物品文件。软件应用允许对最终3维合成物品的修改,包括限定从由以下组成的列表中选择的至少一个要素:物品的几何形状、每一顶点的位置、每一纹理坐标顶点的uv位置、顶点法线、构成被限定为顶点列表的每一多边形的面,和纹理坐标。软件应用将唯一识别分配给最终3维合成模型,也称为“3维合成物品”。“唯一识别可以是字母数字和/或色度的。在一个实施例中,软件应用可将唯一识别链接到所上传的图像中的一个或多个托盘分类。托盘分类可以包括器械、植入物、工具、紧固件或链接到托盘的其他物体的预定义列表,系统可以对其进行识别。
6、接下来,本发明的系统被配置为自动创建训练数据集和测试数据集,其中的每一个是针对每个最终3维合成物品而导出的。训练数据集被链接到由软件分配的唯一识别,以使得系统能够从最终的3维合成物品学习。相反,测试数据集不包括到唯一识别的链接。所有数据集,即(一个或多个)训练数据集和(一个或多个)测试数据集,包括最终3维合成物品的独特合成图像,其中最终3维合成物品的取向、照明最终3-d合成物品的合成光颜色或强度、或者最终3维合成物品在所识别表面上方的高度在每个图像中是唯一的(或独特的)。在某些实施例中,训练数据集还可以包括托盘、手术工具、植入物、紧固件或其他物体的多达100个或更多个真实世界图像。用于每个3维合成物品的唯一训练数据集可包含3维合成物品的数十万个独特2维图像,并且可选地包含被扫描以创建3维合成物品的物体的许多真实世界图像,所有这些图像可用于本发明的支持ai的计算机视觉系统的训练过程中,从而以高召回率和精确度辨识每个3维合成物品。每个训练数据集可以由本发明的系统和方法高效地创建。本发明的一个特征是,系统的训练可以是持续进行的,以通过使用训练数据集中的3维合成物品的多达无限数量的合成训练图像来持续地提高召回率和精确度。
7、本发明的系统和方法可以通过3维合成物品的每个训练数据集来训练,该训练数据集包含托盘、或手术工具、植入物、紧固件、或托盘中或托盘上的其他物体的2维图像和唯一识别。该系统被配置为处理训练数据集中的每个2维图像,并且创建和更新识别模型,该识别模型可以被部署用于识别托盘或托盘、手术工具、植入物、紧固件或托盘上或托盘中的其他物体,而不需要与训练数据集一起提供的正确识别。识别模型包括归因于在每个训练数据集中识别的托盘或手术工具、植入物、紧固件或其他物体的视觉模式的特征向量。特征向量可以被组合成矩阵以提供特征向量的2维阵列。矩阵可以被分层为张量以提供3维阵列,该阵列由系统用来在系统被部署在手术室中时对(一个或多个)托盘进行分类或识别(一个或多个)器械。
8、一旦创建,用于3维合成物品的每个识别模型(其包括归因于已知托盘和在托盘上或托盘中的手术工具、植入物、紧固件或其他物体的张量)被存储在服务器上,该服务器在最终3维合成物品所位于的场所处或在远离最终3维合成物品的地点处。当系统处理附加的训练数据集时,系统可以创建归因于最终3维合成物品的已知或新模式的至少一个附加特征向量。这些附加特征向量可以被组合以创建新的矩阵或被添加到相关识别模型中的预先存在的矩阵。在识别模型中对矩阵的添加或修改可以用于修改或创建新的张量,然后由系统将其上传到服务器或上传到第二服务器以供稍后部署使用。对特征向量的该创建构建了归因于手术工具、植入物、紧固件或其他物体的识别模式的张量,这训练了系统,使得当系统被部署以与新的或更新的识别模型一起使用时,系统能够在不同的图像中自动辨识相同的器械。
9、3维合成物品的每个测试数据集可用于评估系统已经经历的训练的量和有效性。在相关的训练数据集被提供给系统以进行处理期间或之后,测试数据集可以被提供给系统。当处理训练数据集时,系统被提供有答案,但是当处理测试数据集时,系统不被提供有答案。当测试数据集中的每个合成图像被提供给系统时,系统识别合成图像中的物品,并提供数值置信度因子,其表示系统认为物品的识别正确的置信度。如果数值置信度因子未能满足或超过系统管理员或管理员的雇员、承包人或代理人在系统中预先设置的最小阈值,则向系统提供附加的训练数据集,使得系统可以通过创建归因于所识别的模式的更新的特征向量来改进置信度因子,以便存储在服务器上以供稍后部署。相反,如果系统识别和数值置信度值正确,并且置信度因子等于或大于系统中设置的置信度因子,则可以部署系统以与新的或更新的识别模型一起使用。
10、在某些实施例中,即使在系统被部署以与新的或更新的识别模型一起使用之后,附加的训练数据集也可被持续地提供给系统以持续地创建归因于所识别的模式的特征向量,以提高系统在针对独特图像(合成或真实世界)被测试时的召回率和精确度值,其大于先前由系统的管理员或管理员的雇员、承包人或代理人确定的最小阈值。
11、在示例性非限制性实施例中,本发明的部署系统包括软件应用。该应用被配置成在移动计算机设备上或在计算机设备上操作,移动计算机设备或计算机设备中的任一个与被配置成产生手术托盘的图像的至少一个图像数据收集设备通信。该应用被配置为从图像数据收集设备接收手术托盘或手术工具、植入物、紧固件或手术托盘上或手术托盘中的其他物体的图像,并且通过有线和/或无线通信网络将图像传送到位于手术托盘所位于的场所处或位于远离该场所的地点处的服务器。该系统包括通过有线和/或无线通信网络与系统的软件应用以及服务器通信的处理器。处理器被配置为在将所述图像传送到所述服务器时从所述系统的库数据库调用:多个先前创建的识别模型,包括链接到合成托盘的先前创建的张量。链接到合成托盘的识别模型由前述训练系统预先上传。处理器被配置成分析图像并且基于链接到合成托盘的(一个或多个)识别模型对图像中的托盘的类型进行分类。然后,基于由处理器分配的图像中的托盘的分类,处理器从库数据库中调用:(1)多个识别模型,其链接到3维合成物品,所述合成物品链接到所述托盘的分类,(2)识别模型,包括:(a)表面纹理,(b)物品材料成分,以及(c)尺寸公差;(3)链接到合成托盘的物品的列表,以及(4)如上所述为3维合成物品创建的多个特征向量。处理器然后分析图像并且继续基于链接到3维合成物品的(一个或多个)识别模型对图像中的物品的类型进行分类。处理器然后将分类物品列表与链接到分类托盘的物品列表进行比较以确定是否存在任何缺失的物品。系统通知软件应用分类的物品和任何缺失的物品。软件应用然后显示所识别的和缺失的物品的列表。
12、在其他实施例中,公开了一种用于识别手术托盘和其上包含的物体的方法。该方法包括首先从图像数据收集器(例如相机)接收手术托盘和其上包含的物体的图像(照片或视频)。图像数据收集设备使用在移动计算机设备或者可以与移动计算机设备同步的计算机设备上运行的软件应用连接到服务器或远程服务器。移动计算机设备或计算机设备通过有线和/或无线通信网络与拍摄图像的地点处的服务器通信,或者与在远离该场所的位置处并与服务器通信的远程服务器通信。在接收到所述信息时,所述方法包括使用处理器从数据库调用:链接到合成托盘的多个识别模型。同样,先前已经通过以先前讨论的方式训练基于ai的计算机视觉系统而获得了所述识别模型。接下来,该方法包括分析图像并基于链接到合成托盘的识别模型对图像中的托盘的类型进行分类。在对托盘进行分类时,该方法包括从数据库调用与3维合成物品链接的多个识别模型,所述3维合成物品被包括在托盘的分类中,所述识别模型包括:(a)链接到所识别的托盘分类的3维合成物品的表面纹理,(b)物品材料成分,以及(c)尺寸公差;以及(d)列表。同样,通过训练基于ai的计算机视觉系统创建了链接到3维合成物品的识别模型,并且将3维合成物品链接到合成托盘的列表先前已由具有旨在包含在托盘上的物品的知识的专业人员上传。然后,该方法包括分析图像并基于链接到3维合成物品的(一个或多个)识别模型对图像中的物品的类型进行分类。接下来,该方法包括将分类的物品与链接到分类的托盘的物品列表进行比较以确定任何缺失的物品。然后,该方法包括向软件应用通知分类的物品和任何缺失的物品。最后,该方法包括在显示器上向移动计算机设备的用户显示结果。
13、在某些实施例中,图像数据收集设备是相机并且可以安装在可穿戴设备上。
14、参考以下描述和所附权利要求,本发明的这些和其它特征、方面和优点将变得更好理解。
- 还没有人留言评论。精彩留言会获得点赞!