用于控制技术系统的方法和控制装置与流程
背景技术:
1、数据驱动的机器学习方法越来越大程度地用于控制复杂的技术系统,例如燃气涡轮机、风力涡轮机、蒸汽涡轮机、电机、机器人、化学反应器、铣床、生产设施、冷却设施或供热设施。在此情况下,通过强化学习(reinforcement learning)方法特别是将人工神经网络训练为,针对技术系统的相应状态而生成状态特定的控制动作以控制技术系统,通过所述控制动作而优化技术系统的性能。这种针对技术系统的控制而优化的控制代理通常也被称为策略(policy),或简称为代理。
2、为了成功地优化控制代理而通常需要大量的技术系统运行数据作为训练数据。训练数据在此应尽可能具有代表性地涵盖技术系统的这些运行状态和其他运行条件。
3、在许多情况下,此类训练数据以数据库的形式而存在,其中在这些数据库中存储有在技术系统上所记录的运行数据。这种所存储的训练数据通常也称为批量训练数据或离线训练数据。根据经验,训练的成功通常取决于批量训练数据覆盖技术系统可能的运行条件的程度。相应地应预期,使用批量训练数据训练的控制代理在只有少量批量训练数据的这种运行状态下表现不佳。
4、为了改善训练数据很少覆盖的状态空间区域中的控制行为,在tatsuyamatsushima、hiroki furuta、yutaka matsuo、ofir nachum和shixiang gu在https://arxiv.org/abs/2006.03647(检索于2021年10月8日)上的出版物“deployment-efficientreinforcementlearningvia model-based offline optimi zation”中提出了一种递归学习方法。然而,这种方法产生的随机策略有时可能针对相同的运行状态而输出非常不同的且不能可靠预测的控制动作。尽管可以通过这种方式有效地探索状态空间,但在许多技术系统上并不允许这样的随机策略,因为它们无法事先被可靠地验证。
技术实现思路
1、本发明的目的是说明一种用于控制技术系统的方法和控制装置,所述方法和控制装置允许探索技术系统的状态空间并且在此使用确定性的控制代理。
2、该目的通过具有专利权利要求1的特征的方法、通过具有专利权利要求12的特征的控制装置、通过具有专利权利要求13的特征的计算机程序产品以及通过具有专利权利要求14的特征的计算机可读存储介质来实现。
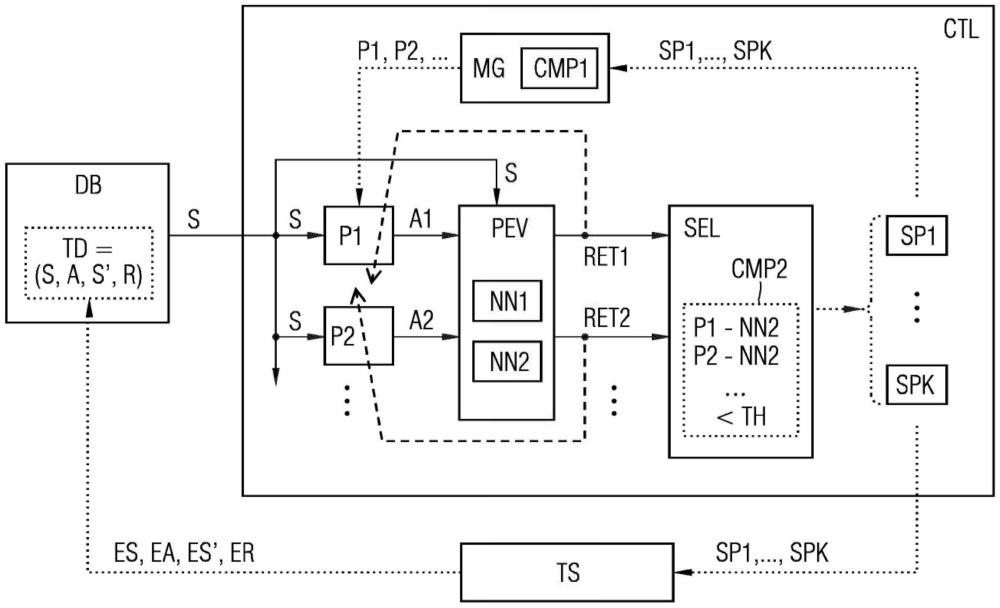
3、为了控制技术系统而读入训练数据,其中,相应的训练数据集包括指定技术系统的状态的状态数据集、指定控制动作的动作数据集以及由应用所述控制动作所产生的技术系统的性能值。术语控制在此也应被理解为:技术系统的调节。使用训练数据将第一机器学习模块训练为,使用状态数据集和动作数据集来再现所得到的性能值。此外,向多个不同的确定性控制代理分别输送状态数据集,并且将所得到的输出数据馈送到经过训练的第一机器学习模块作为动作数据集。然后,根据通过经过训练的第一机器学习模块输出的性能值而选择控制代理其中的多个。根据本发明,技术系统分别由所选择的控制代理来控制,其中另外的状态数据集、动作数据集和性能值被检测并添加到训练数据中。利用由此而得以补充的训练数据,从第一机器学习模块的训练开始重复上述方法步骤。
4、为了执行根据本发明的方法而设置相应的控制装置、计算机程序产品和计算机可读的、优选非易失性的存储介质。
5、根据本发明的方法和根据本发明的控制装置可以例如通过一个或多个计算机、处理器、专用集成电路(asic)、数字信号处理器(dsp)和/或所谓的“现场可编程门阵列”(fpga)来实施或实现。
6、本发明的优点尤其应视为如下方面,由于通过多个不同且迭代地适应的控制代理对技术系统的控制而实现对技术系统的状态空间的有效探索。通过这种方式,可以有效减少训练数据覆盖较差的状态空间区域的负面影响。同时,通过对确定性控制代理的限制可以避免随机控制代理的验证问题。
7、本发明的有利实施方式和扩展在从属权利要求中说明。
8、根据本发明的一个有利实施方式,第二机器学习模块可以被训练为或者使用训练数据被训练为,使用状态数据集来再现动作数据集。控制代理分别可以与第二机器学习模块进行比较,其中分别确定对相应控制代理与第二机器学习模块之间的相异性进行量化的距离。因此,相比于与第二机器学习模块具有较大距离的控制代理,可以优先选择与第二机器学习模块具有较小距离的控制代理。特别是在人工神经网络的情况下,作为距离可以确定在相应控制代理的神经权重与第二机器学习模块的神经权重之间的距离。优选地,可以确定这些神经权重的向量表示之间的必要时加权的欧几里得距离。
9、特别地,可以将相应控制代理的距离与阈值进行比较。如果超过阈值,那么则可以将相应的控制代理从选择中排除。因此,选择控制代理的前提条件可以表述为:|n2-np|<=th,其中th是阈值,n2是第二机器学习模块的神经权重向量,并且np是所涉及的控制代理的神经权重的向量。以这种方式,可以将对技术系统的控制仅限于与第二机器学习模块没有太大区别的控制代理。在许多情况下,因此可以有效地排除输出不容许的或严重不利的控制动作的控制代理。
10、有利地,在重复这些方法步骤时可以提高阈值。以这种方式,能够在迭代训练过程中使得对技术系统状态空间的探索得到改进。
11、根据本发明的另一有利实施方式,多个控制代理可以由模型生成器生成。就此而论,可以将所生成的其中多个控制代理与其他控制代理进行比较,其中分别确定对所比较的控制代理之间的相异性进行量化的距离。于是有利地,相比于与一个或多个其他控制代理具有较小距离的控制代理,可以优先选择和/或生成与一个或多个其他控制代理具有较大距离的控制代理。因此可以提供彼此之间具有高度多样性的控制代理。以这种方式,能够并行地并且因此更有效地探索状态空间的不同区域。
12、根据本发明的一个有利的扩展,可以使用训练数据将控制代理训练为,使用状态数据集来再现指定对性能进行优化的控制动作的动作数据集。除了所述选择之外,在许多情况下,可以通过此类的额外训练进一步改进所选择的控制代理的性能。
13、根据本发明的另一个有利的扩展,相应的训练数据集可以包括后续状态数据集,其指定由于控制动作的应用而产生的技术系统的后续状态。然后可以使用训练数据将第一机器学习模块训练为,使用状态数据集和动作数据集来再现所得到的后续状态数据集。此外,可以使用训练数据将第二机器学习模块训练为,使用状态数据集来再现动作数据集。然后,通过经过训练的第一机器学习模块可以针对由相应控制代理输出的动作数据集而确定后续状态数据集,并且将所述后续状态数据集馈送到经过训练的第二机器学习模块中。所得到的后续动作数据集又可以与后续状态数据集一起被馈送到经过训练的第一机器学习模块中。最后,可以在选择控制代理时考虑针对所述后续状态的由此所得到的性能值。以这种方式,状态和控制动作被逐步外推到未来或被预测,从而可以确定包括多个时间步的控制轨迹。这种外推通常也称为转出(roll-out)或虚拟转出。然后可以针对所述控制轨迹计算经多个时间步累积的性能,并且优选地将其分配给轨迹开始处的控制动作。在强化学习的上下文中,这样的累积的性能通常也被称为“回报(return)”。为了计算所述回报,可以对为未来时间步确定的性能值进行折扣,即,对这些性能值赋予在每个时间步变得更小的权重。
- 还没有人留言评论。精彩留言会获得点赞!