一种基于多模态对话内容联合建模的情感分析方法及系统
1.本发明涉及机器智能领域,尤其涉及一种基于多模态对话内容联合建模的情感分析方法及系统。
背景技术:
2.情感分析或情绪识别是当前计算机领域的重要研究领域,一般指使用计算机对人类在特定时刻表达出的情绪进行识别,这种技术不仅在人机互动中有着广泛应用,在其他方向比如破案刑侦以及心理诊疗方面也有着很大的潜力。对话中的情感识别作为情感计算领域一个新的研究方向,近年来越来越受到关注。在实际应用中,可以用于在社交网站上分析情感把握舆情,对客服对话等进行抽样分析,保障服务质量,作为心理治疗领域的辅助工具,对用户的心理状况,心理压力等进行分析等。
3.对话情感分析方法需要建模上下文敏感和说话人敏感的依赖关系,现今有许多方法融合多模态并建模对话中的关系,但如dialoguernn、dialoguegcn模型的每个部分只负责提取自己的特征,靠前的模块不一定能为后方的模块提取到合适的特征,emoberta等模型虽然用bert统一建模了整个过程,但只是对文本进行了利用,没有更好地运用到多模态特征。现今,缺少一个统一三个模态,并能同时在一个模型中提取说话人关系,多模态关系,以及上下文和对话轮数依赖关系的模型,为此有必要发明一种基于多模态对话内容联合建模的说话人连续情感分析方法。
技术实现要素:
4.本发明目的在于提供一种基于多模态对话内容联合建模的情感分析方法及系统,以解决上述现有技术存在的问题。
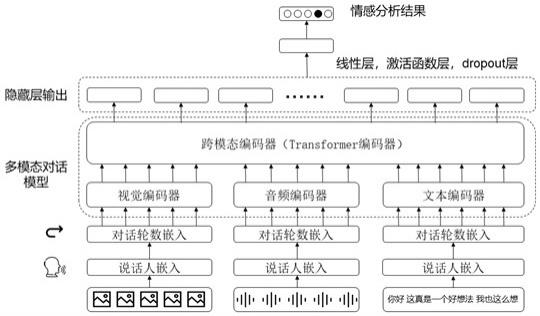
5.本发明中所述一种基于多模态对话内容联合建模的情感分析方法包括以下步骤:s1、对多模态对话数据集进行模型预训练;s2、分别对一段对话的语音、文本及视频进行语音嵌入、词嵌入及图像嵌入;再分别经过说话人嵌入及对话轮数嵌入后分别输入音频编码器、文本编码器和视觉编码器;得到每个模态对应的向量特征序列;s3、将三个单模态的向量特征序列输入一个跨模态编码器;s4、从跨模特编码器提取最后一层隐藏层后依次经过全连接层、激活函数、dropout层以及全连接层后得到情感分析结果。
6.所述步骤s1包括以下步骤:s101、在输入时对三个模态分别使用[mask]进行掩膜处理,再预测对应[mask]的部分;s102、在进行说话人嵌入时,随机对一些说话人使用[mask]进行掩膜处理,再预测对应[mask]的说话人嵌入;s103、对于文本-视频-音频的样本对,随机对其中的1到2个模态用其他样本对的
样本进行替换;使用[cls]作为输出,经过全连接层和激活函数来预测最终的匹配类型,最终的输出分数。
[0007]
所述步骤s2包括以下步骤:s201、输入一段对话的语音、文本、视频,通过相应的单模态编码器,得到对应模态的嵌入,对于文本模态,使用预训练的bert类模型预训练的分词器对文本进行分词处理再得到对应的词嵌入;对于语音模态,使用wav2vec预训练模型提取对应的音频特征;对于视频模态,则使用了预训练的faster r-cnn来提取视觉嵌入;s202、以对话进行说话人信息嵌入,以及对话轮数嵌入,得到三个单模态编码器的输出。
[0008]
所述步骤s3包括以下步骤:s301、三个单模态编码器得到的三个模态的向量特征序列,通过沿着序列方向连接,得到模态融合后的向量特征序列;s302、将该向量特征序列输入跨模态编码器中,对该序列进行编码。
[0009]
所述步骤s4包括以下步骤:s401、提取跨模态编码器最后一层隐藏层输出序列h,依次经过神经网络;s402、对整个神经网络进行训练,根据每个样本对中标注好的最后一个样本的真实情感标签以及神经网络输出的情感预测值。
[0010]
本发明中所述一种基于多模态对话内容联合建模的情感分析系统,利用所述方法进行情感分析。
[0011]
本发明中所述一种基于多模态对话内容联合建模的情感分析方法及系统,其优点在于,基于对话的多模态预训练模型为基础,经过情感分类模块,在相应数据集上进行微调训练,得到可以在语音、视频、文本模态上使用的情感分析方法。为此同时提出预训练模型的方法,比起传统的预训练方法,该方法具有说话人嵌入以及对话轮数嵌入模块,使得整个预训练模型学习到更加适应对话场景任务的语言模型。
附图说明
[0012]
图1是本发明中所述一种基于多模态对话内容联合建模的情感分析方法流程示意图。
[0013]
图2是本发明中所述预训练的流程示意图。
具体实施方式
[0014]
本发明中所述一种基于多模态对话内容联合建模的情感分析系统应用以下方法进行情感预测。本发明中所述一种基于多模态对话内容联合建模的情感分析方法如图1和图2所示,包括以下步骤:s1、基于多模态对话数据集进行模型预训练。
[0015]
s2、输入一段对话的语音、文本、视频模态的原始信息,得到相应的语音嵌入、词嵌入及图像嵌入。结合对话轮数嵌入,说话人嵌入等信息,得到输入的token序列。
[0016]
s3、经过三个单模态编码器,得到每个模态对应的向量特征序列,经过一个基于transformer的跨模态编码器;。
[0017]
s4、从跨模态编码器提取最后一层隐藏层,依次经过全连接层,激活函数,dropout层以及全连接层得到最后的情感分析结果。
[0018]
进一步地,所述步骤s1包括以下步骤:s101、在输入时对三个模态分别使用[mask]进行掩膜处理,再预测对应[mask]的部分。以文本模态为例,对随机15%的文本使用[mask]进行掩膜处理,模型的目标即通过最小化以下负对数似然函数,使用该[mask]周围的词,视频以及音频来预测被掩膜的文本:,其中θ是可训练的参数集合,三个模态的样本来自同一个样本对d。
[0019]
s102、在进行说话人嵌入时,随机对一些说话人使用[mask]进行掩膜处理,再预测对应[mask]的说话人嵌入。
[0020]
s103、对于文本-视频-音频的样本对,随机对其中的1到2个模态用其他样本对的样本进行替换。该模型需要判断哪些输入是匹配的,即需要判断如图2所示五种情况:情况(1)所有三个输入都匹配;情况(2)图像和音频匹配;情况(3)只有文本和图像匹配;情况(4)只有文本和音频匹配;以及情况(5)没有匹配的样本。为此我们使用[cls]作为输出,经过全连接层和激活函数来预测最终的匹配类型,最终的输出分数为。这个任务的损失函数定义为:其中是真实标签值的独热向量,bce损失函数为:进一步地,所述步骤s2包括以下步骤:s201、输入一段对话的语音、文本、视频,通过相应的单模态编码器,得到对应模态的嵌入:对于文本模态,使用预训练的bert类模型预训练的分词器对文本进行分词处理再得到对应的词嵌入。对于语音模态,使用第二版wav2vec预训练模型提取对应的音频特征。对于视频模态,则使用了预训练的faster r-cnn来提取了视觉嵌入。
[0021]
s202、为了对整个对话建模并且提取对话中的说话人以及说话次序的依赖关系,模型以对话进行了说话人信息嵌入,以及对话轮数嵌入等,得到三个单模态编码器的输出。
[0022]
进一步地,所述步骤s3包括以下步骤:s301、三个单模态编码器得到的三个模态的向量特征序列,通过沿着序列方向连接,得到模态融合后的向量特征序列。
[0023]
s302、将该向量特征序列输入基于transformer的跨模态编码器中,对该序列进行编码。
[0024]
进一步地,所述步骤s4包括以下步骤:s401、提取跨模态编码器最后一层隐藏层输出序列h,依次经过如下的神经网络:
其中,隐藏层输出序列h通过一个全连接层和激活函数得到一个768维的全局特征向量,训练过程中会使用随即丢弃法防止模型过拟合,最后通过一个全连接层得到情感分类向量表示。
[0025]
s402、为了得到最终的情感分析神经网络,需要对整个神经网络进行训练,根据每个样本对中标注好的最后一个样本的真实情感标签以及神经网络输出的情感预测值,设置了如下的损失函数:其中是真实情感标签的独热编码,n是训练数据样本的数量,c则是情感分类的数量,λ是正则化率,则是模型的权重。在训练过程中,训练样本被分成一个个小批量数据,并使用随机梯度下降进行训练。
[0026]
对于本领域的技术人员来说,可根据以上描述的技术方案以及构思,做出其它各种相应的改变以及形变,而所有的这些改变以及形变都应该属于本发明权利要求的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1