新建线路列车自动驾驶决策模型的构建方法
本发明涉及交通运输,特别是一种新建线路列车自动驾驶决策模型的构建方法。
背景技术:
1、截至2021年12月31日,我国共有51个城市开通运营城市轨道交通线路269条,运营里程8708公里,车站5216座,实际开行列车3120万列次。随着各大城市地铁的快速发展以及开通线路的不断增多,在各个地铁集团的车辆运行域、管理域都积累了大量的数据。例如在自动售检票线网管理中心系统积累了大量客流数据,以及与客流相关的行车、气象等数据;控制车辆运行的驾驶数据;管理域一体化平台历年来所积累的数据等。
2、对于车辆自动驾驶数据而言,现有的数据仓库是彼此独立的信息系统。这个数据孤岛和数据碎片化问题,不仅出现在各个地铁集团之间,即使对同一地铁集团内的不同线路之间驾驶数据集成也面临着困难。地铁集团之间、集团内部不同线路之间,没有采用可靠的数据共享方案,来实现列车运行数据的共享,数据未发挥应有作用,造成了列车运营数据价值的严重浪费。另一方面,对某一地铁集团而言,每次开通新建设的线路都要单独搭建系统接入车辆驾驶数据,这将导致建设与运维成本的升高,资源利用率低下,而且,仅仅靠某个地铁集团本身积累的数据有限,搭建的列车自动驾驶决策模型的处理精度不高,节能效果等不理想。
3、在数据智能时代,数据成为新的生产资料,其价值与日俱增,亟待有效的方法对各个集团的车辆驾驶数据信息资源、技术架构进行集约化管理,从而满足各地铁集团的多个新建线路初期、近期及远期的车辆节能驾驶发展需求。
技术实现思路
1、针对背景技术的问题,本发明提供一种新建线路列车自动驾驶决策模型的构建方法,以解决现有技术中新建线路列车自动驾驶决策模型搭建效率差地、成本高、资源利用率低下、效果差的问题。
2、为实现本发明的目的,本发明提供了一种新建线路列车自动驾驶决策模型的构建方法,其创新点在于:包括全局服务器、分组控制模块和n个运营商服务器;所述运营商服务器上存储有对应运营线路的多个列车自动驾驶曲线样本;
3、所述构建方法包括:
4、设某条新建线路包括多个站点,每相邻两个站点之间的路段记为一个子线路,将其中任意一个子线路记为子线路l,子线路l的线路信息包括线路长度和编组类型,所述编组类型包括列车型号和车厢数量;
5、一)全局服务器将子线路l的线路信息下发给各个运营商服务器;
6、二)根据收到的子线路l的线路信息,各个运营商服务器均按方法一获取对应的可用样本数据集;
7、三)然后各个运营商服务器均将对应的可用样本数据集的数据量信息发送给分组控制模块;
8、所述可用样本数据集的数据量为该可用样本数据集所辖的列车自动驾驶曲线样本的个数;
9、四)分组控制模块按方法二对n个运营商服务器进行分组,得到m个训练组;
10、五)全局服务器通过分组控制模块按方法三控制m个训练组进行深度学习模型训练,得到子线路l对应的列车自动驾驶决策模型;
11、所述方法一包括:
12、1)从多个列车自动驾驶曲线样本中选择多个同等编组样本组成备选样本集;
13、所述同等编组样本为:采用与子线路l相同编组类型的列车运行得到的列车自动驾驶曲线样本;
14、2)然后从所述备选样本集中筛选出多个近似路段样本组成初筛样本数据集;
15、所述近似路段样本为:路段长度与子线路l的路段长度偏差在±5%以内的子线路上采集的列车自动驾驶曲线样本;
16、3)对初筛样本数据集所辖的各个列车自动驾驶曲线样本进行能耗计算,然后按能耗从小到大的顺序对初筛样本数据集所辖的全部列车自动驾驶曲线样本进行排序,选取排在前10%的列车自动驾驶曲线样本组成可用样本数据集;
17、所述方法二包括:
18、根据可用样本数据集的数据量由小到大的顺序对n个运营商服务器进行排序,按从前向后的顺序对全部运营商服务器进行分组,得到m个训练组;其中,前m-1个训练组所辖的运营商服务器个数均为q个,第m个训练组所辖的运营商服务器个数小于或等于q个;其中训练组个数m或单个训练组所辖运营商服务器个数q为设定值;
19、所述方法三包括:
20、全局服务器构建一个全局深度学习模型,各个运营商服务器均构建一个局部深度学习模型;
21、全局服务器向分组控制模块下达训练指令;
22、然后分组控制模块控制各个训练组均按方法四获取各自对应的加权聚合参数组,每次产生一个新的加权聚合参数组,分组控制模块即将新产生的加权聚合参数组数据上传给全局服务器;
23、全局服务器每收到一个新的加权聚合参数组数据,即利用新收到的加权聚合参数组数据通过加权聚合的方式对全局深度学习模型的模型参数进行迭代更新;当全局深度学习模型的模型参数迭代更新n次后程序结束,程序结束后得到的全局深度学习模型即为列车自动驾驶决策模型;其中,全局深度学习模型迭代更新次数n为设定值;
24、所述方法四包括:
25、对于单个训练组来说,
26、a)所辖每个运营商服务器均利用可用样本数据集对对应的局部深度学习模型进行训练,以对局部深度学习模型的模型参数进行更新;
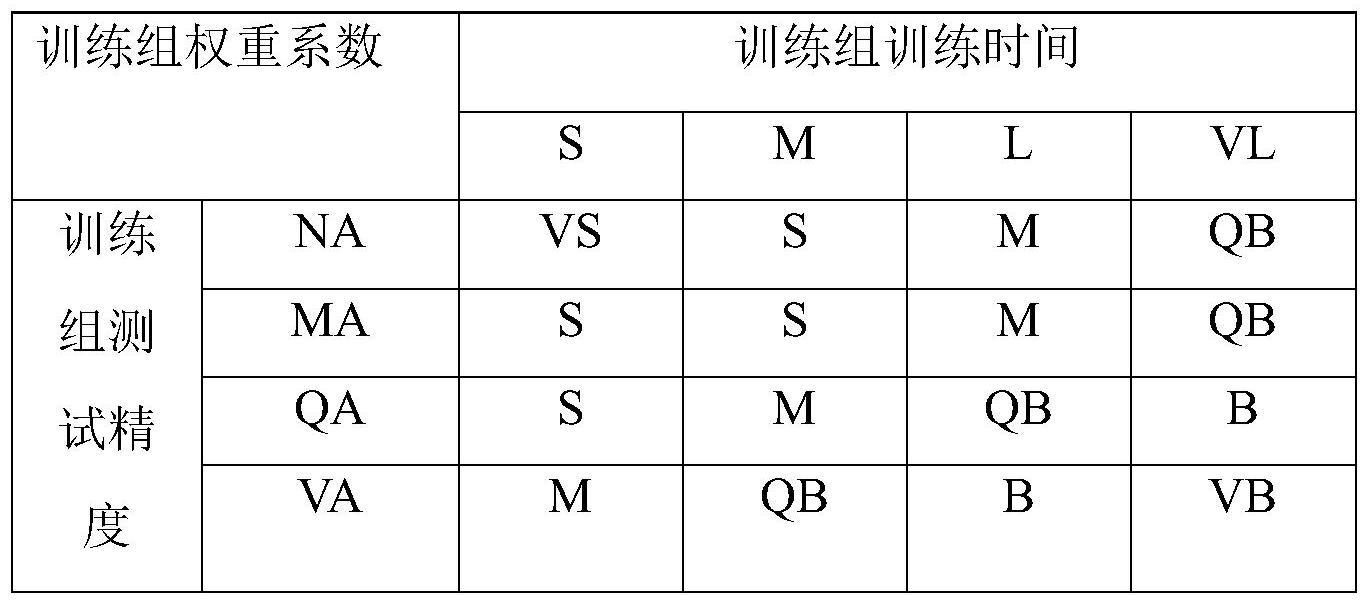
27、b)当训练组所辖的每个运营商服务器的局部深度学习模型均完成本轮模型参数更新后,分组控制模块对训练组所辖的全部运营商服务器的局部深度学习模型的模型参数取算数平均值得到综合局部模型参数;然后分组控制模块利用模糊推理算法,根据以下模糊推理表获取训练组的权重系数;将训练组的综合局部模型参数和权重系数的组合记为训练组的加权聚合参数组;
28、c)分组控制模块将训练组当前的加权聚合参数组数据上传给全局服务器;
29、然后返回步骤a);
30、所述模糊推理表为:
31、
32、{s,m,l,vl}为输入量训练组训练时间的模糊论域,其中,s表示短,m表示适中,l表示较长,vl表示很长;
33、{na,ma,qa,va}为输入量训练组测试精度的模糊论域,其中,na表示不精确,ma表示精度适中,qa表示较为精确,va表示非常精确;
34、{vs,s,m,qb,b,vb}为输出量训练组权重系数的模糊论域,其中,vs表示很小,s表示小,m表示适中,qb较大,b表示大,vb表示很大。
35、作为优化,所述列车自动驾驶曲线样本中提取的用于局部深度学习模型训练的输入特征向量包括:列车当前所处的位置、列车工况转换点的位置、列车在某位置点之前的历史平均速度、列车在当前采样点的运行速度、列车在某位置点所处坡度值、列车在该点所处坡度段起始位置、列车在该点所处坡度段的终止位置、列车在该点距当前坡度段结束的剩余长度、列车在该点所处坡度段的平均速度、列车在该点所处的最大限速值、列车在该点所处最大限速值的起始位置、列车在该点所处最大限速值的终止位置、列车站间运行总时间、列车型号、列车长度、列车重量;局部深度学习模型的输出特征向量包括:列车操控档位序列或列车预测速度曲线。
36、本发明的原理如下:
37、针对不同运营商服务器之间的数据共享利用,现有技术中通常采用同步学习算法或异步学习算法来实现,但两种方法都存在不足:如果采用同步学习算法,由于全局服务器要在所有运营商服务器完成训练和通信之后才能进行聚合,当其中一个或多个运营商服务器有大量的数据需要训练,以至于训练时间比其它运营商服务器要长很多,或者遭受很高的网络延迟时,其它训练速度较快的运营商服务器必须等待这些掉队的运营商服务器,这种同步更新方式将导致资源空闲并浪费计算能力;如果采用异步学习算法,全局服务器一旦接受到其中一个运营商服务器发来的更新,则立马更新全局模型而不用等待所有运营商服务器完成训练和通信,全局服务器维持当前的全局模型,而所有的运营商服务器维持自己的本地模型,但异步学习算法所存在的缺点是,当很多运营商服务器同时更新全局模型时全局服务器很容易拥挤打堆,造成通信瓶颈。
38、为了克服上述问题,本发明结合同步算法和异步算法的优点,采用了异步分组学习机制。在这种机制中,所有运营商服务器均采用相同的学习方法,训练时间则与运营商服务器的数据量大小成正比。所有运营商服务器根据数据量大小(响应延迟时长)被分配到不同的训练组,按照所采用的分配方法,通过对运营商服务器的数据量进行排序,依次分组,被分配到同一个训练组内的运营商服务器的数据量相差不大,在同一训练组内的运营商服务器的模型训练时间差距不大,训练组的训练耗时以同组中数据量最多的那个运营商服务器来计,其余运营商服务器等待即可,由于数据量接近,因此等待时间并不太长。单个训练组内各个运营商服务器均完成一轮训练后,立即将该训练组得到的综合局部模型参数上传到全局服务器以参与全局深度学习模型的参数更新,而不必等待其他训练组的训练结果,各个运营商服务器以训练组为单位相对独立地参与全局服务器的更新。
39、但是上述异步分组学习方案也存在着如下问题:由于训练延迟越低则局部模型更新频率越高,如果每个训练组都按照均匀权重的方式对全局服务器的模型进行异步聚合更新,将导致全局深度学习模型更加倾向于延迟较低的训练组的局部深度学习模型,让全局深度学习模型成为有偏训练,会影响全局深度学习模型的性能。
40、为解决此问题,本发明创造性地采用模糊推理理论的方法,对各训练组采用动态加权的策略,对不同的训练组采用不同的权重系数:对更新频率高的训练组,采用较小的权重系数,而对更新频率低的训练组赋予更大的权重系数;同时,还考虑了训练组测试精度的影响,对测试精度低的训练组,采用较小的权重系数,而对精度高的训练组则赋予更大的权重系数。由此,将训练组的训练时间和测试精度两种维度作为模糊推理的输入信息量,通过模糊推理获取动态设置的权重系数,以提高全局模型的精度和收敛速度,使优秀的局部深度学习模型对全局深度学习模型的聚合产生更大的影响,从而提高全局模型质量,以上加权策略还保证了对各运营商服务器数据使用的一致性与均衡性。
41、通过上述加权异步分组学习的方法,单个训练组所辖的各个运营商服务器在训练组内同步地对相应的局部深度学习模型进行训练,同时,各个训练组又按各自的训练节奏参与全局服务器的全局深度学习模型的训练,训练最快的训练组有着更短的响应延迟,让全局模型的训练收敛更快;训练较慢的训练组则异步地将更成熟的局部模型参数发送给全局服务器参与全局训练,以便进一步提升全局模型的性能,同时,对各个训练组更新频率不均衡的问题,通过权重系数进行动态调整,避免全局深度学习模型的训练跑偏,而且,通过提高训练精度更高的训练组的权重,以保证全局深度学习模型的性能、质量和运行精度。
42、另外,本发明在充分利用现有各运营商的列车自动驾驶经验数据时,还对样本数据进行了多重筛选,只采用列车编组类型相同、路段长度偏差不大的样本数据,这样的样本数据,对新建线路的路段来说更具有针对性,通过这些数据训练出来的自动驾驶决策模型的精度更高,性能更好。更近一步地,将上述样本数据按列车能耗按从小到大排序,取前面10%的样本数据来进行训练,使模型训练具备良好的节能基因,训练得到的自动驾驶决策模型吸收了各个运营商的自动驾驶节能经验,提高了决策模型的节能性能,为新建轨道线路车辆驾驶在节约能耗方面提供了坚实的保障。
43、由此可见,本发明具有如下的有益效果:采用本发明所述的方法来构建新建线路列车自动驾驶决策模型,能实现各个地铁集团或运营商内、外部数据共享,构建数据价值联盟,解决现有列车自动驾驶数据资源严重浪费,新建线路资源利用率低、列车自动驾驶决策模型搭建效率低、运维成本高的问题,还能有效降低新建线路列车运行能耗,为轨交车辆智能驾驶决策控制提供有力支撑。
- 还没有人留言评论。精彩留言会获得点赞!