视觉注意力预测模型的构建方法、系统、终端及介质
本发明涉及视觉注意力预测,具体地,涉及一种面向孤独症群体的视觉注意力预测模型的构建方法、系统、终端及介质。
背景技术:
1、人类视觉系统能够快速选择并集中于视觉刺激中的重要区域,这种能力使得人类能够有选择性地处理进入视野的大量信息,从而高效地接收和处理主要信息而忽视无关的信息,这种选择性机制叫做视觉注意机制。视觉注意力预测(又叫视觉显著性预测、注视点预测)即为模拟人眼的视觉注意机制的技术,而最终计算得到的显著性图可以量化表示注意力分布,其中区域的亮度越高表示该区域吸引人眼注意的概率越大。其在对象分割、目标追踪、图像压缩和视频压缩等诸多视觉相关的任务中有着十分重要的应用。
2、孤独症谱系障碍是一种具备遗传性的神经发育障碍,目前已经有计算模型和神经影像证据证明孤独症患者面对视觉刺激会表现出与正常对照组不同的非典型视觉注意行为。简而言之,当观察一幅场景时,正常对照组倾向于关注具有高阶语义属性的对象,比如人脸、文本等等;而孤独症患者却往往被背景区域和一些具有低阶属性的区域所吸引,这些区域被称为非典型显著区域。目前已有的孤独症专用的视觉注意力预测方法多是受到面向常规群体的通用视觉注意力预测方法的启发,忽略了孤独症患者明显区别于正常对照组的非典型注视行为和特殊的视觉偏好,只是在孤独症患者的眼动数据集上进行简单地迁移,缺少针对性,对注视点的预测性能不佳。
技术实现思路
1、本发明针对现有技术中存在的上述不足,提供了一种面向孤独症群体的视觉注意力预测模型的构建方法、系统、终端及介质。
2、根据本发明的一个方面,提供了一种视觉注意力预测模型的构建方法,包括:
3、构建基于非典型显著区域增强的视觉注意力预测模型;
4、采用已知的眼动数据集对所述基于非典型显著区域增强的视觉注意力预测模型进行预训练,并采用孤独症群体的眼动数据集对所述基于非典型显著区域增强的视觉注意力预测模型进行修正,完成对所述基于非典型显著区域增强的视觉注意力预测模型的端到端训练;
5、采用已知的眼动数据集中的测试图像对训练后的所述基于非典型显著区域增强的视觉注意力预测模型进行测试,构建得到最终的视觉注意力预测模型。
6、可选地,所述构建基于非典型显著区域增强的视觉注意力预测模型,包括:
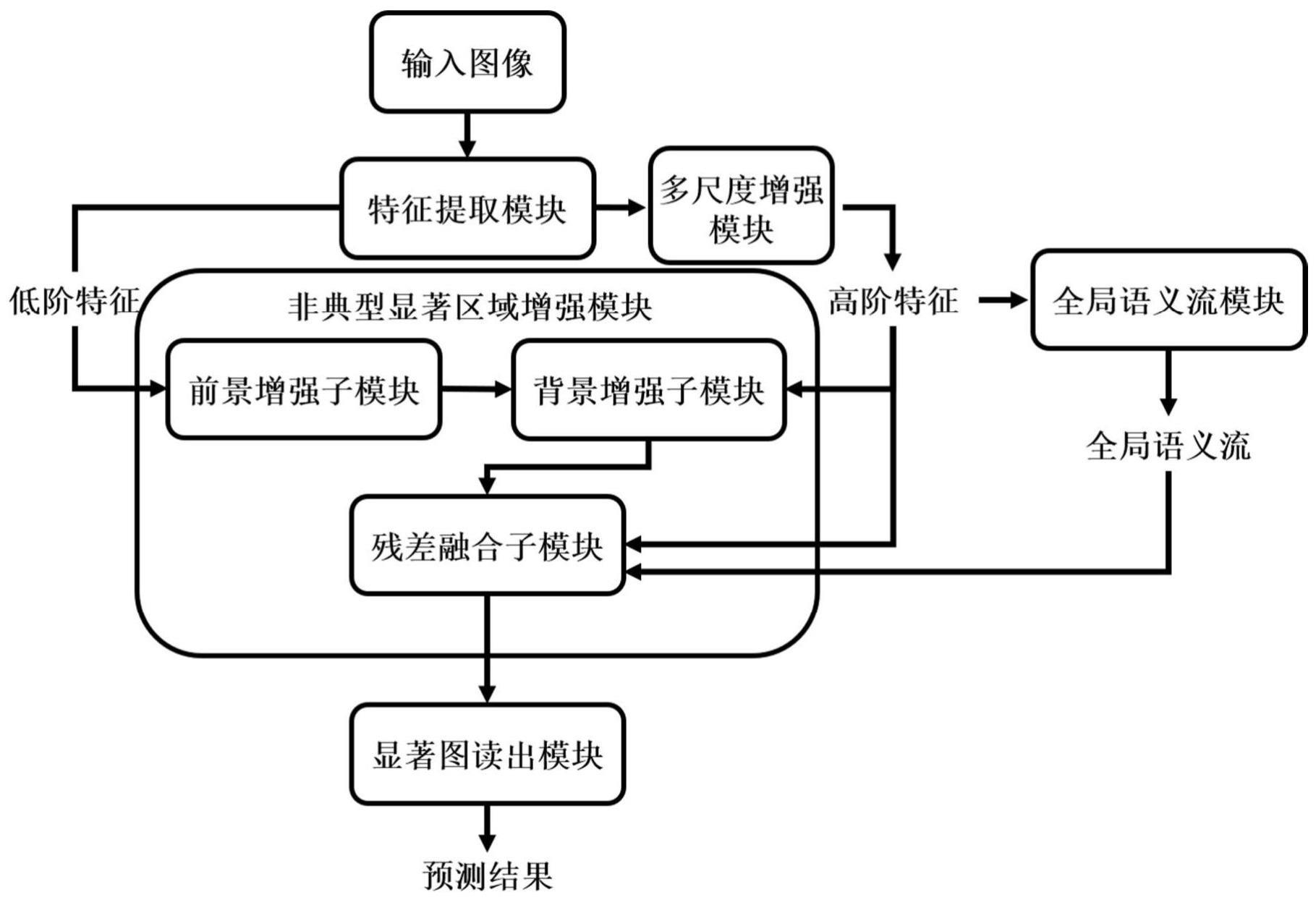
7、构建特征提取网络层,用于提取输入图像的特征,并输出多阶特征图;
8、构建多尺度增强网络层,用于对所述多阶特征图中的最高阶特征图进行多尺度增强,以提升对不同尺度的显著性区域的检测能力;
9、构建非典型显著区域增强网络层,用于以所述最高阶特征图作为初始预测结果,从上至下地对所述的多阶特征图进行残差融合,得到强化的非典型显著区域特征图;
10、构建全局语义流网络层,用于分别从空间和通道角度提取所述最高阶特征图的上下文语义信息,得到全局语义流,并将所述全局语义流引入所述非典型显著区域增强网络层,用于引导残差融合,同时自适应的补充被稀释的语义信息;
11、构建显著图读出网络层,用于对所述强化的非典型显著区域特征图沿通道维度进行压缩并进行归一化,得到视觉注意力预测结果。
12、可选地,所述特征提取网络层,采用预训练的基于深度学习的对象识别网络的全卷积形式构建特征提取网络层的主干网,用于提取所述输入图像的特征,并输出多阶特征图;其中,所述特征提取网络层包括:卷积层、池化层和relu激活层。
13、可选地,所述多尺度增强网络层,采用多个并行的具有不同大小的卷积核的卷积层来显式地引入多尺度信息,对所述最高阶特征图进行多尺度增强,所述增强结果作用于所述残差融合过程中,用于提升对不同尺度显著区域的特征提取能力。
14、可选地,所述非典型显著区域增强网络层,包括:背景增强网络层、前景增强网络层和残差融合网络层;所述以所述最高阶特征图作为初始预测结果,从上至下地对所述多阶特征图中的特征进行残差融合,得到强化的非典型显著区域特征图,包括:
15、利用所述背景增强网络层,对所述多阶特征图中的高阶特征进行取反,得到背景特征,然后对所述背景特征进行归一化,得到背景权重图;
16、利用所述前景增强网络层,对与所述高阶特征相邻的低阶特征进行前景加权,得到增强后的低阶特征;
17、通过所述残差融合网络层,利用所述背景权重图对所述增强后的低阶特征进行加权融合,得到残差特征;对所述高阶特征与所述残差特征进行自适应融合,得到新的预测结果;
18、将所述新的预测结果作为新的高阶特征,继续与相邻的低阶特征进行残差融合,直至得到最终的强化的非典型显著区域特征图。
19、可选地,所述全局语义流网络层,包括通道增强网络层和空间位置增强网络层;所述分别从空间和通道角度提取所述特征图的上下文语义信息,得到全局语义流,包括:
20、将所述特征图中的最高阶特征经过卷积层变换压缩通道数,得到网络层输入特征;
21、所述通道增强网络层采用全局平均池化获得全局先验,并经过1*1卷积层变换和归一化,得到所述网络层输入特征的通道加权图,并利用所述通道加权图对所述网络层输入特征进行通道增强,得到通道增强特征;
22、所述空间位置增强网络层采用自注意力机制,充分捕捉所述网络层输入特征各像素之间的相关性,得到空间位置加权图,并利用空间位置加权图所述对所述网络层输入特征进行位置增强,得到位置增强特征;
23、将所述通道增强特征和所述位置增强特征进行融合,得到全局语义流;
24、所述全局语义流被引入所述非典型显著区域增强网络层,通过自适应的调整全局语义流的权重,用于在残差融合过程中自适应的补充全局信息。
25、可选地,所述显著图读出网络层,包括3*3卷积层和sigmoid激活函数。
26、可选地,所述采用已知的眼动数据集对所述基于非典型显著区域增强的视觉注意力预测模型进行预训练,并采用孤独症群体的眼动数据集对所述基于非典型显著区域增强的视觉注意力预测模型进行修正,完成对所述基于非典型显著区域增强的视觉注意力预测模型的端到端训练,包括:
27、采用公开的眼动数据集salicon和mit1003对所述基于非典型显著区域增强的视觉注意力预测模型进行预训练,并采用孤独症群体的眼动数据集saliency4asd对所述基于非典型显著区域增强的视觉注意力预测模型进行修正;
28、设置所述基于非典型显著区域增强的视觉注意力预测模型的初始化参数;
29、确定所述基于非典型显著区域增强的视觉注意力预测模型的损失函数;
30、确定所述基于非典型显著区域增强的视觉注意力预测模型中相关的超参数;
31、通过上述步骤完成对所述基于非典型显著区域增强的视觉注意力预测模型的端到端训练。
32、可选地,所述采用公开的眼动数据集salicon和mit1003对所述基于非典型显著区域增强的视觉注意力预测模型进行预训练,并采用孤独症群体的眼动数据集saliency4asd对所述基于非典型显著区域增强的视觉注意力预测模型进行修正,包括:
33、获取公开的眼动数据集salicon和mit1003以及孤独症群体的眼动数据集saliency4asd,对所述眼动数据集中图像数据的眼动位置采样点聚类生成包含注视点的mat文件;对所述mat文件进行归一化处理,转化生成注视点密度图作为真值图;
34、将所述眼动数据集salicon和mit1003的图像作为模型输入,将所述眼动数据集salicon和mit1003的图像对应的真值图作为标签,以端到端的方式训练所述基于非典型显著区域增强的视觉注意力预测模型,使所述模型自动学习原始图像与真值图之间的映射关系,获得人眼相关的特征分布;
35、将所述孤独症群体的眼动数据集saliency4asd的图像作为模型输入,将所述孤独症群体的眼动数据集saliency4asd的图像对应的真值图作为标签,以端到端的方式微调所述基于非典型显著区域增强的视觉注意力预测模型,使所述模型自动学习原始图像与真值图之间的映射关系,获得孤独症群体的眼动特征,对模型进行修正。
36、可选地,所述设置所述基于非典型显著区域增强的视觉注意力预测模型的初始化参数,包括:
37、所述基于非典型显著区域增强的视觉注意力预测模型,包括:特征提取网络层、多尺度增强网络层、非典型显著区域增强网络层、全局语义流网络层和显著图读出网络层;其中:
38、所述特征提取网络层采用其在imagenet数据集上预训练得到的参数作为初始化参数;其他网络层的初始参数为随机初始化参数。
39、可选地,所述确定所述基于非典型显著区域增强的视觉注意力预测模型的损失函数,包括:
40、所述损失函数采用三个显著性性能评价指标kl、cc、nss的加权线性组合。
41、可选地,所述确定所述基于非典型显著区域增强的视觉注意力预测模型中相关的超参数,包括:
42、预训练过程中采用随机梯度下降算法,初始学习率为10-4,并且每迭代3个epoch下降10倍,batchsize大小为10,预训练过程需要迭代20个epoch直至模型收敛。
43、可选地,所述采用已知的眼动数据集中的测试图像对训练后的所述基于非典型显著区域增强的视觉注意力预测模型进行测试,包括:
44、采用公开数据集salicon、mit1003和saliency4asd中提供的benchmark对训练后的所述基于非典型显著区域增强的视觉注意力预测模型进行测试,从而评估模型的性能。
45、根据本发明的另一个方面,提供了一种视觉注意力预测模型的构建系统,包括:
46、预测模型构建模块,该模块用于构建基于非典型显著区域增强的视觉注意力预测模型;
47、模型训练模块,该模块用于采用已知的眼动数据集对所述基于非典型显著区域增强的视觉注意力预测模型进行预训练,并采用孤独症群体的眼动数据集对所述基于非典型显著区域增强的视觉注意力预测模型进行修正,完成对所述基于非典型显著区域增强的视觉注意力预测模型的端到端训练;
48、模型测试模块,该模块用于采用已知的测试图像对训练后的所述基于非典型显著区域增强的视觉注意力预测模型进行测试,评估所构建模型的性能。
49、根据本发明的第三个方面,提供了一种视觉注意力预测方法,采用上述中任一项所述的视觉注意力预测模型的构建方法或构建系统构建得到的视觉注意力预测模型,对任一图像作为所述模型的输入,输出得到视觉注意力预测结果。
50、根据本发明的第四个方面,提供了一种计算机终端,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时可用于执行上述中任一项所述的方法。
51、根据本发明的第五个方面,提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时可用于执行上述中任一项所述的方法。
52、由于采用了上述技术方案,本发明与现有技术相比,具有如下至少一项的有益效果:
53、本发明提供的视觉注意力预测模型的构建方法、系统、终端及介质,采用基于非典型显著区域增强的视觉注意力预测模型,充分考虑了孤独症患者特有的非典型视觉注意模型和独特的视觉偏好,在孤独症眼动数据集上saliency4asd benchmark获得了极佳的性能。该性能的实现主要依赖于非典型显著区域增强技术的实施,其采用的跨阶背景增强操作有效地利用了特征提取网络的性质,从而在真值图的监督下能够更充分地学习到孤独症患者的特定视觉特点,并取得优异的性能。
54、本发明提供的视觉注意力预测模型的构建方法、系统、终端及介质,利用全局语义流技术来引导各阶的残差融合,降低了低阶特征中所包含噪声对模型性能的不利影响,提高了视觉注意力预测模型的准确性及鲁棒性。
55、本发明提供的视觉注意力预测模型的构建方法、系统、终端及介质,效率高,成本低,易于实现,并且十分灵活,可以根据实际需要部署在参数量更少的主干网(考虑效率)或者性能更好的主干网(考虑性能)上。
- 还没有人留言评论。精彩留言会获得点赞!