本发明涉及一种设计标准命名实体识别方法,具体涉及一种高速列车转向架设计标准命名实体识别方法。
背景技术:
1、高速列车转向架设计、制造、运维过程中,各主机厂积累了数据和知识,包括高速列车转向架设计、制造、运维各阶段的履历信息、技术标准、需求信息、设计参数、工艺参数、故障信息、维修信息等,这些数据存在于各个单位的多个业务系统中,并且以结构化、半结构化和非结构的形式存在,具有多源异构的特点。从结构化、半结构化数据中抽取出有价值的信息,其中重要的一步就是实体抽取。当前学者研究大多集中在bert-bilstm-crf命名实体识别算法,主要是使用bert语言模型进行文本特征提取获取字粒度向量矩阵,然后使用双向长短期记忆网络提取输入语句与上下文之间字与字的关系,最后使用条件随机场模型,根据标签之间的依赖关系提取全局最优的输出标签序列。当前研究都是从如何减少参数利用albert模型、模型融合、利用bilstm模型+cnn神经网络等方面进行模型改进。但这些算法的改进都需要基于海量的数据集训练,并未提出一种基于高速列车转向架领域的小数据量的实体抽取方法的研究。
2、通过对高速列车转向架的设计、制造等过程中的数据进行有效利用与分析,可以为转向架的性能优化提供重要价值。然而当前各阶段积累的数据的多源异构性以及专有语料库的缺乏,使数据缺乏完整性和一致性,导致实体识别的不准确,使数据的价值难以得到有效体现。
技术实现思路
1、为了实现上述发明目的,本发明提供了以下技术方案:
2、一种高速列车转向架设计标准命名实体识别方法,包括以下步骤:
3、步骤s1:提取文本数据,利用同义词替换和中-英-中互译进行数据增强,制作数据集;在步骤s1中,采集指定领域大量的未标注语料,获取训练所需数据;经数据增强后,再标注每一未标注语料中实体所在的位置,标注为bio标注格式,形成数据集;
4、步骤s2:构建网络模型,进行命名实体识别模型训练;
5、其中,步骤s2包括以下步骤:
6、步骤s21:构建albert预训练模型;
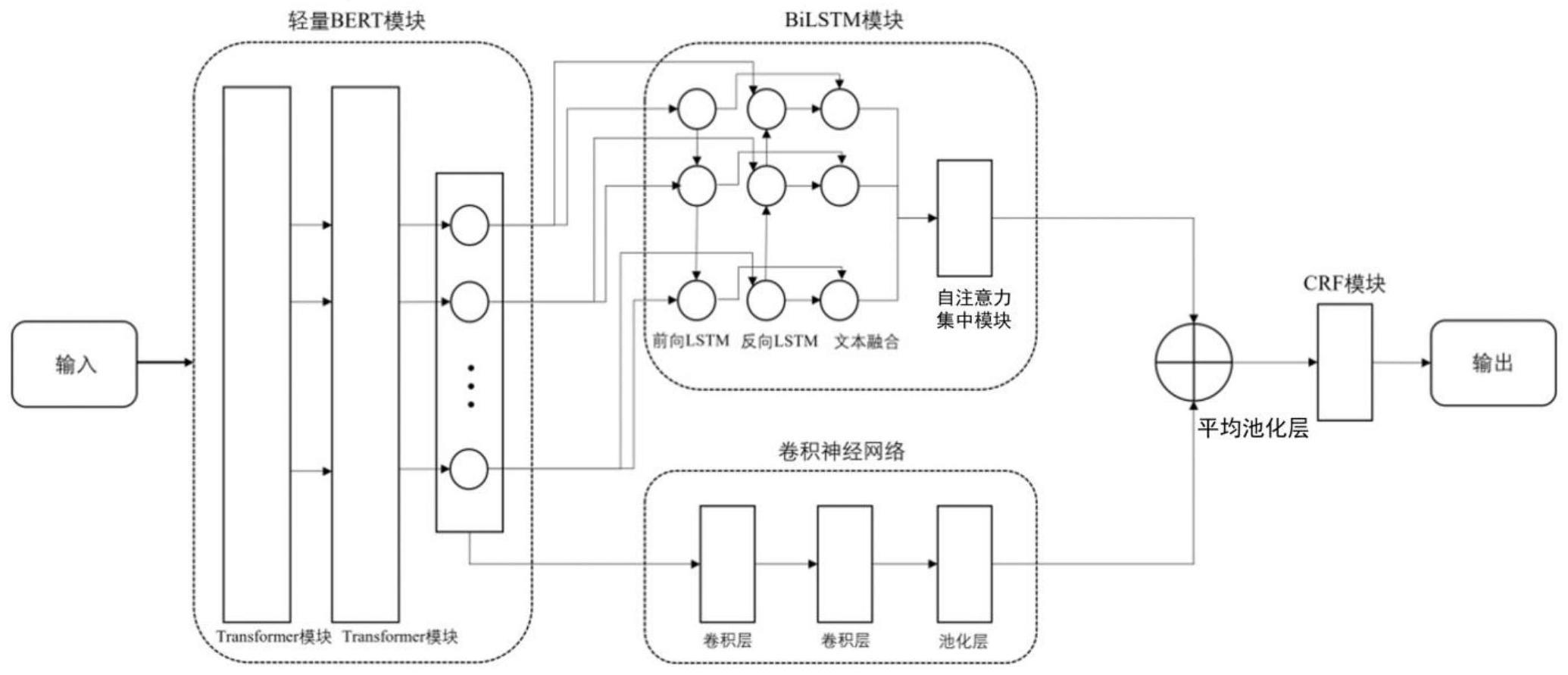
7、步骤s22:构建两层门控卷积神经网络和最大池化层;
8、步骤s23:构建使用自注意力机制模块改进的双向长短记忆网络模块;
9、步骤s24:信息融合;
10、步骤s25:构建条件随机场模块;
11、其中,步骤s21:构建albert预训练模型;albert模型的骨干网络使用transformer编码器和gelu非线性激活函数;指定词嵌入大小为e、编码器层数为l、隐藏层大小为h,前馈网络/滤波器大小设置为4h,将注意力head的数量设置为h/64;
12、其中,步骤s22包括步骤s221-步骤s224这4个步骤;
13、其中,步骤s221:为确保经过不同卷积核卷积后的语句长度与输入语句长度一致,采用输入输出大小一致填充策略对输入语句进行零向量填充,由于不同语句的长度不同,将输入的长短不一的语句两端进行补零操作,即将不同长度的语句开头和结尾两侧平均填入0之后补充到设置的句子最大长度;
14、其中,步骤s222:两层门控卷积模块包含两个部分:门控卷积层和池化层;将步骤s21步骤的输出作为本步骤的输入先通过2路门控卷积层,其中卷积核大小分别为2*sw和4*sw,其中sw为步骤s21输出的词向量的长度;
15、其中,步骤s223:经过两层卷积核提取之后的数据进入门控单元进行激活,使用relu和sigmoid激活函数进行激活;
16、其中,步骤s224:两路卷积层的输出进行连接操作后,输入到最大池化层中;
17、其中,步骤s23中,在bilstm层后引入自注意力机制模块对隐藏层的输出h做进一步处理;采用自注意力机制对bilstm的输出进行处理,使得模型注意力更加集中于所需提取的实体上,采用的自注意力集中机制网络结构计算过程如式(1)到式(4)所示:
18、m=tanh(h) (1)
19、
20、r=hαt (3)
21、h*=tanh(r) (4)
22、式(1)到式(4)中:h即维度为n×sw的字向量矩阵,是下层bilstm的输出,α是经过softmax激活函数激活后的字向量矩阵,t代表矩阵的转置,n是字向量矩阵的维度,sw是字向量序列的长度,h矩阵首先通过tanh激活函数得到字向量矩阵m,再通过一层softmax层后得到权重矩阵,将h字向量矩阵与权重矩阵相乘得到中间计算过程量r,将r通过tanh激活函数激活后得到输出向量h*,最后将得到的输出向量h*输入到softmax层后得到对应的全局时序特征向量;
23、步骤s24:信息融合;使用一层平均池化层将步骤s22的输出和步骤s23的输出进行融合,输入出至s25步骤中,步骤s24包括步骤s241-s242;
24、步骤s241:将s22步骤输出的文本细粒度特征和s23步骤输出的文本全局时序特征进行拼接,拼接的计算过程如式(5)所示;
25、
26、其中:fe为连接之后得到的多粒度特征向,th为步骤s22输出的细粒度时序特征向量,gl为步骤s23输出的全局时序特征向量;
27、步骤s242:将得到的多粒度时序特征向量输入到平均池化层中,将向量fe映射到多个分类空间中,从而得到预测信息pr。
28、步骤s25:将s24步骤输出的预测信息pr输入到该模块中,以获得最优标签序列。
29、其中,步骤s1包括以下步骤:
30、步骤s11:提取数据;
31、步骤s12:数据增强;
32、步骤s13:对数据进行人工标注。
33、步骤s11包括:收集高速列车转向架知识文本,通过网络获取大量文本作为数据源,经过人工检查、清洗后得到所需高速列车转向架相关各类文本数据。
34、步骤s12包括:(1)使用同义词替换进行数据增强,该方法将替换一个语句中随机个数的词语,将这些词语更改为它们的同义词,该方法期望通过更改句子中的同义词语来构建新的句子,从而达到增强数据量的目的;(2)将文本翻译为不同语言,再译为中文,增加语料数据的细节;(3)使用对抗生成网络,生成关键同义词,进行数据增强。
35、步骤s13使用bart软件对步骤s12产生的数据进行人工标注,将其表述为bio标注格式,最终形成所需数据集。
36、与现有技术相比,本发明的有益效果:
37、(1)发明人在实践中发现传统的bert–bilstm–crf模型,依赖大量数据集进行训练且需要大量的训练数据。对此,本发明公开了一种高速列车转向架设计标准命名实体识别方法。其中,该方法包括基于改进的albert-bilstm-crf模型提取转向架设计标准数据本体。模型首先利用albert预训练模型将句子语义转化为文本向量,随后根据转向架领域设计标准数据集特征进行动态调整获取动态词向量,随后将词向量分别送入基于自注意力集中机制改进的bilstm网络和两层卷积神经网络中提取特征信息,充分利用两个模型的优点,使得模型可以提取语句中的多粒度特征,从而提高小数据集中的实体关系抽取性能。
38、(2)发明人在实践中发现原有的bert模型使用了mask机制掩盖了部分文本信息,不适用于只有少量数据集模型的训练,因此,本发明针对bert模型进行改进,经过实验发现,mask机制导致模型欠拟合,最终导致模型精准度大幅降低,本发明取消了其中含有的mask机制部分,并在此基础上,还运用了对抗神经网络生成同义词进行数据增强,进一步扩充原有的数据集。
39、(3)发明人在实践中发现转向架设计领域存在设计标准预料不足的问题,对此,本发明提出利用同义词和中-英-中互译的方法增加现有的语料数据集,从而防止因为语料过少而出现过模型拟合的现象,同时也提高了转向架模型实体抽取的精确度。
40、(4)发明人在实践中发现了现有技术在进行转向架领域实体抽取任务时,对专有名词的提取性能有限,对此本发明统计转向架领域专有名词,设计两个大小分别为2×sw和4×sw的卷积核和最大池化层(ebsfnet)进行细粒度关系抽取,有效的提升了2~4字长专有名词的提取效率。
41、(5)发明人在实践中发现纯卷积神经网络如textcnn存在对语法信息编码不足的问题,对此,本发明提出使用bilstm解决单词之间的依赖关系,并且将位置信息、词汇、句法和语义信息相融合,再使用自注意力机制重点学习序列内部的特征信息。
42、(6)发明人在实践中发现由于原始数据中句子长度不同会导致输入矩阵维度不同,对此,本发明提出将数据集中的每条句子做补零操作,将长度不同的语句执行补零,使句子长度统一到模型设置的句子的最大长度,同时为了保证输出层和输入层维度的统一。