一种基于分层强化学习的可迁移三维重建方法及系统
本发明涉及计算机工程应用、计算机图形学、计算机辅助设计、三维重建,尤其涉及一种基于分层强化学习的可迁移三维重建方法及系统。
背景技术:
1、三维重建在工程领域发挥着重要作用。近年来,它在计算机辅助设计(cad)、三维打印、三维事故重建等应用中取得了显著的成功。经典的方法是训练神经网络直接从图片预测三维形状。但是该过程无法解释或无法获得详细的重建过程,因此很难应用于工程领域。
2、为了使重建过程具有可解释性,lin等人提出了一种使用强化学习,模仿人类建模者进行三维重建的方法。首先根据图片得到一个粗粒度的三维形状,然后对该三维形状添加loops进行细分,训练一个代理对loops的对角进行拖动使得三维形状更接近目标形状。它提供了一个可以解释的重建过程。
3、然而,目前上述方法仍存在以下两方面的技术问题:(1)重建精度受制于复杂的动作空间,搜索空间随着动作空间的增长呈指数级增长。代理很难搜索到最优动作,导致学习效率和准确性较低。(2)对不同类别数据,代理训练时并没有考虑从其他类别的代理迁移知识进行学习。
技术实现思路
1、本发明提出了一种基于分层强化学习的可迁移三维重建方法及系统,简化了动作空间使得重建过程更容易,提升了重建准确度同时增加了代理在不同类别数据间的迁移性,加快了代理的收敛速度。
2、为了达到上述目的,本发明第一方面提供了一种基于分层强化学习的可迁移三维重建方法,包括:
3、s1:基于目标深度图像和目标形状得到一个粗粒度的三维形状;
4、s2:对得到的粗粒度的三维形状添加n个loops,得到待编辑三维形状,一个loop是指一个首尾相接的长方形;
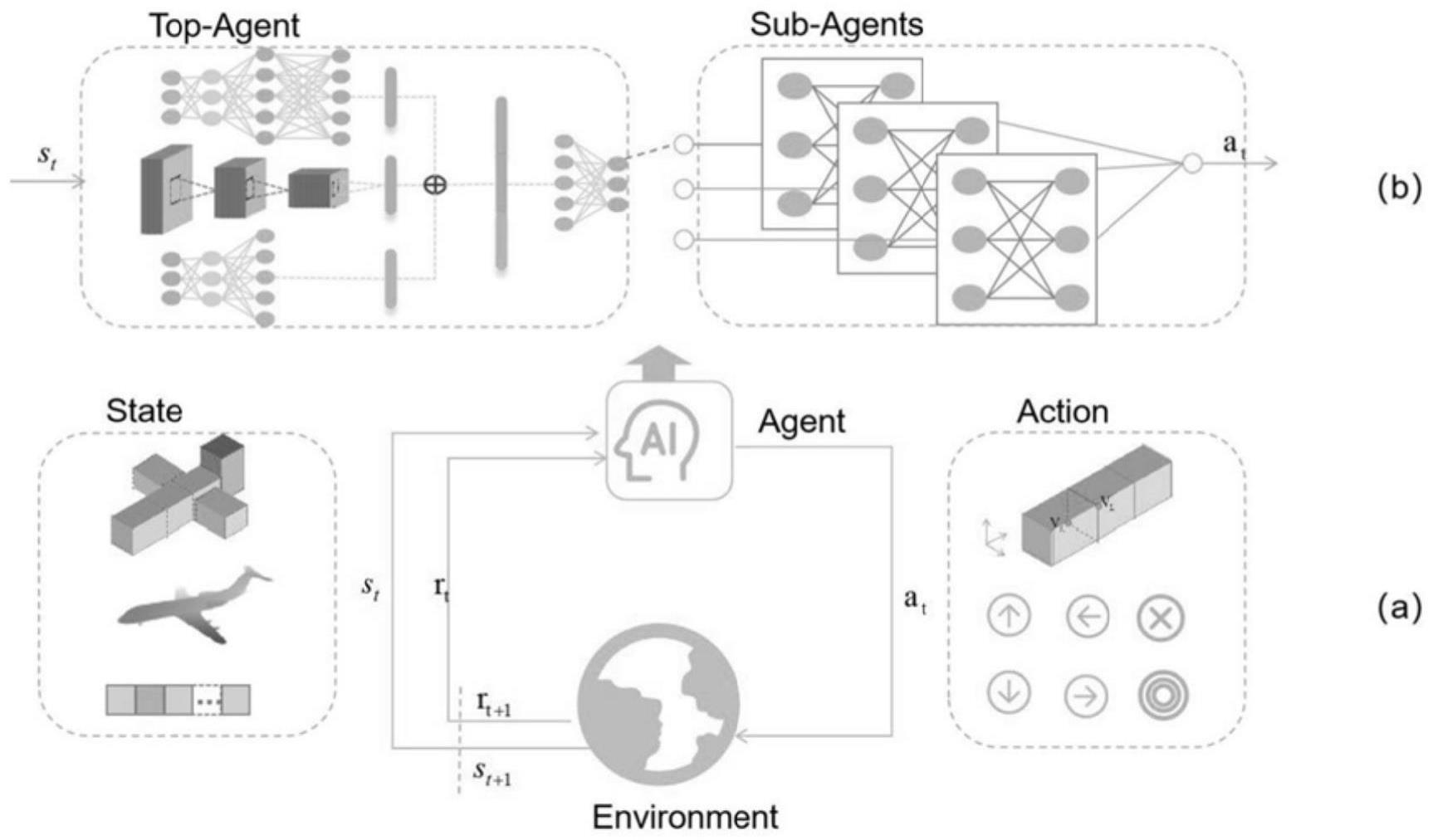
5、s3:将待编辑三维形状、目标深度图像以及采用one-hot编码的时刻数输入顶层代理中,由顶层代理选择一个loop;
6、s4:将选择的loop的特征作为基于状态空间增强的子代理ass-sub-agent输入状态的增强,输出要对该loop执行的基本动作;
7、s5:将输出对该loop执行的基本动作的应用于该loop,得到更新后的待编辑三维形状,时刻数增加1,将得到的回报值指导顶层代理与基于状态空间增强的子代理的训练,并重复执行步骤s3~s5直到进入终止状态。
8、在一种实施方式中,步骤s1包括:
9、基于现有三维数据集shapenet得到目标深度图像及其对应的三维体素形状,作为训练数据;
10、采用训练数据对卷积神经网络进行训练,得到训练好的卷积神经网络,利用训练好的卷积神经网络基于目标深度图像和目标形状输出一个粗粒度的三维形状,该粗粒度的三维形状由一组长方体原语集合组成。
11、在一种实施方式中,步骤s2中待编辑三维形状为:
12、
13、其中,li为第i个loop的特征值,为loop两个对角的坐标,n为loop的数量。
14、在一种实施方式中,步骤s3包括:
15、将待编辑三维形状l、目标深度图像ig以及采用one-hot编码的时刻数sp作为状态,即s={l,ig,sp},将s输入顶层代理,输出n个值,分别对应操作loops的预测值函数q,训练阶段以预设概率贪心选择值函数最大的loop,得到该loop的特征值,其中,训练顶层代理的损失函数如下:
16、
17、其中st代表当前时刻t的状态,ω代表时刻t所选择的loop,st+k代表基于当前loop执行k步后的状态,ω'代表在时刻t+k,值函数最大的loop,θω是顶层代理的网络参数,qω代表基于当前参数和状态选择该loop可得到的值函数;rt+k代表从时刻t到时刻t+k的累积折扣回报,公式如下:
18、rt+k=rt+1+γrt=2+...+γk-1rt+k
19、其中,γ、γk-1是折扣因子,包含于[0,1],rt+1代表在时刻t+1获得的回报,下标代表的是时刻数,rt+k代表在时刻t+k时刻获得的回报;
20、使用编辑形状与目标形状的交并比作为重建准确度的评估,动作执行前后iou的差值作为执行该动作的回报,动作是指ass-sub-agent输出的基本动作,并将其作用于顶层代理选择的loop上。
21、在一种实施方式中,步骤s4包括:
22、将得到的loop的特征作为状态的增强,即sω={l,ig,sp,lω},将sω输入ass-sub-agent,输出基本动作的值函数qω,训练阶段以预设概率贪心选择值函数最大的基本动作;
23、对ass-sub-agent的训练采用ddqn,损失函数定义如下:
24、
25、其中θ和θ'分别代表当前子代理和目标子代理的网络参数,st+1、st分别代表时刻t+1、当前时刻t的状态,γ为折扣因子,at为当前时刻t执行的动作,定义如下:
26、
27、使用s替代上式的st+1,a替代上式的得到:
28、
29、其中,βω(s)代表在状态s下选择新的loop的概率;
30、对该loop的基本动作定义为对该loop两个对角的拖动,拖动方向为x,y,z三个方向。
31、在一种实施方式中,步骤s5中的终止状态为执行了预设步后的状态。
32、基于同样的发明构思,本发明第二方面提供了一种基于分层强化学习的可迁移三维重建系统,包括:
33、粗粒度的三维形状获得模块,用于基于目标深度图像和目标形状得到一个粗粒度的三维形状;
34、待编辑三维形状获得模块,用于对得到的粗粒度的三维形状添加n个loops,得到待编辑三维形状,一个loop是指一个首尾相接的长方形;
35、loop选择模块,用于将待编辑三维形状、目标深度图像以及采用one-hot编码的时刻数输入顶层代理中,由顶层代理选择一个loop;
36、基本动作输出模块,用于将选择的loop的特征作为基于状态空间增强的子代理ass-sub-agent输入状态的增强,输出要对该loop执行的基本动作;
37、三维重建模块,用于将输出对该loop执行的基本动作的应用于该loop,得到更新后的待编辑三维形状,时刻数增加1,将得到的回报值指导顶层代理与基于状态空间增强的子代理的训练,并重复执行loop选择模块至三维重建模块的步骤直到进入终止状态。
38、基于同样的发明构思,本发明第三方面提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被执行时实现第一方面所述的方法。
39、基于同样的发明构思,本发明第四方面提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现第一方面所述的方法。
40、相对于现有技术,本发明的优点和有益的技术效果如下:
41、本发明提出了一种基于分层强化学习的可迁移三维重建方法及系统,通过简化动作空间从而增加重建的准确度,同时由于代理用于解决更简单的问题,训练参数量更少,不容易出现过拟合的情况,此外状态增强提升了训练数据的多样性,因此使得训练出来的代理在不同类别间更具有可迁移性;分层强化学习将对同一个loop操作的动作进行聚合,从而将任务分解给不同的代理进行处理;顶层代理能够在全局上对整体形状进行把握,选择出最需要进行调整的loop,并将其交给对应的子代理进行处理;使用基于状态空间增强的子代理(ass-sub-agent)替代传统方法中的一组子代理,ass-sub-agent能够共享原子代理的训练过程并且拥有更少的训练参数,能够加速子代理的训练过程,更多样的状态空间又促进了ass-sub-agent的迁移性。
- 还没有人留言评论。精彩留言会获得点赞!