基于图像低级外观信息和高级语义信息结合的候选区域生成方法
本发明涉及图像中的候选区域生成,尤其是涉及一种基于图像低级外观信息和高级语义信息结合的候选区域生成方法。
背景技术:
1、候选区域生成是目标检测、目标分割等高级计算机视觉任务的基础和关键步骤,它的目的是为图像中所有对象预测许多与类别无关的边界框。如何有效地生成尽可能少却又能覆盖所有对象的候选区域是业界研究的主要挑战。
2、候选区域生成算法是目标检测等高级计算机视觉任务的基础,传统的候选区域生成算法通常利用颜色、纹理等低级的外观信息,用滑动窗口框选择候选区域,如edge boxes(zitnick c l,dollár p.edge boxes:locating object proposals from edges[c]//european conference on computer vision.springer,cham,2014:391-405.)、selectivesearch(uijlings j r r,van de sande k e a,gevers t,et al.selective search forobject recognition[j].international journal of computer vision,2013,104(2):154-171.)等,但是它们生成的候选区域结果准确率会比较低。
3、随着深度学习的兴起,有许多研究采用卷积神经网络获取图像高级语义作为候选区域生成的线索的策略,例如在候选区域生成领域可以作为基准的经典结构rpn(ren s,hek,girshick r,et al.faster r-cnn:towards real-time object detection withregion proposal networks[j].advances in neural information processingsystems,2015,28.)。尽管这些基于深度学习的方法显著提高候选区域生成的效果,但是它们使用的数据集只能给出有限类别的对象的标注。因此,这些有监督的候选区域生成方法生成的区域对应的类别也是有限的。然而在现实世界的应用中,通常需要不同且多样类别的候选区域,这就需要提供开放类别的候选区域。
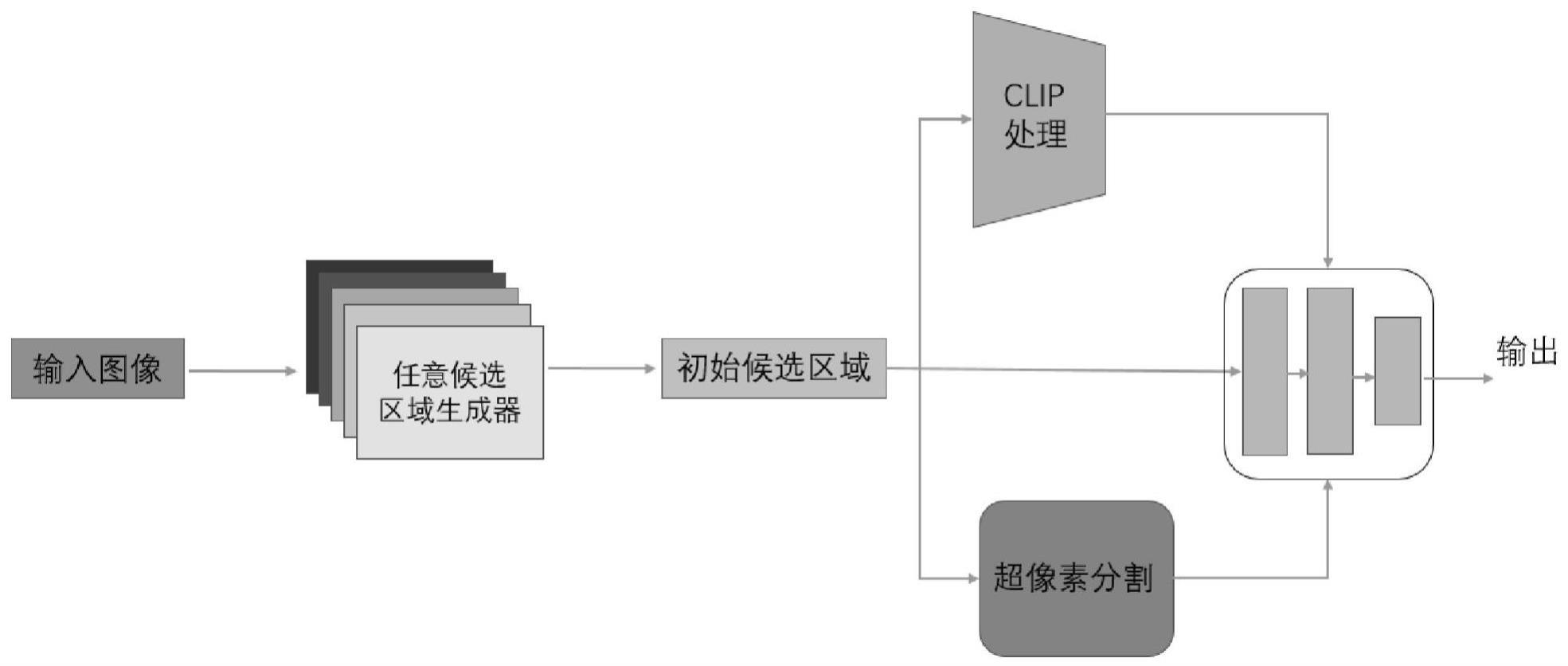
4、目前候选区域生成研究有两个重点研究方向,一方面是减少引入的监督,用弱监督、无监督等方法进行候选区域生成,以减少标注的工作量。另一方面是趋向于零样本检测,让生成的候选区域不局限于训练集的类别,对开放类别也有良好的表现。目前目标检测领域中最先进的面向开放类别目标检测无监督候选区域生成方法(shi h,hayat m,wu y,et al.proposalclip:unsupervised open-category object proposal generation viaexploiting clip cues[c]//proceedings of the ieee/cvf conference on computervision and pattern recognition.2022:9611-9620.)是结合这两点,用任意一种候选区域生成器去生成初始候选区域,再利用基于对比的文本-图像预训练模型clip(radford a,kim j w,hallacy c,etal.learning transferable visual models from naturallanguage supervision[c]//international conference on machine learning.pmlr,2021:8748-8763.)对类别名称提取文本特征,对图像中的每个候选区域提取视觉特征,通过计算二者之间的余弦相似度和相似熵,得到它们的相关性,以此对候选区域进行挑选和重排,提供了一个面向开放类别的体系架构,解决rpn这样基于深度学习的候选区域生成方法难以生成开放类别的候选区域的问题。此外,再以建立连通图的无向子图方式,对零碎的候选区域进行融合,并简单选择伪标签进行和fast r-cnn(girshick r.fast r-cnn[c]//proceedings of the ieee international conference on computer vision.2015:1440-1448.)一样的坐标回归,提高最终结果的准确率。
5、基于这样的背景,本发明以面向开放类别目标检测无监督候选区域生成方法为基础,在最后的坐标回归部分进行改进。既利用clip获取的高级语义信息,还引入低级外观信息,用超像素跨越的分数(alexe b,deselaers t,ferrari v.what is an object?[c]//2010ieee computer society conference on computer vision and patternrecognition.ieee,2010:73-80.)对每个候选区域进行衡量,判断其是否覆盖一个完整的对象,以此得到用来训练回归部分的高质量伪标签,同时在训练中也融入超像素跨越的分数,在coco数据集(lin t y,maire m,belongie s,et al.microsoft coco:commonobjects in context[c]//european conference on computer vision.springer,cham,2014:740-755.)上进行训练和测试,最终得到效果更好的候选区域,这一部分同样弥补传统候选区域生成算法准确率低的问题。整个方法即插即用,提高生成的候选区域的精确率的同时,还具有良好的泛化性。
技术实现思路
1、本发明的目的在于针对传统基于深度学习的候选区域生成方法在面向开放类别时表现不好的缺点,以及需要大量监督信息的局限性,提供一种基于图像低级外观信息和高级语义信息结合的候选区域生成方法。最终得到效果更好的候选区域,弥补传统候选区域生成算法准确率低的问题。整个方法即插即用,提高生成的候选区域的精确率的同时,还具有良好的泛化性。
2、本发明包括以下步骤:
3、1)采用候选区域生成器对输入图像进行初始的候选区域生成;
4、2)将步骤1)在字典中存好的初始候选区域送入clip,利用clip对初始候选区域进行视觉特征的提取,以及对coco数据集的类别名称进行文本特征的提取,计算视觉特征、文本特征二者之间的余弦相似度和相似熵;
5、3)对初始候选区域进行超像素分割,计算候选区域对应的超像素跨越分数;
6、4)结合初始分数、相似熵和超像素跨越分数选择候选区域作为伪标签,以超像素跨越分数和余弦相似度为损失函数的权重,对候选区域进行坐标回归的训练,得到更高质量的候选区域。
7、在步骤1)中,所述采用候选区域生成器对输入图像进行初始的候选区域生成的具体步骤可为:
8、(1)选用任意侯选区域生成器;
9、(2)用侯选区域生成器对来自coco数据集的输入图像进行候选区域的生成;
10、(3)将每个图像对应的生成出的候选区域的坐标、初始分数和相应图像编号存入字典中。
11、在步骤3)中,所述对初始候选区域进行超像素分割,计算候选区域对应的超像素跨越分数的具体步骤可为:
12、(1)对和步骤1)相同的输入图像进行超像素分割;
13、(2)计算步骤1)在字典中存好的初始候选区域对应的超像素跨越分数;
14、(3)将每个初始候选区域的超像素跨越分数存入到步骤1)得到的字典中。
15、在步骤4)中,所述得到更高质量的候选区域的具体步骤可为:
16、(1)挑选拥有前20%高初始分数的候选区域、拥有前5%低相似熵的候选区域、拥有前5%高超像素跨越分数的候选区域;
17、(2)对这三类挑选出的候选区域取交集,将交集候选区域作为伪标签,若是交集为空,则选取初试分数最高的候选区域作为伪标签;
18、(3)将每个候选区域对应的超像素跨越分数和视觉特征、文本特征间的余弦相似度作为训练坐标回归部分的损失函数的权重;
19、(4)对候选区域进行坐标回归的训练,得到更高质量的候选区域。
20、本发明具有以下突出优点:
21、1)本发明克服传统的基于深度学习的候选区域生成方法在面对未见过类别时表现不好的局限性,首次考虑结合图像低级外观信息和高级语义信息的方法,不仅利用超像素跨越分数在纹理、颜色这些外观方面衡量候选区域是否完全覆盖了一个对象,还利用clip提取候选区域的视觉特征和类别名称的文本特征,计算二者的相似度,得到图像的深层特征和高级语义信息,构建一种结合图像浅层特征与深层特征的方法,设计实现了整体结构,得到了更加准确和精细的候选区域。
22、2)本发明是无监督方法,不需要大量的标签信息,克服了监督方法中需要人工标注导致工作量过大、过于耗时的缺点。只利用图像和图像中蕴含的信息,不需要精确的候选区域坐标,就可以得到高质量的候选区域。
23、3)本发明的实验结果在各项指标上平均提升2%左右,与其他被对比的候选区域生成方法相比,本发明的结果都要更好。并且整个方法即插即用,在提高生成的候选区域的精确率的同时,还具有良好的泛化性。
- 还没有人留言评论。精彩留言会获得点赞!