一种基于视觉技术的是否正确佩戴口罩检测方法
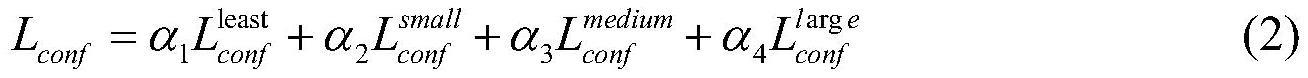
本发明属于人工智能中视觉,具体地说,是一种基于视觉技术的是否正确佩戴口罩检测方法。
背景技术:
1、目前已知新冠病毒传播最主要途径就是飞沫传播,因此在公共场合正确配搭口罩显得尤其重要。近几年国内公共场合也开始逐步重视卫生健康安全,努力确保公共场合下的人们正确佩戴口罩。但就现存的公共场合下口罩安检方案仍存在着很多问题,诸多细节方面存在不足之处,且自动化程度较低。
2、目前已有的口罩佩戴检测有以下方案:
3、(1)基于人力的口罩佩戴检测方案
4、人力安检是指采用传统人工的方式,让安检人员佩戴好口罩等防疫装备处于公共场合的进出口位置。以人眼判别的方式对进出口的人员进行是否佩戴口罩的判断。
5、(2)基于传统肤色判别的口罩佩戴视觉检测方案
6、该方案首先需要使用人脸检测器,去捕获目标人脸。然后,使用hsv颜色空间或是ycrcb颜色空间对目标的人脸肤色面积和非肤色面积进行提取计算,通过一定阈值关系判断目标人物是否佩戴口罩。
7、(3)基于深度学习的口罩佩戴视觉检测方案
8、通过搭建目标检测神经网络,制作佩戴口罩的数据集,对目标检测网络进行训练,得到对应的目标检测器,直接对目标人物是否佩戴口罩进行检测。
9、人力安检是否佩戴口罩方案形式简单且操作方便,但是由于人与人彼此接触的关系,很容易导致交叉感染的发生,并且由安检人员去判读目标人物是否正确佩戴口罩太过主观化,容易出现纰漏;基于传统肤色判别的口罩佩戴视觉检测方案,首先依赖于人类检测器优异程度,其次使用单一颜色空间提前肤色对于复杂光照与类似肤色的口罩辨别效果很差,极易影响判别结果,同时,无法判断常态化判断目标是否正确佩戴口罩;基于深度学习的口罩佩戴视觉检测方案是现在比较主流的方法之一,但是目前较多情况下目标检测网络仅可以判断目标人物是否佩戴口罩,不能判断目标是否正确佩戴口罩,基于深度学习的口罩佩戴视觉检测方案十分依赖于训练集中对不规范佩戴口罩标定的质量,由于实际检测时目标人物佩戴口罩的差异,对于这情况这种方案鲁棒性较弱易受干扰、泛化性较弱难以推广。
技术实现思路
1、本发明的主要目的在于克服现有视觉检测与标定技术的缺陷,设计了一种基于视觉技术的是否正确佩戴口罩检测方法。本发明基于yolov3设计了一种改进的cbam-yolov3-sppf算法,同时通过对比人脸中人眼,鼻子,嘴巴等关键信息的检测情况判断目标人物是否正确佩戴口罩。本发明所设计的检测方法主要针对正面照的情况进行检测识别,该方法不仅极大提高了检测精度,而且可以有效判断出目标人物是否正确规范佩戴口罩。
2、本发明采用的具体技术方案如下:
3、一种基于视觉技术的是否正确佩戴的口罩检测方法,包括以下步骤:
4、s1:制作检测对象数据集,在现有large-scale celebfaces attributes(celeba)dataset人脸属性数据集中随机抽取10000张有效图片,使用labelimg软件标定出所选10000张图片中的人眼,鼻子和嘴巴,并将其随机划分成训练集8000张以及测试集2000张;
5、s2:对现有yolov3-spp算法中k-means聚类先验框大小的算法进行改进,使用sppf模块对yolov3-spp网络模型进行改进,在检测头head部分额外增加一个大尺寸的特征输出图,并在检测程序模块head中融合cbam注意力机制模块,得到改进后的cbam-yolov3-sppf算法;
6、s3:利用步骤s1所制作的数据集对cbam-yolov3-sppf算法进行训练,将训练后得到的最佳权重文件重新回馈至cbam-yolov3-sppf算法得到目标检测网络;
7、s4:使用上述目标检测网络检测目标,结合检测到的人眼,鼻子,嘴巴等信息后,采用一种特定位置肤色面积测量的方法判别目标人物是否正确佩戴口罩;
8、本发明的进一步改进,所述s1的过程包括:
9、s1.1、获得大量含有人脸五官特征的高清图片:
10、使用所写的python脚本随机从公开的large-scale celebfaces attributes(celeba)dataset人脸属性数据集中抽取10000张不同的有效人脸图片;
11、s1.2、将所抽取的10000张图片进行目标标定制作成数据集:
12、使用labelimg软件对每张人脸图片中的人眼,鼻子,嘴巴区域画目标标记框,目标在图像中的位置信息指目标标记框的宽高信息(可以间接求出),目标标记框的对角点在图像坐标系下的坐标信息。自动生成的.xml文件无法被yolo网络所训练,使用python脚本voc_yolo将xml文件格式转换为txt文件格式。转换成的txt文件包含:类别id编号,目标中心点x坐标/图片总宽度,目标中心点y坐标/图片总高度,目标框的宽带/图片总宽度,目标框的高度/图片总高度。转换完成后,将其分为8000个训练集,以及2000个测试集。
13、本发明的进一步改进,所述s2的过程包括:
14、s2.1、改进k-means聚类算法,计算yolov3-spp的先验框大小:
15、该算法首先利用聚类中心距离远近的关系和轮盘赌算法去选取优秀的初始聚类中心,随后采用k-means聚类算法进行迭代更新,最后再对聚类出的12个anchor数值进行变异微调,以寻求最优的anchor数值;
16、s2.2、yolov3-spp网络模型改进:
17、改进后得到的cbam-yolov3-sppf网络模型由backbone、neck和head三部分构成,其中backbone采用darknet53结构,用来进行特征提取,将原先neck部分的spp模块替换为sppf模块,构成sppf加fpn的组合,增强特征图特征表达能力的同时提高推理速度,在head检测头部分额外增加一个大尺寸的特征输出图,提高网络对小型目标的检测精度,在四个检测头head中分别加入cbam注意力机制模块,提高网络学习能力。
18、本发明的进一步改进,所述s3的过程包括:
19、将训练集中的样本图像经过mosaic数据增强方法处理后,输入到的cbam-yolov3-sppf算法中,通过不断更新权值直到损失函数趋于稳定且最小时,保留训练得到的权重文件,将其加载到cbam-yolov3-sppf算法中,制作成目标检测网络。
20、本发明使用的损失函数为ciou_loss函数,该损失函数由三部分构成:目标置信度损失lconf(o,c),目标定位偏移量损失lciou和目标分类损失lcla(o,c)
21、l(o,o,c,c,t,g)=λ1lconf(o,c)+λ2lcla(o,c)+λ3lciou (6)
22、其中,λ1,λ2,λ3是平衡系数,lconf(o,c)为目标置信度损失,lciou为目标定位偏移量损失,lcla(o,c)为目标分类损失。特别地,针对改进得到的cbam-yolov3-sppf网络结构4个检测头head的目标置信度损失添加不同大小权重:
23、
24、上式(7)中,α1,α2,α3,α4为权重系数并且满足α1>α2>α3>α4的条件,而依次为尺寸从大到小的特征输出图所计算出的目标置信度损失。
25、其中,目标置信度损失:
26、
27、目标置信度损失lconf(o,c)采用的是二值交叉熵损失,其中oi∈{0,1},表示预测目标边界框i中是否真实存在目标,0表示不存在,1表示存在。表示预测目标矩形框i内是否存在目标的sigmoid概率。
28、目标类别损失:
29、
30、目标分类损失lcla(o,c)采用的也是二值交叉熵损失,其中oij∈{0,1},表示预测目标边界框i中是否真实存在第j类目标,0表示不存在,1表示存在。表示网络预测目标边界框i内存在第j类目标的sigmoid概率。
31、目标定位偏移量损失:
32、
33、目标定位偏移量损失lciou则采用的是ciou loss函数进行计算,其中,bpred、bgt为预测框和真实框的中心点位置,ρ2(bpred,bgt)为两框中心位置的欧氏距离,c为两框外接矩形的对角线距离。α可以理解为权重系数,根据定义可知损失函数会向重叠区域大的方向优化,v衡量了预测框与目标框长宽比的相似性,wgt、hgt为真实框的宽与高。
34、本发明的进一步改进,所述s4的过程包括:
35、使用训练好的目标检测网络对目标人物进行检测(此处判断测到目标是否为眼睛,鼻子,嘴巴等,均属于调用yolo算法中判别模块,即检测目标得分大于设定阈值,该步骤仅为应用没有独创,因此不展开详述),当检测到目标同时具备眼睛,鼻子,嘴巴的时候,判断为目标未佩戴口罩;当检测到目标只有眼睛时,进一步确定目标人物是否正确佩戴口罩;取检测到两眼框外接最小矩形的宽与两倍高,在其最小外接矩形的下方再取一个矩形,记此区域为鼻部决策区域,计算其面积,记作s1;本发明设计了一种h-crcb方法于鼻部决策区域提取肤色计算其肤色面积,记作s2,若s2>αs1(α为决策阈值,初始值设为0.4),则认为目标未正确佩戴好口罩,反之,则认为目标人物正确佩戴口罩。
36、与现有技术方案相比,本发明具有以下有益效果:
37、(1)本发明对现有yolov3-spp算法进行了改进,设计了改进k-means聚类算法求解先验锚框大小,提高k-means聚类先验框速度的同时也提高了聚类效果。并对yolov3-spp网络模型结构进行改进优化,提高了对人眼,鼻子,嘴巴检测精度的同时保证了较好的检测速度;
38、(2)本发明相较于深度学习的口罩佩戴视觉检测方案显得更加灵活多变,不仅可以实现对目标是否佩戴口罩的检测,而且可以高精度地判别出目标人物是否正确佩戴口罩。同时,对目标规范佩戴口罩的判定不再固化,可以通过对决策阈值的调整,动态改变对目标规范佩戴口罩的要求程度;
39、(3)设计的h-crcb提取肤色方法,可以在各种复杂环境光下,有效精准地检测出肤色区域。同时,有效克服光照不足时对于白色口罩区域可能出现误检为肤色区域的情况,提高目标是否正确佩戴口罩检测精度;
40、(4)本发明不采用直接对目标口罩佩戴情况进行检测的方案,而是使用间接方法进行检测判决,此方法将不需要依赖于训练集中对不规范佩戴口罩的标定质量。本发明中的方案在实际检测目标是否正确佩戴口罩时,具有很好的鲁棒性与泛化性。
- 还没有人留言评论。精彩留言会获得点赞!