一种基于超混沌储备池集成计算的钢铁企业副产煤气系统流量预测方法
本发明属于信息,具体涉及一种基于超混沌储备池集成计算的钢铁企业副产煤气系统流量预测方法。
背景技术:
1、国家“双碳”战略倡导绿色、环保、低碳的生活方式,于钢铁企业而言节能、减排、降耗势在必行。钢铁生产过程中产生的副产煤气具有体量大、利用不充分的特点,是否能够合理利用副产煤气将直接影响到企业的节能降耗效果,所以对副产煤气系统实施优化调度非常必要。副产煤气是钢铁企业炼铁、炼焦和炼钢过程中产生的重要二次能源,是钢铁企业能源系统的重要组成部分,由于副产煤气的产生与冶炼过程紧密相关,而副产煤气的消耗又与热轧、冷轧等生成过程紧密相关,因此副产煤气系统具备多情境、耦合性、非线性和不确定性的特点,建立副产煤气系统的优化调度模型极具困难的。了解和掌握副产煤气系统各产生和消耗环节的运行规律,挖掘各产生和消耗环节的内部运行动态,对产生和消耗环节的流量进行准确预测具有重要价值,可以有效辅助调度人员制定调度计划。
2、目前关于钢铁企业副产煤气流量数据模型的辨识和预测已有大量的研究,主要是将副产煤气的实时监测数据视作时间序列,然后通过基于时间序列预测的方法来建立数据驱动的模型,常用的方法如神经网络、支持向量机、高斯过程回归等。但上述这些方法往往存在着如下的不足:(1)对具有类周期运行规律的数据具有较好的辨识效果,而对于内部动态复杂的数据往往效果偏差;(2)一种方法即便调整参数往往也只适用于某一种数据序列或者某一类数据序列,泛化能力偏弱;(3)工业数据普遍是含有噪声的,上述方法应对噪声的能力不够。
3、目前实际应用中,对钢铁企业副产煤气系统数据的模型辨识与预测,往往依据不同的数据特点来选择不同的方法,比如具有类周期特点的可以采用机器学习的方法,而对于非周期性的数据往往结合生产计划、检修计划或技改项目等因素,建立简单的模型进行预测。上述方法的不足在于:(1)类周期数据虽然更容易建立模型,但用于优化调度的参考价值相对较低,调度人员往往可以依靠人工经验,也能做出准确的预判;(2)复杂数据内部动态挖掘不够,大多数情况下即便有准确的生产计划和检修计划,但是副产煤气运行过程还受其它不确定性影响,挖掘出这部分不确定性更具有价值。
技术实现思路
1、针对现有技术中存在的上述问题,本发明提出了一种基于超混沌储备池集成计算的钢铁企业副产煤气系统流量预测方法,设计合理,克服了现有技术的不足,具有良好的效果。
2、为实现上述发明目的,本发明采用如下技术方案:
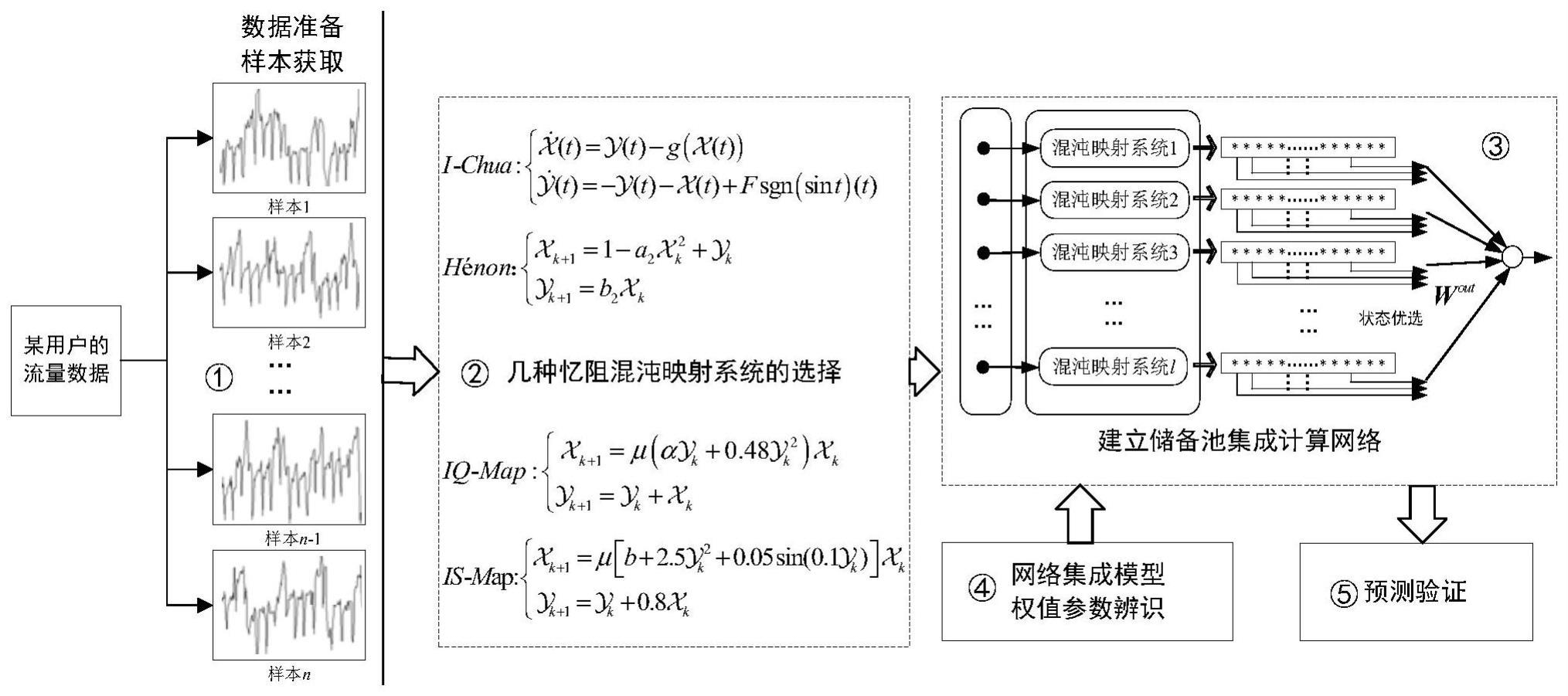
3、一种基于超混沌储备池集成计算的钢铁企业副产煤气系统流量预测方法,包括以下步骤:
4、s1、从钢铁企业现场实时数据库中读取所需的副产煤气流量运行数据,对实时数据进行预处理,利用滑动时间窗的方法将原始数据按等时间间隔截取成为数据片段,构建模型辨识所需的数据样本;
5、s2、根据数据样本的特点,选择合适的忆阻混沌映射系统;
6、s3、将忆阻混沌映射系统作为储备池单元,建立储备池集成计算网络模型,计算储备池单元的输出状态,并对输出状态进行精简;
7、s4、以s3中精简后的输出状态为储备池集成计算网络模型输出层的输入,以目标预测值作为输出,基于贝叶斯线性回归方法辨识网络模型的权值参数;
8、s5、利用测试样本对所建立的网络模型进行预测验证。
9、进一步地,在步骤s1中,从钢铁企业现场实时数据库读取副产煤气系统某用户的流量运行数据,数据序列记为{u*(1),u*(2),…,u*(k),…},将原始数据进行归一化,归一化公式如下:
10、
11、其中,u(k)为对应于数据点u*(k)的归一化数据,为所有数据点中取值最大的数据,为所有数据点中取值最小的数据;
12、通过归一化将原始数据全部映射到[0,1]之间,然后将副产煤气系统流量运行数据利用滑动时间窗划分为有限段的等时间间隔的数据片段,如式(2)所示:
13、
14、其中,l为输入样本的长度,n为样本的个数,si={ui,ti}为样本集中的第i个样本;将样本数据集中70%的数据样本作为训练样本,余下的30%作为测试样本,记训练样本集中样本的个数为n1,测试样本集中样本的个数为n2。
15、进一步地,在步骤s2中,针对给定的用户流量数据,通过实验的方法选择适合该用户特点的忆阻混沌映射系统作为储备池单元,用于产生储备池输出状态;
16、以四种已报道的忆阻混沌映射系统为研究对象,四种忆阻混沌映射系统的数学模型如下:
17、
18、其中,和表示忆阻器的内部状态,变量f为输入层参数,b1为中间层参数;
19、
20、其中,和表示忆阻器的内部状态变量,a2为输入层参数,b2为中间层参数;
21、
22、其中,和表示忆阻器的内部状态变量,λ为输入层参数,a为中间层参数;
23、
24、其中,和表示忆阻器的内部状态变量,μ为输入层参数,b为中间层参数;
25、首先,根据经验设置上述四种忆阻混沌映射系统的参数取值范围,然后通过实验数据代入反复循环确定最佳参数,使得每个忆阻混沌映射系统均具有超混沌特性;其次,将用户训练样本的输入数据给到如式(3)所示的忆阻混沌映射系统,令其产出储备池状态,将储备池输出状态作为输入,输出权值参数作为未知量,目标预测值作为输出,然后利用最小二乘法辨识输出权值参数,从而建立预测模型;再次,利用测试数据样本来测试式(3)所示的忆阻混沌映射系统对该用户流量数据的适应性,选择预测误差作为适应性评价标准,选用均方根误差作为预测误差,均方根误差表达式为:
26、
27、其中,n2为测试样本数据的数量,yi为预测值,ti为目标值;
28、最后,将上述测试方法分别用于式(4)、(5)、(6)所示的忆阻混沌映射系统,比较四类忆阻混沌映射系统的性能差异,最终确定适合该用户数据的忆阻混沌映射系统。
29、进一步地,在步骤s3中,将s2中选择的合适的忆阻混沌映射系统作为储备池单元,当公式(6)所示的系统作为储备池计算单元最为合适时,将(6)中参数μ作为系统的可变输入参数,b作为系统参数;由于一个忆阻混沌映射系统只有1个输入入口μ,而输入样本的维度是l,因此需要将输出样本中的l个数据输送给l个忆阻混沌映射系统,建立储备池集成计算网络模型,由l个输入样本数据产生l组储备池神经元状态;
30、由于μ只有在一定的取值范围μmin<μ<μmax内,系统才会产生超混沌特性,因此采用如下公式将输入数据映射到上述取值范围内:
31、μ(i)=μmin+(μmax-μmin)u(i) (8)
32、其中,u(i)为步骤1中归一化后的输入样本中的第i个数据点,μ(i)为输送给忆阻混沌映射系统的数据;
33、假设忆阻混沌映射系统的维度是n×n,最终得到的储备池输出状态是一个l×n的矩阵,即得到l×n个状态,如下式所示:
34、
35、每隔m个状态选择一个有效的储备池状态,m的大小根据忆阻混沌映射系统的维度n以及输入样本的维度l来确定,保证每组n个状态值保留下m个状态,m<n/2,则最终保留的储备池有效状态的个数为l×m个,将这些状态作为输入,目标预测值作为输出,利用基于贝叶斯线性回归的方法求解网络输出权值。
36、进一步地,在步骤s4中,给定训练样本集其中si={ui,ti},根据步骤s3,基于输入ui计算的储备池输出状态记为xi,储备池集成计算网络模型的输出权值记为wout,则目标输出ti描述为:
37、ti=woutxi+εi (10)
38、其中,εi是观测噪声,用零均值高斯白噪声来描述;
39、利用贝叶斯原理来求解wout,将对wout的求解转化为对wout的后验分布的求解,即求解p(wout|s):
40、
41、其中,p(s)=∫p(s|wout)p(wout)dwout是归一化因子;
42、目标输出的概率分布描述为:
43、
44、其中,是一个与输出分布相关的超参数;若数据样本之间是独立的,则似然函数表述为:
45、
46、对于权值参数的先验分布,在先验信息知之甚少的情况下,利用高斯分布描述:
47、
48、其中,α是与权值分布方差相关的超参数;
49、根据式(11)、(13)和(14),权值参数的后验分布描述为:
50、
51、求解最优的权值参数即求解使式(15)最大时的wout,采用最大似然估计的方法求解式(15)的最大值,令:
52、
53、则将问题简化为对式(16)的最小值的求解,将权值参数的后验分布假设为高斯分布,并利用taylor级数展开,得:
54、
55、其中,a是m(wout)的hessian矩阵;则权值参数的后验分布表示为:
56、
57、其中,
58、式(16)中含有两个位置的超参数α和β,利用贝叶斯原理求出权值参数与超参数之间的函数关系,再采用梯度下降的方法估计wout,α和β。
59、进一步地,在步骤s5中,给定测试样本集其中,si'={ui′,ti′},首先基于忆阻混沌映射系统计算出储备池输出状态xi′,然后利用贝叶斯推理,求得集成计算网络模型的输出的分布:
60、p(ti′|xi′,s')=∫p(ti′|xi′,wout)p(wout|s')dwout (19)
61、将式(12)和式(18)代入到式(19)中得到:
62、
63、将式(20)整理成高斯分布的形式:
64、
65、其中,ymp为预测分布的均值,即预测值,为预测分布的方差。
66、本发明具有如下有益效果:
67、本发明在对副产煤气系统的流量进行预测时,充分考虑副产煤气流量数据内部蕴含复杂动态的事实,采用混沌映射系统来提取数据中隐含的复杂动态,并根据不同的数据特点选择不同的混沌映射系统,提升模型的泛化能力;工业数据动态复杂,因此往往需要构造维度偏高的输入样本,如果将混沌映射系统作为储备池内部计算单元就会使得储备池产生大量状态,为后续网络权值参数辨识带来困难,本发明将通过实验的方法对储备池输出状态进行状态精简,有效降低储备池输出状态的维度,减小计算量;因工业数据普遍存在噪声,为降低噪声影响,本发明采用基于贝叶斯线性回归的参数辨识方法,可以有效提升对网络的权值参数的辨识效果。本发明能够充分利用现有的副产煤气系统流量数据,有效预测当前时间后副产煤气系统煤气流量的变化情况,从而为副产煤气系统的平衡调整提供在线决策支持。
- 还没有人留言评论。精彩留言会获得点赞!