基于图像增强和多传感器融合的挖掘机夜间物体检测方法
本发明涉及物体检测,尤其是指一种基于图像增强和多传感器融合的挖掘机夜间物体检测方法。
背景技术:
1、挖掘机作为工程机械行业最受青睐的重型设备,其应用在节省人力、提高工作效率方面起到了不可估量的作用。目前传统挖掘机驾驶仍依靠人工观察,增加了在非结构化环境中施工的风险。尤其当挖掘机在夜间等较为昏暗的环境下工作时,无论是驾驶室还是周围的行人或车辆都会存在潜在的风险。
2、物体检测是实现挖掘机智能化的第一步,当前主流的方法大致有两类,一类是基于计算机视觉检测技术,主要方法包括传统的hog+svm方法,此方法存在局限性,仅仅在行人不被遮挡且直立的情况下能实现不错的检测效果,无法满足挖掘机工况下的行人多尺度多姿态问题。除此之外,还有目前机器人领域较为流行的yolo系列算法,此类方法检测速度快但缺乏深度距离信息,不利于夜间检测。虽然计算机视觉检测技术当前较为成熟,但是显然这类方法很大程度上依赖相机的图像质量,而且常规的rgb相机无法在夜间正常工作,这也导致检测算法在夜间的检测效率大大降低。另一类方法是采用激光雷达传感器,通过雷达侦测物体的点云,以此来设计防碰撞函数,规避障碍物。虽然激光雷达的优势在于不受光照影响,且具备准确的三维深度信息,不过这类方法由于缺乏图像信息,无法准确区分行人和其他障碍物。
技术实现思路
1、为此,本发明所要解决的技术问题在于克服现有技术中夜间各类物体检测准确率较低且无法获取物体在三维空间里的准确位置。
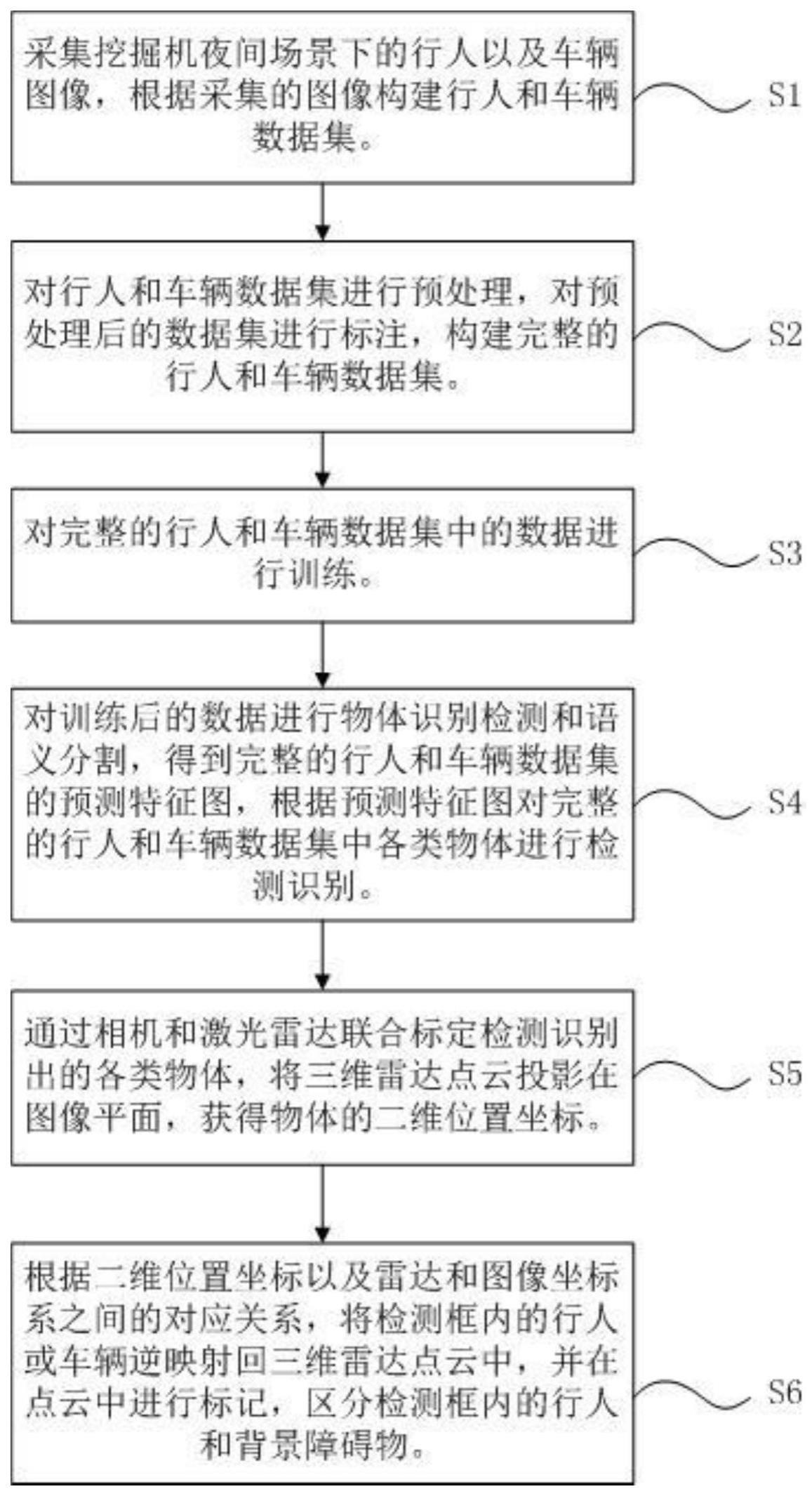
2、为解决上述技术问题,本发明提供了一种基于图像增强和多传感器融合的挖掘机夜间物体检测方法,包括:
3、步骤s1、采集挖掘机夜间场景下的行人以及车辆图像,根据所述采集的图像构建行人和车辆数据集;
4、步骤s2、对所述行人和车辆数据集进行预处理,对所述预处理后的数据集进行标注,构建完整的行人和车辆数据集;
5、步骤s3、对所述完整的行人和车辆数据集中的数据进行训练;
6、步骤s4、对所述训练后的数据进行物体识别检测和语义分割,得到所述完整的行人和车辆数据集的预测特征图,根据所述预测特征图对所述完整的行人和车辆数据集中各类物体进行检测识别;
7、步骤s5、通过相机和激光雷达联合标定所述检测识别出的各类物体,将三维雷达点云投影在图像平面,获得物体的二维位置坐标;
8、步骤s6、根据所述二维位置坐标以及雷达和图像坐标系之间的对应关系,将检测框内的行人或车辆逆映射回三维雷达点云中,并在点云中进行标记,区分检测框内的行人和背景障碍物。
9、在本发明的一个实施例中,所述步骤s1中所述采集挖掘机夜间场景下的行人以及车辆图像具体包括:
10、所述行人图像的种类为多个行人、行人被遮挡、行人蹲姿等多姿态多尺度图像。
11、在本发明的一个实施例中,所述步骤s2中对所述行人和车辆数据集进行预处理的方法为:
12、对所述行人和车辆数据集原始红外图像进行直方图均衡化,通过改变图像的直方图来改变图像中各像素的灰度,提高图像对比度;
13、对所述行人和车辆数据集原始图像和二维高斯函数进行卷积,对图像进行加权平均,去除噪声,使用的函数如下:
14、
15、其中,gσ(x,y)是二阶高斯函数,σ∈r是高斯正态分布的标准差;
16、设定不同的标准差,将两个相邻高斯尺度空间的图像相减,得到特征检测图像,得到高斯差分的响应值图像,对图像进行增强,构建高清行人和车辆数据集,公式为:
17、
18、其中,g1(x,y),g2(x,y)为二阶高斯函数,f(x,y)为输入图像中点的坐标。
19、在本发明的一个实施例中,所述步骤s2中对所述预处理后的数据集进行标注的方法为:
20、使用labeling标注工具标注所述高清行人和车辆数据集中的行人和车辆,如图2所示,标注行人和车辆框的左上角和右下角x-y坐标,生成包含行人和车辆框坐标信息的xml文件,构建所述完整的行人和车辆数据集。
21、在本发明的一个实施例中,所述步骤s3中对所述完整的行人和车辆数据集中的数据进行训练的方法为:
22、利用yolo-v5目标检测算法训练所述xml文件中的数据,进行设定轮次的迭代训练,获得训练后的数据。
23、在本发明的一个实施例中,所述步骤s4中得到所述完整的行人和车辆数据集的预测特征图的方法为:
24、利用yolo-v5算法的backbone主干网络部分来提取特征,得到原始输入特征图;
25、利用pspnet金字塔场景解析网络中的金字塔池化模块来提取上下文信息进行语义分割,金字塔池化模型分为多个层级,将多个层级提取的特征图融合为全局特征;
26、将原始输入特征图和全局特征进行拼接,提取到同时携带局部和全局上下文信息的特征图;
27、通过一层卷积生成预测特征图。
28、在本发明的一个实施例中,所述步骤s5中获得物体的二维位置坐标的方法为:
29、获得所述通过相机和激光雷达联合标定检测识别出的各类物体中心点在像素平面下的坐标信息,图像坐标系到相机坐标系到雷达坐标系之间的映射关系如图4所示,映射关系如下:
30、
31、其中,为物体中心点在雷达坐标系下的坐标,为物体中心点在相机坐标系下的坐标,为物体中心点在图像坐标系下的坐标;
32、三维雷达点云到二维位置坐标转换关系为:
33、
34、其中,fx为x轴方向焦距的像素长度,fy为y轴方向焦距的像素长度,cx,cy为相机原点的平移尺寸,fx,fy,cx,cy为相机内参,r为3×3旋转矩阵,t为3×1平移向量;
35、根据所述转化关系,将雷达中的点云投影到图像上,误差计算公式如下:
36、
37、其中,为图像中实际像素坐标,(xu,i,yu,i)为点云投影在图像中的像素坐标。
38、在本发明的一个实施例中,所述步骤s6中区分检测框内的行人和背景障碍物的方法为:
39、保留所有原始的激光雷达点云;
40、通过设定距离,来提取出所述原始激光雷达点云中显示在红外图像视野范围内的点云并保存;
41、通过联合标定获取的旋转矩阵r和平移向量t,将点云投影在二维图像平面,使点云和图像中的物体位置重合,并记录每个点云的编号;
42、运行基于yolo-v5主干网络的识别和分割,获取物体在图像坐标系中的坐标范围,记录在物体检测框内的每个点云的编号,通过在雷达点云中索引对应的编号,实现二维到三维的逆映射,获取物体的深度信息;
43、将逆映射求解到的点云进行颜色标记,区分和背景无关障碍物的点云。
44、在本发明的一个实施例中,在所述步骤s6完成后还包括:
45、根据所述区分出的检测框内的行人和背景障碍物设置不同的警戒阈值,通过物体距离挖掘机阈值变化触发不同程度的声光报警,实现根据距离大小的分段预警。
46、本发明还提供一种挖掘机夜间物体检测装置,包括:
47、信息采集模块,用于采集挖掘机夜间场景下的行人以及车辆图像,根据所述采集的图像构建行人和车辆数据集;
48、图像处理模块,用于对所述行人和车辆数据集进行预处理,对所述预处理后的数据集进行标注,构建完整的行人和车辆数据集;
49、数据训练模块,用于对所述完整的行人和车辆数据集中的数据进行训练;
50、检测识别模块,用于对所述训练后的数据进行物体识别检测和语义分割,得到所述完整的行人和车辆数据集的预测特征图,根据所述预测特征图对所述完整的行人和车辆数据集中各类物体进行检测识别;
51、获取模块,用于通过相机和激光雷达联合标定所述检测识别出的各类物体,将三维雷达点云投影在图像平面,获得物体的二维位置坐标;
52、位置确定模块,用于根据所述二维位置坐标以及雷达和图像坐标系之间的对应关系,将检测框内的行人或车辆逆映射回三维雷达点云中,并在点云中进行标记,区分检测框内的行人和背景障碍物。
53、相应的,本发明实施例还提供了一种检测设备,包括:
54、存储器,用于存储计算机程序;
55、处理器,用于调用所述存储器中存储的计算机程序,按照程序执行上述基于图像增强和多传感器融合的挖掘机夜间物体检测方法。
56、相应的,本发明实施例还提供了一种计算机可读非易失性存储介质,包括计算机可读指令,当计算机读取并执行所述计算机可读指令时,使得计算机执行上述基于图像增强和多传感器融合的挖掘机夜间物体检测方法。
57、本发明的上述技术方案相比现有技术具有以下优点:
58、本发明所述的一种基于图像增强和多传感器融合的挖掘机夜间物体检测方法,首先采集挖掘机夜间场景下的行人及车辆图像,构建行人和车辆数据集,对数据集进行预处理,对预处理后的数据集进行坐标标注生成包含行人和车辆框坐标信息的xml文件,对文件中的数据进行训练,获得训练后的数据,对训练后的数据进行物体识别检测和语义分割,通过相机和激光雷达联合标定,将三维雷达点云投影在图像平面,获得物体的二维位置坐标,最后根据雷达和图像坐标系之间的对应关系,将检测框内的行人或车辆逆映射回三维雷达点云中并进行标记,以区分检测框内的行人和背景,不仅提高物体识别和分割的准确率,又能够提供准确的物体空间位置定位。
- 还没有人留言评论。精彩留言会获得点赞!