一种结合用户行为数据的问答交互方法及装置与流程
本发明涉及自然语言处理领域,提供了一种结合用户行为数据的问答交互方法及装置。
背景技术:
1、技术背景(当前工作依赖的nlp算法)
2、计算机应用技术——自然语言处理方向:当前场景需要结合用户在个性化问卷中反馈的结果与数据库中已有的行为标签、商品信息数据进行大小数据交融,为用户提供更适合、更具有针对性的服务,在这个过程中需要使用到自然语言处理相关算法。
3、管理与信息科学——电子商务方向:当前场景基于电商平台的问卷信息,其目的是为了更好地维持用户黏性,通过生成个性化问卷的方式尽最大可能了解用户兴趣,并能够自动而有效地回答用户的问题,从而实现吸引用户购物的目的。这个过程中,需要使用电子商务领域数据的特征构建上述所有文本内容。
4、当前工作需要将不同来源和类别的数据融合在一起,为用户提出的问题给出一个合理的答案,因此主要的技术方向是混合编码策略与机器问答。混合编码策略的目的在与将不同来源的数据使用不同参数的编码器生成多组隐藏向量表示,再将这些向量表示通过拼接、相加、加权相加等策略生成一组融合向量,用于后续解码。在这个过程中,编码器需要用到预训练模型,以实现对样本数据的通用语义捕捉过程。用到的预训练模型包括:roberta、xlnet、gpt3,将某用户曾经的问卷数据、用户画像数据和指定商品数据融合起来,用于后续的问答过程。机器问答的目的在于能够自动回答用户提出的问题,将已有的混合编码和用户的问题组合起来,生成答案。在这个过程中,使用到的技术包括gcn、pointernetwork、模板匹配。gcn用于处理文本中的链接关系,为远距离文本关联提供了解决方案;pointer network生成处理词库对答案的映射,以获取答案关键词;模板匹配策略可以使得答案具备可读性,使得语句通顺。
5、现有技术的解决策略
6、当前解决这个问题的通用方案为机器问答。机器问答的过程可以表述为:将问题和依赖的文本拼接起来,然后使用编码器进行编码,并使用解码器获取原文位置的关键词,再将结果关键词映射到模板空缺中,得到最终的答案。这个方案中的重点在于编码器和解码器的处理策略,即选择何种编码器和解码器以及如何将数据以正确的流程导入这个流式框架中。编码器和解码器需要使用同源词向量的对应关系,因此若使用bert作为编码器,则需要同时使用bert作为解码器,然后将它与指针层、softmax层或crf层拼接,以得到映射的结果。数据导入过程的常规方案是顺序导入,即以“编码器-解码器-映射过程”的顺序进行。当存在多类数据时,在编码器部分使用合并、嵌入策略进行。现有策略存在不能很好地处理多源数据融合条件下产生的问题,当数据来源不同,在信息量层面上的表现不同时,直接拼接的策略难以直接准确地将这些信息进行归类并作特征值提取,而这是当前项目解决的关键问题。当前项目将原始信息分类、转化为固定类别之后,能够实现对特征值的整合、简化,从而提高准确率。
技术实现思路
1、本发明的目的在于解决现有方法中随机性较高的数据未被简化、归类化,从而噪声较大对影响最终结果的准确性。现有的方法对生成的数据没能很好的先将文本中的内部关联挖掘出来影响结果精准性。
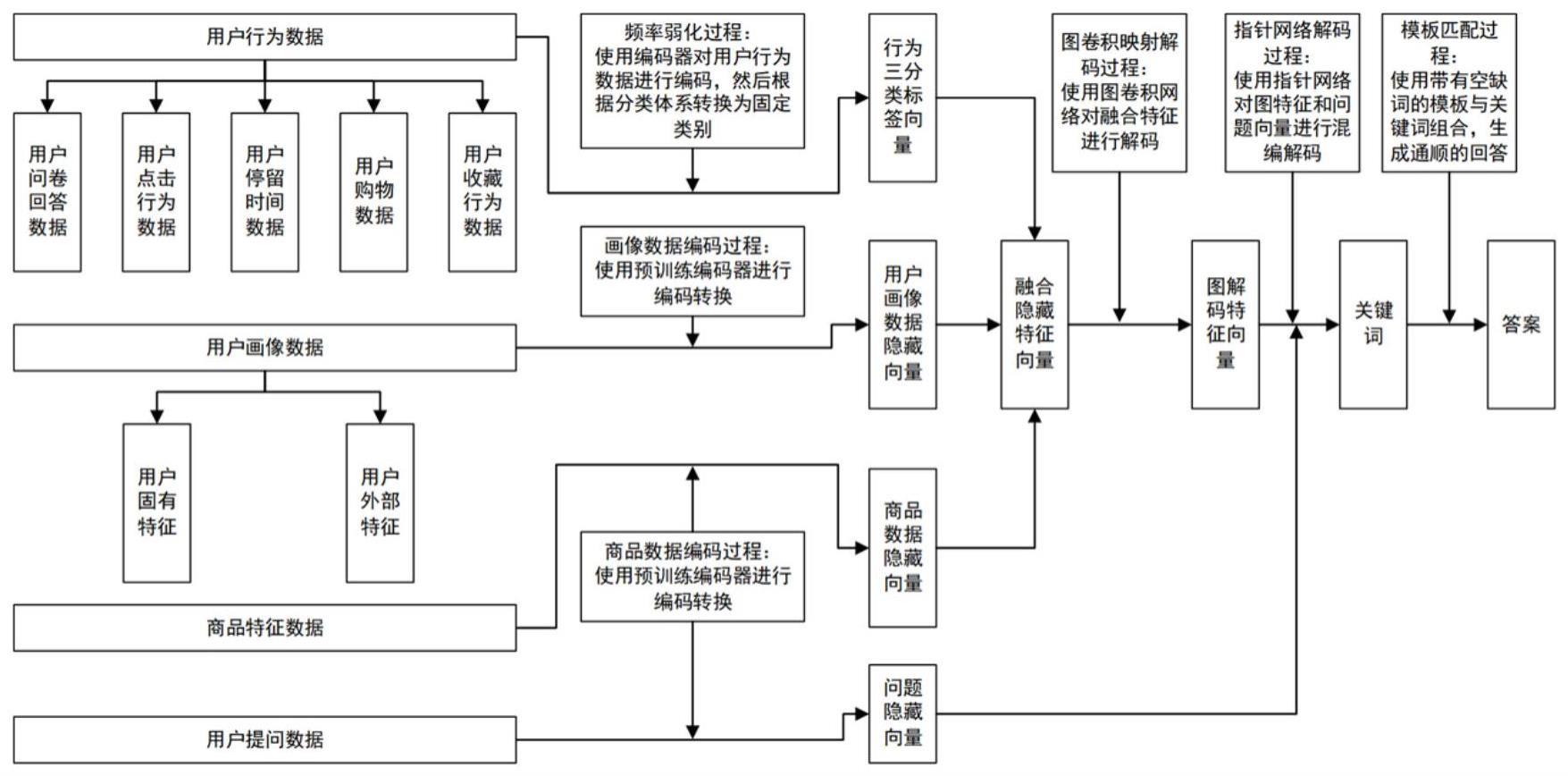
2、一种结合用户行为数据的问答交互方法,包括以下步骤:
3、步骤1:对用户数据中的用户提交的问卷数据、用户行为数据进行“频率弱化”操作和特征编码操作,生成三分类标签向量。
4、步骤2:对用户固有的画像数据进行编码,得到用户画像的隐藏向量;
5、步骤3:对商品信息数据和用户提问数据使用相同的编码器进行编码,分别得到商品数据隐藏向量和问题隐藏向量。
6、步骤4:对三分类标签向量、用户画像的隐藏向量、商品数据隐藏向量进行融合特征提取,得到融合隐藏特征向量,融合过程同时使用拼接、加权相加融合方式,然后经过一个线性映射过程,保证融合后的结果与单一向量的维度保持一致;
7、步骤5:对融合隐藏特征向量进行图卷积映射解码,得到图解码特征向量;
8、步骤6:对图解码特征向量和问题隐藏向量融合的组合进行指针解码,得到答案关键词。
9、步骤7:对答案关键词进行模板匹配,得到最终的答案。
10、上述技术方案中,步骤1包括以下步骤:
11、步骤1.1、用户的行为数据分为五类数据,具体为用户回答问卷的数据、用户点击行为数据、用户停留时间数据、用户购物数据、用户收藏行为数据,用户的行为数据经过编码器编码之后,得到多组中间结果隐藏向量;
12、步骤1.2、多组中间结果隐藏向量经过三分类器之后,得到对应的多组三分类结果,收集这些三分类结果,并整合成一个向量,即为三分类标签向量
13、三分类标签向量保存的是实际结果重编码之后的结果,用户的行为数据为xa,则根据上述五类数据可以将此数据分为[xa1;xa2;xa3;xa4;xa5],则这样的数据经过三分类标签向量的过程如下:
14、vp=wp(softmax(wm[xa1;xa2;xa3;xa4;xa5]+bm))+bp
15、上述公式中wm和bm为三分类融合的计算参数,通过softmax函数映射到给定的结果空间,wp和bp为映射到三分类标签向量的计算参数,vp为三分类标签向量,映射过程中使用线性映射过程。
16、上述技术方案中,步骤2具体包括以下步骤:
17、用户的画像原始数据包含两类数据,具体为用户固有特征和用户外部特征,固有特征包括用户年龄、性别这些短时间内的不可变特征,外部特征包括用户当前位置(ip地址)、用户主要登录时间、用户总消费金额这些可变特征;
18、用户固有特征和用户外部特征,经过编码器编码,然后拼接成一个用户画像的隐藏向量,设用户画像数据为xb,则根据上述两类数据可以将此数据分为[xbx,xbo],则用户画像的编码过程由公式描述如下:
19、vu=wu([xbx;xbo])+bu
20、上述公式中wu和bu为画像数据编码的计算参数,vu为得到的用户画像数据隐藏向量,因为不需要进行融合转换,因此不再嵌套内层的公式。
21、上述技术方案中,步骤3具体包括以下步骤:
22、步骤3.1、商品特征和用户提问数据分别为xc和xq,使用同一组公式进行表达:
23、[vi;vq]=wf([xc;xq])+bf
24、上述公式中的中wf和bf为画像数据编码的计算公式,vi和vq为得到的商品隐藏向量和问题隐藏向量。
25、上述技术方案中,步骤5包括以下步骤:
26、步骤5.1、两两构建一个初始的权重,然后使用gcn模型对整体的权重矩阵进行多次的拉普拉斯算子迭代输出,更新这个权重;
27、最后一次得到的权重与原始数据做矩阵乘法,得到图解码特征向量,公式描述如下:
28、
29、上述公式中wg和bg为图解码过程的计算参数,ag为图解码过程边关联权重的矩阵,在初始化过程,ag的主对角线上的参数均为1,其余的参数使用正态分布随机初始化,从而在训练过程中找到不同来源向量之间的权重,将ag非主对角线上的元素表现出来。
30、上述技术方案中,步骤6具体包括以下步骤:
31、指针网络寻找解码后的向量,然后映射到结果词库中,作为输出的关键词,过程使用公式描述如下:
32、α(t)=softmax(m(t)+wpcrossattention(vg,vq,vq)+bp)
33、wt=vgα(t)
34、m(t+1)=m(t)+α(t)
35、上述公式中α(t)代表在t时刻由图解码向量和问题隐藏向量做交叉注意力机制之后得到的权重分布,用于在编码文本中选择关键词,m(t)代表t时刻的历史叠加权重分布,wt为t时刻选择的关键词,与此同时将m(t)更新为m(t+1),供下一个时刻解析关键词使用。
36、上述技术方案中,步骤7具体包括以下步骤:
37、模板匹配时会根据词性和词分类结果将具备实际含义的词放入不同的位置中,最终得到一个通顺的答案,其中设定的模板包含标准回复模板、无效回复提示信息,得到的关键词会放入标准回复模板中,利用斯坦福大学句法解析树完成对词性的分析,防止词汇填入错误的位置,如果判断用户的问题没有答案或表述不清,则会选择后者,同时提醒用户重新进行提问。
38、本发明还提供了一种结合用户行为数据的问答交互装置,包括以下模块:
39、三分类标签向量模块:对用户数据中的用户提交的问卷数据、用户行为数据进行“频率弱化”操作和特征编码操作,生成三分类标签向量;
40、用户画像的隐藏向量模块:对用户固有的画像数据进行编码,得到用户画像的隐藏向量;
41、商品数据隐藏向量和问题隐藏向量模块:对商品信息数据和用户提问数据使用相同的编码器进行编码,分别得到商品数据隐藏向量和问题隐藏向量;
42、融合模块:对三分类标签向量、用户画像的隐藏向量、商品数据隐藏向量进行融合特征提取,得到融合隐藏特征向量,融合过程同时使用拼接、加权相加融合方式,然后经过一个线性映射过程,保证融合后的结果与单一向量的维度保持一致;
43、图解码特征向量模块:对融合隐藏特征向量进行图卷积映射解码,得到图解码特征向量;
44、答案关键词模块:对图解码特征向量和问题隐藏向量融合的组合进行指针解码,得到答案关键词;
45、匹配模块:对答案关键词进行模板匹配,得到最终的答案。
46、上述装置中,三分类标签向量模块包括以下步骤:
47、步骤1.1、用户的行为数据分为五类数据,具体为用户回答问卷的数据、用户点击行为数据、用户停留时间数据、用户购物数据、用户收藏行为数据,用户的行为数据经过编码器编码之后,得到多组中间结果隐藏向量;
48、步骤1.2、多组中间结果隐藏向量经过三分类器之后,得到对应的多组三分类结果,收集这些三分类结果,并整合成一个向量,即为三分类标签向量
49、三分类标签向量保存的是实际结果重编码之后的结果,用户的行为数据为xa,则根据上述五类数据可以将此数据分为[xa1;xa2;xa3;xa4;xa5],则这样的数据经过三分类标签向量的过程如下:
50、vp=wp(softmax(wm[xa1;xa2;xa3;xa4;xa5]+bm))+bp
51、上述公式中wm和bm为三分类融合的计算参数,通过softmax函数映射到给定的结果空间,wp和bp为映射到三分类标签向量的计算参数,vp为三分类标签向量,映射过程中使用线性映射过程。
52、上述装置中,用户画像的隐藏向量模块具体包括以下步骤:
53、用户的画像原始数据包含两类数据,具体为用户固有特征和用户外部特征,固有特征包括用户年龄、性别这些短时间内的不可变特征,外部特征包括用户当前位置、用户主要登录时间、用户总消费金额这些可变特征;
54、用户固有特征和用户外部特征,经过编码器编码,然后拼接成一个用户画像的隐藏向量,设用户画像数据为xb,则根据上述两类数据可以将此数据分为[xbx,xbo],则用户画像的编码过程由公式描述如下:
55、vu=wu([xbx;xbo])+bu
56、上述公式中wu和bu为画像数据编码的计算参数,vu为得到的用户画像数据隐藏向量,因为不需要进行融合转换,因此不再嵌套内层的公式。
57、因为本发明采用上述技术方案,因此具备以下有益效果:
58、1、采用本发明步骤1的技术手段,“频率弱化”的方式使得用户的数据被规范化,能够减少熵值过大的文本对模型训练的影响。多源数据融合中的“频率弱化”和多重解码方案。频率弱化使得问卷和用户操作中随机性较高的数据被简化、归类化,从而减少噪声对最终结果的影响。多重解码方案使得生成的数据能够先将文本中的内部关联挖掘出来,然后再根据模板内容挖掘关键词,使结果更精准。
59、2、采用本发明步骤1-3的技术手段,使用roberta和xlnet分别对用户固有画像和商品信息编码,在预训练模型存在的情况下进行,gpt3将特征信息转化、生成三分类标签向量。将三种不同类型的信息使用彼此相异的编码器进行编码可以避免语义信息趋同。
60、3、采用本发明步骤4的技术手段,信息融合使用多种不同的方法,比如直接组合、相加、相乘、加权相加方法,尽最大可能捕捉融合后的信息。
61、4、采用本发明步骤5-6的技术手段,解码过程使用两种不同形式的解码器组合,能够兼顾全局语义信息和本地语义信息。
62、5、采用本发明步骤7的技术手段,模板匹配对应于关键词与模板之间缺失词的映射关系,用于使语言通顺。
63、6、当前的技术融合了不同的数据特征,尽最大可能减少随机性,并能够使用多重解码有效提升回复的通顺程度和准确性。数据特征化之后的类别更容易被自然语言处理相关的编码器识别出来。在防止了更为杂乱的原始数据对结果产生影响的情况下,完成了多编码信息融合,这是之前的方法中欠考虑的。此外,多解码器的思路也是同时提升准确率和流畅程度的解决方案,这个是之前方案不具备的。
- 还没有人留言评论。精彩留言会获得点赞!